Linuxのcutコマンドは、ファイルの各行からセクションを切り出し、結果を標準出力に書き出すコマンドです。バイト位置、文字、フィールドごとに行の一部を切り取るために使用できます。 Cut コマンドは行をスライスしてテキストを抽出します。コマンドでオプションを指定する必要があります。指定しないとエラーになります。複数のファイル名が指定された場合、各ファイルのデータの前にそのファイル名は付きません。
目次
- Cutコマンドの構文
- Cut コマンドで使用可能なオプション
- Cutコマンドの実践例
- Cut コマンドを使用した特定のバイトの抽出 (-b)
- 文字ごとにカット (-c) Cut コマンドを使用する
- フィールドごとにカット (-f) Cut コマンドを使用する
- Cut コマンドを使用した補数出力 (-complement)
- 出力デリミタ (-output-delimiter) Cut コマンドを使用する
- バージョンの表示 (-version) Cut コマンドを使用した場合
- Cutコマンドでパイプ(|)を付けたtailを使用する方法
- Linux の Cut コマンドに関するよくある質問 – FAQ
Cutコマンドの構文
基本的な構文は、cut>コマンドは次のとおりです。
cut OPTION... [FILE]...>
どこ
`OPTION`> 望ましい動作を指定します
` FILE> `>は入力ファイルを表します。
注記 : もしFILE>指定されていない場合、` cut`> 標準入力 (stdin) から読み取ります。
Cut コマンドで使用可能なオプション
以下は、` を使用して最も一般的に使用されるオプションのリストです。 cut`> 指示:
| オプション | 説明 |
|---|---|
| -b、-bytes=リスト | で指定されたバイトのみを選択します |
| -c、-文字=リスト | で指定された文字のみを選択します |
| -d、-delimiter=DIVIDE | 用途 |
| -f、-フィールド=LIS | で指定されたフィールドのみを選択します |
| -n | マルチバイト文字を分割しないでください(そうでない場合は効果がありません) |
| -補体 | フィールド/文字の選択を反転します。選択されていないフィールド/文字を印刷します。 |
Cutコマンドの実践例
名前を持つ 2 つのファイルを考えてみましょう。 状態.txt そして 資本金.txt インドの州と首都の名前がそれぞれ 5 つ含まれています。
$ cat state.txt Andhra Pradesh Arunachal Pradesh Assam Bihar Chhattisgarh>
オプションを指定しないとエラーが表示されます。
$ cut state.txt cut: you must specify a list of bytes, characters, or fields Try 'cut --help' for more information.>
特定のバイトを抽出 (-b>)cutコマンドを使用する
-b(バイト): 特定のバイトを抽出するには、-b オプションの後にカンマで区切られたバイト番号のリストを指定する必要があります。ハイフン(-)を使用してバイト範囲を指定することもできます。バイト番号のリストを指定する必要があります。指定しないとエラーが発生します。
タブとバックスペース 1バイトの文字として扱われます。
範囲なしのリスト :
cut -b 1,2,3 state.txt>
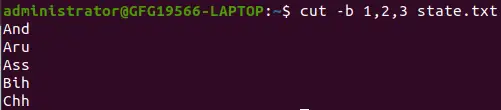
範囲のないリスト
範囲付きのリスト:
cut -b 1-3,5-7 state.txt>
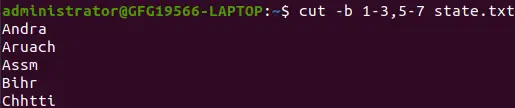
範囲付きリスト
行の先頭から末尾までのバイトを選択するために特別な形式を使用します。
特別な形式: 行の先頭から末尾までのバイトを選択します
ここで、1-は行の1バイト目から最終バイトまでを示します。
cut -b 1- state.txt>
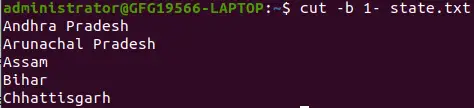
-b オプションを使用した特殊な形式
ここで、-3 は行の 1 バイト目から 3 バイト目までを示します。
cut -b -3 state.txt>
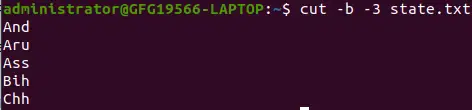
特殊形式 -b オプション
文字ごとにカット (-c>)cutコマンドを使用する
-c (列): 文字ごとに切り取るには、-c オプションを使用します。これにより、-c オプションに指定された文字が選択されます。これは、カンマで区切られた数値のリスト、またはハイフン (-) で区切られた数値の範囲です。
タブとバックスペース キャラクターとして扱われます。文字番号のリストを指定する必要があります。指定しないと、このオプションでエラーが発生します。
構文:
cut -c [(k)-(n)/(k),(n)/(n)] filename>
ここ、 k は文字の開始位置を示し、 n は、各行の文字の終了位置を示します。 k そして n - で区切られている場合、それらは入力として取得されるファイルの各行の文字の位置にすぎません。
特定の文字を抽出します。
cut -c 2,5,7 state.txt>
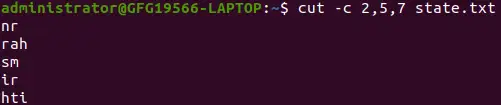
特定の文字を抽出する
上記の Cut コマンドは、ファイルの各行の 2 番目、5 番目、および 7 番目の文字を出力します。
最初の 7 文字を抽出します。
cut -c 1-7 state.txt>
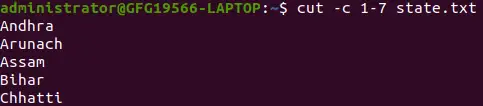
最初の 7 文字を抽出する
上記の Cut コマンドは、ファイルの各行の最初の 7 文字を出力します。 Cut は、行の先頭から末尾までの文字を選択するために特別な形式を使用します。
特殊な形式: 行頭から行末までの文字を選択する
cut -c 1- state.txt>
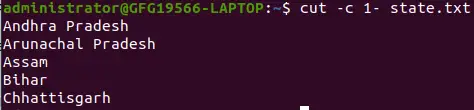
-c オプションを使用して行の先頭から末尾までの文字を選択する
上記のコマンドは、最初の文字から最後まで出力します。ここのコマンドでは開始位置のみが指定されており、終了位置は省略されています。
cut -c -5 state.txt>
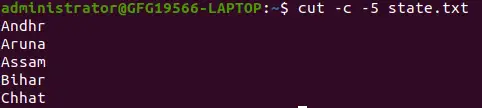
-c オプションを使用して行の先頭から末尾までの文字を選択する
上記のコマンドは開始位置を 5 文字目まで出力します。ここでは開始位置を省略し、終了位置を指定します。
フィールドごとにカット (-f>)cutコマンドを使用する
-f (フィールド): -c このオプションは、固定長の行に便利です。ほとんどの UNIX ファイルには固定長の行がありません。有用な情報を抽出するには、列ではなくフィールドごとに切り取る必要があります。指定するフィールド番号のリストはカンマで区切る必要があります。 -f オプションでは範囲が記述されていません 。 カット 用途 タブ デフォルトのフィールド区切り文字として使用されますが、次を使用して他の区切り文字と併用することもできます。 -d オプション。
注記: UNIX ではスペースは区切り文字として考慮されません。
構文:
cut -d 'delimiter' -f (field number) file.txt>
最初のフィールドを抽出します:
ファイルのように 状態.txt -d オプションを使用しない場合、フィールドはスペースで区切られ、行全体が出力されます。
cut -f 1 state.txt>
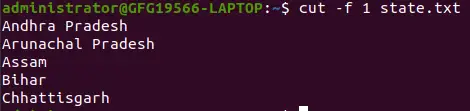
-f オプションを使用して最初のフィールドを抽出する
`の場合 -d` オプションが使用されると、スペースがフィールドの区切り文字または区切り文字として考慮されます。
cut -d ' ' -f 1 state.txt>
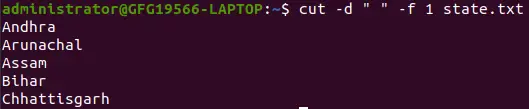
フィールド区切り文字または区切り文字としてのスペース
フィールド 1 ~ 4 を抽出します。
コマンドは、ファイルの各行の最初から 4 番目までのフィールドを出力します。
cut -d ' ' -f 1-4 state.txt>

コマンドはフィールドを 1 番目から 4 番目まで出力します
補数出力 (--complement>)cutコマンドを使用する
-補体: 名前が示すように、出力を補完します。このオプションは、他のオプションと組み合わせて使用できます。 -f または一緒に -c 。
cut --complement -d ' ' -f 1 state.txt>

-補体
cut --complement -c 5 state.txt>

-補体
出力区切り文字 (--output-delimiter>)cutコマンドを使用する
–出力区切り文字: デフォルトでは、出力区切り文字は、カットで指定した入力区切り文字と同じです。 -d オプション。出力区切り文字を変更するには、オプションを使用します –出力デリミタ=デリミタ 。
cut -d ' ' -f 1,2 state.txt --output-delimiter='%'>

ここでcutコマンドは、-fオプションで指定したフィールド間の標準出力の区切り文字(%)を変更します。
表示バージョン (--version>)cutコマンドを使用する
-バージョン: このオプションは、システム上で現在実行されている Cut のバージョンを表示するために使用されます。
cut --version>

Cut コマンドの表示バージョン
Cutコマンドでパイプ(|)を付けたtailを使用する方法
Cut コマンドは、UNIX の他の多くのコマンドとパイプ接続できます。次の出力例では、 猫 コマンドはへの入力として与えられます カット とのコマンド -f ファイル state.txt からの州名を逆順に並べ替えるオプション。
cat state.txt | cut -d ' ' -f 1 | sort -r>

Cut コマンドで末尾にパイプ (|) を使用する
追加の処理のために 1 つ以上のフィルターとパイプすることもできます。次の例のように、cat、head、cut コマンドを使用しており、その出力は directive(>) を使用してファイル名 list.txt に保存されます。
cat state.txt | head -n 3 | cut -d ' ' -f 1>リスト.txt>>出力を別のファイルにリダイレクトする
Linux の Cut コマンドに関するよくある質問 – FAQ
どうやって使うのですか
cut>ファイルから特定の列を抽出するコマンド?例: ` という名前の CSV ファイルから 1 列目と 3 列目を抽出するには
data.csv`>。cut -d',' -f1,3 data.csv>使ってもいいですか
cut>各行から一定範囲の文字を抽出するには?はい、できます。という名前のファイルの各行から文字 5 ~ 10 を抽出するには
text.txt>。cut -c5-10 text.txt>で使用される区切り文字を変更するにはどうすればよいですか?
cut>指示?`を使用します
-d`>オプションの後に区切り文字を続けます。たとえば、コロン (:>)を区切り文字として使用します。cut -d':' -f1,3 data.txt>使用できますか
cut>文字の位置に基づいてフィールドを抽出するには?はい、` を使用して文字の位置を指定できます。
-c`>オプション。たとえば、各行から 1 ~ 5 文字と 10 ~ 15 文字を抽出します。cut -c1-5,10-15 data.txt>使い方
cut>特定の区切り文字に基づいてフィールドを抽出し、新しいファイルに保存するには?カンマで区切られたフィールドを抽出し、` という名前の新しいファイルに保存するには
output.tx>t`>出力.txt>> 結論
この記事では、 `
cut`>Linux のコマンド。バイト位置、文字、またはフィールドに基づいてファイルから特定のセクションを抽出するための多用途ツールです。テキストの行をスライスし、抽出されたデータを出力します。でオプションを指定できませんでしたcut>コマンドはエラーになります。複数のファイルを処理できますが、出力にはファイル名は含まれません。 ` などのオプション-b`>、 `-c`>、および`-f`>それぞれバイト、文字、フィールドによる抽出が可能です。の--complement>オプションは選択を反転し、選択されていないものを印刷します。--output-delimiter>出力区切り文字を変更します。このコマンドにはバージョン表示のオプションも含まれており、追加の処理のためにパイプを介して他のコマンドと組み合わせて使用できます。?list=PLqM7alHXFySFc4KtwEZTANgmyJm3NqS_L
