この SQL 記事では、SQL データベースのクエリで IN キーワードを使用する方法を学習します。
SQLのINキーワードとは何ですか?
の で は、データベース ユーザーが WHERE 句で複数の値を定義できるようにする構造化照会言語の論理演算子です。
IN 演算子を使用した WHERE 句は、指定された値のセットと一致する結果内のレコードを表示します。 IN 演算子の括弧内にサブクエリを指定することもできます。
IN 演算子は、SQL データベースの INSERT、SELECT、UPDATE、および DELETE クエリで使用できます。
SQL の IN 演算子は、クエリ内の複数の OR 条件の処理を置き換えます。
IN 演算子の構文:
SELECT Column_Name_1, Column_Name_2, Column_Name_3, ......, Column_Name_N FROM Table_Name WHERE Column_Name IN (Value_1, Value_2, Value_3, ......., Value_N);
SQL ステートメントで IN 演算子を使用する場合は、以下に示す手順を同じ順序で実行する必要があります。
- SQLでデータベースを作成します。
- 新しい SQL テーブルを作成します。
- テーブルにデータを挿入します。
- 挿入されたデータを表示します。
- SQL IN 演算子を使用してテーブルのデータを表示します。
ここで、最良の SQL 例を使用して、各ステップを 1 つずつ簡単に説明します。
ステップ 1: 単純な新しいデータベースを作成する
最初のステップは、構造化照会言語で新しいデータベースを作成することです。
次の CREATE ステートメントは、新しい 機械大学 SQLサーバーのデータベース:
CREATE Database Mechanical_College;
ステップ 2: 新しいテーブルを作成する
ここで、データベース内に新しいテーブルを作成するのに役立つ次の SQL 構文を使用します。
CREATE TABLE table_name ( 1st_Column data type (character_size of 1st Column), 2nd_Column data type (character_size of the 2nd column ), 3rd_Column data type (character_size of the 3rd column), ...
Nth_Column data type (character_size of the Nth column) );
次の CREATE ステートメントは、 教員紹介 のテーブル 機械大学 データベース:
CREATE TABLE Faculty_Info ( Faculty_ID INT NOT NULL PRIMARY KEY, Faculty_First_Name VARCHAR (100), Faculty_Last_Name VARCHAR (100), Faculty_Dept_Id INT NOT NULL, Faculty_Joining_DateDATE, Faculty_City Varchar (80), Faculty_Salary INT );
ステップ 3: データをテーブルに挿入する
次の INSERT クエリは、Faculties_Info テーブルに Faculties のレコードを挿入します。
INSERT INTO Faculty_Info (Faculty_ID, Faculty_First_Name, Faculty_Last_NameFaculty_Dept_Id, Faculty_Joining_Date, Faculty_City, Faculty_Salary) VALUES (1001, Arush, Sharma, 4001, 2020-01-02, Delhi, 20000); INSERT INTO Faculty_Info (Faculty_ID, Faculty_First_Name, Faculty_Last_NameFaculty_Dept_Id, Faculty_Joining_Date, Faculty_City, Faculty_Salary) VALUES (1002, Bulbul, Roy, 4002, 2019-12-31, Delhi, 38000 ); INSERT INTO Faculty_Info (Faculty_ID, Faculty_First_Name, Faculty_Last_NameFaculty_Dept_Id, Faculty_Joining_Date, Faculty_City, Faculty_Salary) VALUES (1004, Saurabh, Sharma, 4001, 2020-10-10, Mumbai, 45000); INSERT INTO Faculty_Info (Faculty_ID, Faculty_First_Name, Faculty_Last_NameFaculty_Dept_Id, Faculty_Joining_Date, Faculty_City, Faculty_Salary) VALUES (1005, Shivani, Singhania, 4001, 2019-07-15, Kolkata, 42000); INSERT INTO Faculty_Info (Faculty_ID, Faculty_First_Name, Faculty_Last_NameFaculty_Dept_Id, Faculty_Joining_Date, Faculty_City, Faculty_Salary) VALUES (1006, Avinash, Sharma, 4002, 2019-11-11, Delhi, 28000); INSERT INTO Faculty_Info (Faculty_ID, Faculty_First_Name, Faculty_Last_NameFaculty_Dept_Id, Faculty_Joining_Date, Faculty_City, Faculty_Salary)VALUES (1007, Shyam, Besas, 4003, 2021-06-21, Lucknow, 35000);
ステップ 4: 挿入されたデータを表示する
次の SELECT ステートメントは、Faculty_Info テーブルのデータを表示します。
SELECT * FROM Faculty_Info;
| 教員ID | 教員名 | 教員の姓 | 学部_学科_Id | 教員入社日 | 学部_都市 | 教員_給与 |
|---|---|---|---|---|---|---|
| 1001 | クマ | シャルマ | 4001 | 2020-01-02 | デリー | 20000 |
| 1002 | ヒヨドリ | ロイ | 4002 | 2019-12-31 | デリー | 38000 |
| 1004 | サウラブ | ロイ | 4001 | 2020-10-10 | ムンバイ | 45000 |
| 1005 | シヴァニ | シンガニア | 4001 | 2019-07-15 | コルカタ | 42000 |
| 1006 | アビナシュ | シャルマ | 4002 | 2019-11-11 | デリー | 28000 |
| 1007 | シャム | キスをして | 4003 | 2021-06-21 | ラクナウ | 35000 |
ステップ 5: IN 演算子を使用して、Faculty_Info テーブルのデータをさまざまな方法で表示する
次のクエリでは、IN 演算子を使用して数値を使用します。
SELECT Faculty_Id, Faculty_First_Name, Faculty_Dept_Id, Faculty_Joining_Date, Faculty_Salary FROM Faculty_Info WHERE Faculty_Salary IN ( 38000, 42000, 45000, 35000);
このクエリは、WHERE 句の IN 演算子で給与が渡される学部のレコードのみを表示します。
出力:
| 教員ID | 教員名 | 学部_学科_Id | 教員入社日 | 教員_給与 |
|---|---|---|---|---|
| 1002 | ヒヨドリ | 4002 | 2019-12-31 | 38000 |
| 1004 | サウラブ | 4001 | 2020-10-10 | 45000 |
| 1005 | シヴァニ | 4001 | 2019-07-15 | 42000 |
| 1007 | シャム | 4003 | 2021-06-21 | 35000 |
次のクエリでは、IN 論理演算子を使用してテキストまたは文字値を使用します。
SELECT Faculty_Id, Faculty_First_Name, Faculty_Joining_Date, Faculty_City FROM Faculty_Info WHERE Faculty_City IN ( Mumbai, Kolkata, Lucknow);
このクエリは、WHERE 句の IN 演算子の括弧内に都市が含まれる学部のレコードのみを表示します。
出力:
| 教員ID | 教員名 | 教員入社日 | 学部_都市 |
|---|---|---|---|
| 1004 | サウラブ | 2020-10-10 | ムンバイ |
| 1005 | シヴァニ | 2019-07-15 | コルカタ |
| 1007 | シャム | 2021-06-21 | ラクナウ |
次のクエリでは、DATEformat と IN 論理演算子を使用します。
SELECT Faculty_Id, Faculty_First_Name, Faculty_Dept_ID Faculty_Joining_Date, Faculty_Salary FROM Faculty_Info WHERE Faculty_Joining_Date IN (2020-01-02, 2021-06-21, 2020-10-10, 2019-07-15);
このクエリは、入社日が WHERE 句の IN 演算子で渡された学部のレコードのみを表示します。
出力:
| 教員ID | 教員名 | 学部_学科_Id | 教員入社日 | 教員_給与 |
|---|---|---|---|---|
| 1001 | クマ | 4001 | 2020-01-02 | 20000 |
| 1004 | サウラブ | 4001 | 2020-10-10 | 45000 |
| 1005 | シヴァニ | 4001 | 2019-07-15 | 42000 |
| 1007 | シャム | 4003 | 2021-06-21 | 35000 |
次のクエリでは、SQL UPDATE コマンドと IN 論理演算子を使用します。
npmインストールコマンド
UPDATE Faculty_Info SET Faculty_Salary = 50000 WHERE Faculty_Dept_ID IN (4002, 4003);
このクエリは、Dept_Id が WHERE 句の IN 演算子で渡される学部の給与を更新します。
上記のクエリの結果を確認するには、SQL で次の SELECT クエリを入力します。
SELECT * FROM Faculty_Info;
| 教員ID | 教員名 | 教員の姓 | 学部_学科_Id | 教員入社日 | 学部_都市 | 教員_給与 |
|---|---|---|---|---|---|---|
| 1001 | クマ | シャルマ | 4001 | 2020-01-02 | デリー | 20000 |
| 1002 | ヒヨドリ | ロイ | 4002 | 2019-12-31 | デリー | 50000 |
| 1004 | サウラブ | ロイ | 4001 | 2020-10-10 | ムンバイ | 45000 |
| 1005 | シヴァニ | シンガニア | 4001 | 2019-07-15 | コルカタ | 42000 |
| 1006 | アビナシュ | シャルマ | 4002 | 2019-11-11 | デリー | 50000 |
| 1007 | シャム | キスをして | 4003 | 2021-06-21 | ラクナウ | 50000 |
サブクエリを使用した SQL IN 演算子
構造化照会言語では、IN 論理演算子を使用してサブクエリを使用することもできます。
サブクエリを使用した IN 演算子の構文は次のとおりです。
SELECT Column_Name_1, Column_Name_2, Column_Name_3, ......, Column_Name_N FROM Table_Name WHERE Column_Name IN (Subquery);
サブクエリを使用した IN 演算子を理解したい場合は、CREATE ステートメントを使用して構造化クエリ言語で 2 つの異なるテーブルを作成する必要があります。
次のクエリは、データベースに Faculty_Info テーブルを作成します。
CREATE TABLE Faculty_Info ( Faculty_ID INT NOT NULL PRIMARY KEY, Faculty_First_Name VARCHAR (100), Faculty_Last_Name VARCHAR (100), Faculty_Dept_Id INT NOT NULL, Faculty_Address Varchar (80), Faculty_City Varchar (80), Faculty_Salary INT );
次のクエリは、 部門情報 データベース内のテーブル:
CREATE TABLE Department_Info ( Dept_Id INT NOT NULL, Dept_Name Varchar(100), Head_Id INT );
次の INSERT クエリは、Faculties_Info テーブルに Faculties のレコードを挿入します。
INSERT INTO Faculty_Info (Faculty_ID, Faculty_First_Name, Faculty_Last_NameFaculty_Dept_Id, Faculty_Address, Faculty_City, Faculty_Salary) VALUES (1001, Arush, Sharma, 4001, 22 street, New Delhi, 20000); INSERT INTO Faculty_Info (Faculty_ID, Faculty_First_Name, Faculty_Last_NameFaculty_Dept_Id, Faculty_Address, Faculty_City, Faculty_Salary) VALUES (1002, Bulbul, Roy, 4002, 120 street, New Delhi, 38000 ); INSERT INTO Faculty_Info (Faculty_ID, Faculty_First_Name, Faculty_Last_NameFaculty_Dept_Id, Faculty_Address, Faculty_City, Faculty_Salary) VALUES (1004, Saurabh, Sharma, 4001, 221 street, Mumbai, 45000); INSERT INTO Faculty_Info (Faculty_ID, Faculty_First_Name, Faculty_Last_NameFaculty_Dept_Id, Faculty_Address, Faculty_City, Faculty_Salary) VALUES (1005, Shivani, Singhania, 4001, 501 street, Kolkata, 42000);
次の INSERT クエリは、Department_Info テーブルに部門のレコードを挿入します。
INSERT INTO Department_Info (Dept_ID, Dept_Name, Head_Id) VALUES ( 4001, Arun, 1005); INSERT INTO Department_Info (Dept_ID, Dept_Name, Head_Id) VALUES ( 4002, Zayant, 1009); INSERT INTO Department_Info (Dept_ID, Dept_Name, Head_Id) VALUES ( 4003, Manish, 1007);
次の SELECT ステートメントは、Faculty_Info テーブルのデータを表示します。
SELECT * FROM Faculty_Info;
| 教員ID | 教員名 | 教員の姓 | 学部_学科_Id | 教員の住所 | 学部_都市 | 教員_給与 |
|---|---|---|---|---|---|---|
| 1001 | クマ | シャルマ | 4001 | 22 ストリート | ニューデリー | 20000 |
| 1002 | ヒヨドリ | ロイ | 4002 | 120 ストリート | ニューデリー | 38000 |
| 1004 | サウラブ | ロイ | 4001 | 221 ストリート | ムンバイ | 45000 |
| 1005 | シヴァニ | シンガニア | 4001 | 501 ストリート | コルカタ | 42000 |
| 1006 | アビナシュ | シャルマ | 4002 | 12 ストリート | デリー | 28000 |
| 1007 | シャム | キスをして | 4003 | 202 ストリート | ラクナウ | 35000 |
次のクエリは、Department_Info テーブルから部門のレコードを表示します。
SELECT * FROM Department_Info;
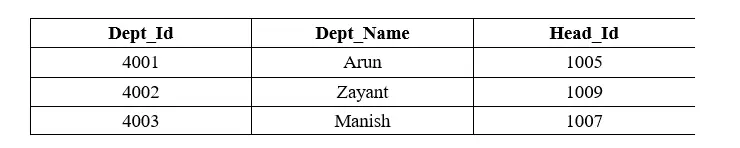
次のクエリでは、サブクエリで IN 演算子を使用します。
SELECT * FROM Faculty_Info WHERE Faculty_Dept_Id IN ( Select Dept_Id FROM Department_Info WHERE Head_Id >= 1007);
このクエリは、Faculty_Info テーブルの Dept_ID がDepartment_Info テーブルの Dept_Id と一致する学部のレコードを表示します。
出力:
| 教員ID | 教員名 | 教員の姓 | 学部_ID | 教員の住所 | 学部_都市 | 教員_給与 |
|---|---|---|---|---|---|---|
| 1002 | ヒヨドリ | ロイ | 4002 | 120 ストリート | ニューデリー | 38000 |
| 1006 | アビナシュ | シャルマ | 4002 | 12 ストリート | デリー | 28000 |
| 1007 | シャム | キスをして | 4003 | 202 ストリート | ラクナウ | 35000 |
SQL に IN がないものは何ですか?
NOT IN は構造化照会言語のもう 1 つの演算子で、SQL IN 演算子のちょうど反対です。これにより、IN 演算子の括弧を渡さずにテーブルからこれらの値にアクセスできるようになります。
NOT IN 演算子は、INSERT、UPDATE、SELECT、および DELETE SQL クエリで使用できます。
NOT IN 演算子の構文:
SELECT Column_Name_1, Column_Name_2, Column_Name_3, ......, Column_Name_N FROM Table_Name WHERE Column_Name NOT IN (Value_1, Value_2, Value_3, ......., Value_N);
SQL ステートメントで NOT IN 演算子を使用する場合は、指定された手順を同じ順序で実行する必要があります。
- SQL システムにデータベースを作成します。
- データベースに新しいテーブルを作成します。
- テーブルにデータを挿入する
- 挿入されたデータを表示する
- データを表示するには、NOT IN 演算子を使用します。
ここで、最良の SQL 例を使用して、各ステップを 1 つずつ簡単に説明します。
ステップ 1: シンプルな新しいデータベースを作成する
次のクエリでは、新しい 民生_産業 SQLサーバーのデータベース:
CREATE Database Industry;
ステップ 2: 新しいテーブルを作成する
次のクエリは、 労働者情報 のテーブル 民生_産業 データベース:
CREATE TABLE Worker_Info ( Worker_ID INT NOT NULL PRIMARY KEY, Worker_Name VARCHAR (100), Worker_Gender Varchar(20), Worker_Age INT NOT NULL DEFAULT 18, Worker_Address Varchar (80), Worker_Salary INT NOT NULL );
ステップ 3: 値を挿入する
次の INSERT クエリは、Worker_Info テーブルにワーカーのレコードを挿入します。
INSERT INTO Worker_Info (Worker_ID, Worker_Name, Worker_Gender, Worker_Age, Worker_Address, Worker_Salary) VALUES (1001, Arush, Male, Agra, 35000); INSERT INTO Worker_Info (Worker_ID, Worker_Name, Worker_Gender, Worker_Age, Worker_Address, Worker_Salary) VALUES (1002, Bulbul, Female, Lucknow, 42000); INSERT INTO Worker_Info (Worker_ID, Worker_Name, Worker_Gender, Worker_Age, Worker_Address, Worker_Salary) VALUES (1004, Saurabh, Male, 20, Lucknow, 45000); INSERT INTO Worker_Info (Worker_ID, Worker_Name, Worker_Gender, Worker_Age, Worker_Address, Worker_Salary) VALUES (1005, Shivani, Female, Agra, 28000); INSERT INTO Worker_Info (Worker_ID, Worker_Name, Worker_Gender, Worker_Age, Worker_Address, Worker_Salary) VALUES (1006, Avinash, Male, 22, Delhi, 38000); INSERT INTO Worker_Info (Worker_ID, Worker_Name, Worker_Gender, Worker_Age, Worker_Address, Worker_Salary) VALUES (1007, Shyam, Male, Banglore, 20000);
ステップ 4: テーブルのデータを表示する
次のクエリは、Worker_Info テーブルのデータを表示します。
SELECT * FROM Worker_Info;
| 労働者ID | 従業員名 | 労働者_性別 | 労働者_年齢 | 従業員の住所 | 労働者_給与 |
|---|---|---|---|---|---|
| 1001 | クマ | 男 | 18 | アグラ | 35000 |
| 1002 | ヒヨドリ | 女性 | 18 | ラクナウ | 42000 |
| 1004 | サウラブ | 男 | 二十 | ラクナウ | 45000 |
| 1005 | シヴァニ | 女性 | 18 | アグラ | 28000 |
| 1006 | アビナシュ | 男 | 22 | デリー | 38000 |
| 1007 | シャム | 男 | 18 | バンガロール | 20000 |
ステップ 4: NOT IN 演算子を使用する
次のクエリでは、数値データで NOT IN 演算子を使用します。
SELECT * FROM Worker_Info WHERE Worker_salary NOT IN (35000, 28000, 38000);
この SELECT クエリは、給与が NOT IN 演算子に渡されていないすべての従業員を出力に表示します。
上記のステートメントの結果を次の表に示します。
| 労働者ID | 従業員名 | 労働者_性別 | 労働者_年齢 | 従業員の住所 | 労働者_給与 |
|---|---|---|---|---|---|
| 1002 | ヒヨドリ | 女性 | 18 | ラクナウ | 42000 |
| 1004 | サウラブ | 男 | 二十 | ラクナウ | 45000 |
| 1007 | シャム | 男 | 18 | バンガロール | 20000 |
次のクエリでは、文字またはテキスト値で NOT IN 論理演算子を使用します。
SELECT * FROM Worker_Info WHERE Worker_Address NOT IN (Lucknow, Delhi);
このクエリは、アドレスが NOT IN 演算子で渡されなかったすべてのワーカーのレコードを表示します。
出力:
| 労働者ID | 従業員名 | 労働者_性別 | 労働者_年齢 | 従業員の住所 | 労働者_給与 |
|---|---|---|---|---|---|
| 1001 | クマ | 男 | 18 | アグラ | 35000 |
| 1005 | シヴァニ | 女性 | 18 | アグラ | 28000 |
| 1007 | シャム | 男 | 18 | バンガロール | 20000 |