Pandas.apply を使用すると、ユーザーは関数を渡し、それを Pandas シリーズのすべての値に適用できます。この機能は、必要な条件に従ってデータを分離するのに役立ち、データ サイエンスや機械学習で効率的に使用できるため、pandas ライブラリにとっては大幅な改善となります。
インストール:
ターミナルで次のコマンドを使用して、Pandas モジュールを Python ファイルにインポートします。
pip install pandas>
csv ファイルを読み取り、それを pandas シリーズに圧縮するには、次のコマンドを使用します。
import pandas as pd s = pd.read_csv('stock.csv', squeeze=True)> 構文:
123映画
s.apply(func, convert_dtype=True, args=())>
パラメーター:
機能: .apply は関数を受け取り、それを pandas シリーズのすべての値に適用します。 変換dタイプ: 関数の操作に従って dtype を変換します。 引数=(): シリーズの代わりに関数に渡す追加の引数。 戻り値の型: 応用機能・操作後のPandasシリーズ。
例 #1:
次の例では、関数を渡して各要素の値を順番にチェックし、それに応じて low、normal、または High を返します。
Javaのソートリスト
パイソン3
import> pandas as pd> # reading csv> s>=> pd.read_csv('stock.csv', squeeze>=> True>)> # defining function to check price> def> fun(num):> >if> num<>200>:> >return> 'Low'> >elif> num>>>=> 200> and> num<>400>:> >return> 'Normal'> >else>:> >return> 'High'> # passing function to apply and storing returned series in new> new>=> s.>apply>(fun)> # printing first 3 element> print>(new.head(>3>))> # printing elements somewhere near the middle of series> print>(new[>1400>], new[>1500>], new[>1600>])> # printing last 3 elements> print>(new.tail(>3>))> |
>
k 最近隣の人
>
出力:
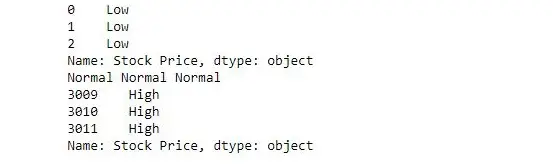
例2:
人工ニューラルネットワーク
次の例では、ラムダを使用して .apply 自体に一時的な匿名関数が作成されます。系列内の各値に 5 を加算し、新しい系列を返します。
パイソン3
import> pandas as pd> s>=> pd.read_csv('stock.csv', squeeze>=> True>)> # adding 5 to each value> new>=> s.>apply>(>lambda> num : num>+> 5>)> # printing first 5 elements of old and new series> print>(s.head(),>'
'>, new.head())> # printing last 5 elements of old and new series> print>(>'
'>, s.tail(),>'
'>, new.tail())> |
シュロカ・メタ教育
>
>
出力:
0 50.12 1 54.10 2 54.65 3 52.38 4 52.95 Name: Stock Price, dtype: float64 0 55.12 1 59.10 2 59.65 3 57.38 4 57.95 Name: Stock Price, dtype: float64 3007 772.88 3008 771.07 3009 773.18 3010 771.61 3011 782.22 Name: Stock Price, dtype: float64 3007 777.88 3008 776.07 3009 778.18 3010 776.61 3011 787.22 Name: Stock Price, dtype: float64>
観察されたとおり、新しい値 = 古い値 + 5