Linux の uniq コマンドは、ファイルから繰り返される行をすべて削除するために使用されます。また、任意の単語の数を表示したり、繰り返し行のみを表示したり、文字を無視したり、特定のフィールドを比較したりするために使用することもできます。これは、最も頻繁に使用されるコマンドの 1 つです。 Linux システム。と一緒によく使われます ソートコマンド 隣接する文字を比較するためです。同一の行をすべて破棄し、出力を書き込みます。
構文:
uniq [OPTION]... [INPUT [OUTPUT]]
オプション:
uniq コマンドの便利なコマンド ライン オプションのいくつかは次のとおりです。
-c、--カウント: 出現回数を行の先頭に付けます。
-d、--繰り返し: これは、グループごとに 1 行ずつ重複した行を印刷するために使用されます。
-D: すべての重複行を印刷するために使用されます。
--all-repeat[=メソッド]: これは「-D」オプションとよく似ていますが、両方のオプションの違いは、空行でグループを分離できることです。
-f、--skip-fields=N: これは、最初の N フィールドの比較を避けるために使用されます。
--グループ[=メソッド]: すべての項目を表示するために使用され、グループを空行で区切ります。
-i、--ignore-case: 比較中に違いを無視するために使用されます。
-s、--skip-chars=N: 最初の N 文字の比較を避けるために使用されます。
-u、--固有: ユニークなラインを印刷するために使用されます。
-z、--ゼロ終了: これは、行区切り文字が NUL であり、改行モードではない場合に使用されます。
-w、--check-chars=N: N 行以内の文字を比較するために使用されます。
- ヘルプ: ヘルプドキュメントを表示するために使用されます。
- バージョン: バージョン情報を表示するために使用されます。
HTMLからjs関数を呼び出す
uniqコマンドの例
uniq コマンドの次の例を見てみましょう。
繰り返される行を削除する
ファイルから繰り返し行を削除するには、次のように基本的な uniq コマンドを実行します。
sort dupli.txt | uniq
上記のコマンドは、ファイル「dupli.txt」から重複行を削除します。以下の出力を考えてみましょう。
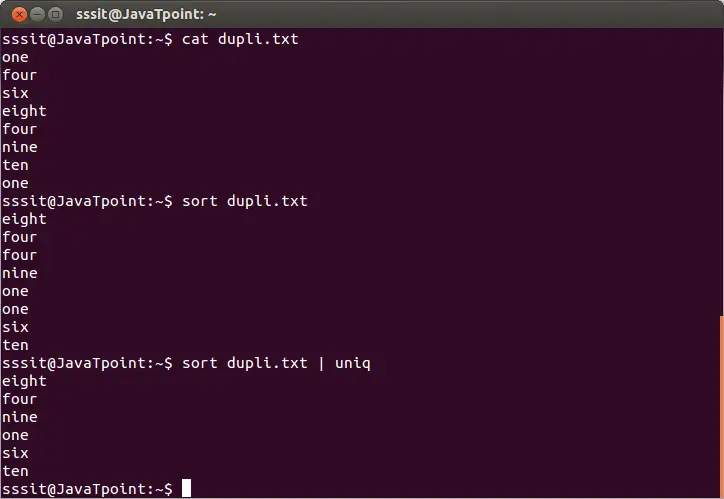
上記の出力から、繰り返される単語は無視されます。
単語の出現数を数える
uniq コマンドを使用すると、単語の出現数をカウントできます。 「-c」オプションは単語をカウントするために使用されます。次のように実行します。
sort dupli.txt | uniq -c
上記のコマンドは、「dupli.txt」に含まれる単語をカウントします。以下の出力を考えてみましょう。

上記の出力から、コマンド 'sort dupli.txt | uniq -c' は、単語が繰り返される回数をカウントします。
繰り返し行を表示する
「-d」オプションは、繰り返される行のみを表示するために使用されます。ファイル内に複数回存在する行のみが表示され、出力が標準出力に書き込まれます。以下のコマンドを考えてみましょう。
sort dupli.txt | uniq -d
上記のコマンドは、繰り返される行のみを表示します。以下の出力を考えてみましょう。

固有の行を表示する
「-u」オプションは、重複しない一意の行のみを表示するために使用されます。 1 回だけ出現する行のみが表示され、結果が標準出力に書き込まれます。以下のコマンドを考えてみましょう。
sort dupli.txt | uniq -u
上記のコマンドは、ファイル「dupli.txt」の一意の行のみを表示します。以下の出力を考えてみましょう。

比較する文字を無視する
「-s」オプションは、比較する文字を無視するために使用されます。指定された文字数は無視され、結果が標準出力に表示されます。以下のコマンドを考えてみましょう。
sort dupli.txt | uniq -s 2
上記のコマンドは、ファイル「dupli.txt」の最初の 2 文字を比較して無視します。以下の出力を考えてみましょう。

比較するフィールドを無視する
「-f」オプションはフィールドを無視するために使用されます。以下のコマンドを考えてみましょう。
uniq -f 2 dupli2.txt
上記のコマンドは、ファイル「dupli2.txt」の最初の 2 つのフィールドを比較しません。以下の出力を考えてみましょう。

上記の出力では、最初の 2 つのフィールドがスキップされ、残りのすべてのフィールドがファイル 'dupli2.txt' から比較されます。