マルチプロセッサ に分類されます 三つ 共有メモリモデルのタイプ: UMA (Uniform Memory Access)、NUMA (Non-Uniform Memory Access)、および COMA (Cache-only Memory Access) 。モデルは、メモリとハードウェア リソースの割り当て方法に基づいて異なります。 UMA モデルでは、物理メモリがプロセッサ間で均一に共有され、各メモリ ワードのレイテンシも同じになります。対照的に、NUMA では、CPU がメモリにアクセスする際のアクセス時間が可変になります。
この記事では、 1つ そして で 。ただし、違いについて説明する前に、UMA と NUMA について知っておく必要があります。
junit テストケース
UMAとは何ですか?
1つ の略語です 「均一なメモリアクセス」 。これは、マルチプロセッサ共有メモリ アーキテクチャです。このモデルでは、マルチプロセッサ システム内のすべてのプロセッサが相互接続ネットワークを利用して同じメモリを使用し、同じメモリにアクセスします。
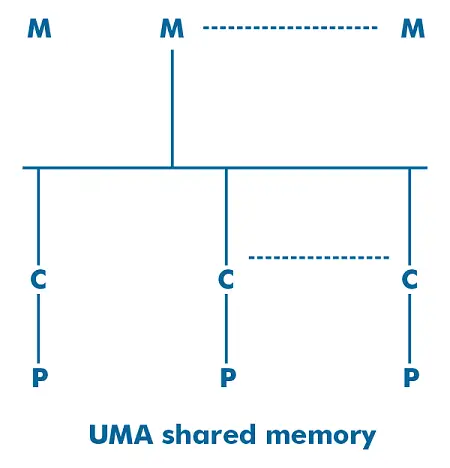
それぞれのレイテンシとアクセス速度 CPU 同じです。それは、 クロスバー スイッチ、単一バス スイッチ、または複数バス スイッチ 。とも呼ばれます SMP (対称型マルチプロセッサ) これは、バランスのとれた共有メモリ アクセスを提供するためです。タイムシェアリングおよび汎用アプリケーションに適しています。
NUMAとは何ですか?
で の略語です 「不均一なメモリアクセス」 。各CPUに専用メモリを搭載したマルチプロセッサモデルでもあります。ただし、これらの小さなメモリ コンポーネントが集まって 1 つのアドレス空間を形成します。メモリ アクセス時間は CPU とメモリ間の距離によって決定されるため、メモリ アクセス時間は異なります。物理アドレスを使用して任意のメモリ場所へのアクセスを提供します。

の NUMA アーキテクチャ は、複数のメモリ コントローラを利用して、利用可能なメモリ帯域幅を最大化するように設計されています。多くのマシンコアを統合します。 「ノード」 、各コアには独自のメモリ コントローラーがあります。で で システムでは、コアはノードによってメモリ コントローラーによって処理されるメモリを受け取り、ローカル メモリにアクセスします。コアは相互接続リンクを介してメモリ要求を送信し、他のメモリ コントローラが処理する遠隔メモリにアクセスします。 NUMA アーキテクチャは、階層型およびツリー バス ネットワークを採用してメモリ ブロックと CPU を接続します。 NUMA アーキテクチャの例をいくつか示します。 BBN、SGI Origin 3000、TC-2000、および Cray 。
UMA と NUMA の主な違い

両者の間にはさまざまな重要な違いがあります。 1つ そして で 。 UMA と NUMA の主な違いのいくつかは次のとおりです。
- UMA (Uniform Memory Access) には、単一のメモリ コントローラーが含まれています。対照的に、NUMA (Non-Uniform Memory Access) は、メモリにアクセスするために複数のメモリ コントローラを利用する場合があります。
- UMA の各 CPU のメモリ アクセス時間は同じです。対照的に、NUMA でのメモリ アクセス時間は、CPU からメモリまでの距離に応じて変化します。
- UMA は、さまざまな汎用アプリやタイムシェアリング アプリで利用されています。一方、NUMA はリアルタイムおよびタイムクリティカルなアプリで採用されています。
- UMA アーキテクチャでは、単一バス、複数バス、およびクロスバー バスが使用されます。一方、NUMA は階層的およびツリー構造のバスとネットワーク接続を採用します。
- 帯域幅に関しては、UMA アーキテクチャの帯域幅は限られています。一方、NUMA は UMA よりも高い帯域幅を備えています。
- UMA のメモリアクセスは遅いです。一方、NUMA メモリ アクセスは UMA メモリ アクセスよりも高速です。
UMA と NUMA の直接比較
ここでは、UMA と NUMA の直接比較について学びます。 UMA と NUMA の主な違いは次のとおりです。
1/1000
| 特徴 | 1つ | で |
|---|---|---|
| 完全形 | UMAはUniform Memory Accessの略称です。 | NUMA は Non-Uniform Memory Access の略称です。 |
| メモリコントローラー | 単一のメモリ コントローラーが含まれています。 | いくつかのメモリ コントローラーが含まれています。 |
| メモリアクセス時間 | バランスの取れた、または同等のメモリ アクセス時間が含まれます。 | メモリアクセス時間はマイクロプロセッサの距離に応じて変化します。 |
| メモリアクセス | メモリアクセスが遅いです。 | メモリアクセスが高速になります。 |
| 適合性 | 主にタイムシェアリングや汎用アプリケーションで利用されます。 | これは主に、タイムクリティカルなリアルタイム アプリで利用されます。 |
| 帯域幅 | 帯域幅が限られています。 | より多くの帯域幅があります。 |
| バスの種類 | シングルバス、マルチバス、クロスバーバスを採用しています。 | 階層型およびツリー構造のバスとネットワーク接続を採用しています。 |
結論
UMA アーキテクチャは、メモリにアクセスするプロセッサに対して同じ全体的な遅延を提供しますが、遅延が均一になるため、ローカル メモリにアクセスする場合には特に役に立ちません。対照的に、NUMA では、各プロセッサが独自の専用メモリを備えているため、ローカル メモリにアクセスする際の遅延が解消されます。レイテンシの変化は、CPU とメモリ間の距離の変化によって異なります。ただし、UMA 設計と比較して、NUMA はパフォーマンスが向上しています。