あ ダウンロードマネージャー 基本的には、インターネットからスタンドアロン ファイルをダウンロードするタスク専用のコンピューター プログラムです。ここでは、Python のスレッドを使用して単純なダウンロード マネージャーを作成します。マルチスレッドを使用すると、ファイルを異なるスレッドからチャンクの形式で同時にダウンロードできます。これを実装するには、ファイルの URL を受け取ってダウンロードする簡単なコマンドライン ツールを作成します。
前提条件: Python がインストールされた Windows マシン。
Javaの文字列のlen
設定
コマンドプロンプトから以下のパッケージをダウンロードします。
1. Click パッケージ: Click は、必要最小限のコードで美しいコマンド ライン インターフェイスを作成するための Python パッケージです。それはコマンドラインインターフェイス作成キットです。
pipインストールクリック
2. パッケージのリクエスト: このツールでは、URL (HTTP アドレス) に基づいてファイルをダウンロードします。 Requests は、HTTP リクエストを送信できるようにする Python で書かれた HTTP ライブラリです。データのマルチパート ファイルからヘッダーを追加し、単純な Python ディクショナリを使用してパラメータを追加し、同じ方法で応答データにアクセスできます。
pipインストールリクエスト
3. スレッド化パッケージ: スレッドを使用するには、スレッド化パッケージが必要です。
pip インストール スレッド
実装
文字列比較
注記:
理解しやすいように、プログラムはいくつかの部分に分かれています。プログラムの実行中にコードの一部が欠けていないことを確認してください。
ステップ 1: 必要なパッケージをインポートする
これらのパッケージは、Web リクエストでコマンドライン入力を処理し、スレッドを作成するために必要なツールを提供します。
乱数CコードPython
import click import requests import threading
ステップ 2: ハンドラー関数を作成する
各スレッドはこの関数を実行して、ファイルの特定のチャンクをダウンロードします。この関数は、特定の範囲のバイトのみを要求し、それらをファイル内の正しい位置に書き込む役割を果たします。
Pythondef Handler(start end url filename): headers = {'Range': f'bytes={start}-{end}'} r = requests.get(url headers=headers stream=True) with open(filename 'r+b') as fp: fp.seek(start) fp.write(r.content)
ステップ 3: クリックで Main 関数を定義する
関数をコマンドライン ユーティリティに変換します。これは、ユーザーがコマンド ラインからスクリプトを操作する方法を定義します。
Python#Note: This code will not work on online IDE @click.command(help='Downloads the specified file with given name using multi-threading') @click.option('--number_of_threads' default=4 help='Number of threads to use') @click.option('--name' type=click.Path() help='Name to save the file as (with extension)') @click.argument('url_of_file' type=str) def download_file(url_of_file name number_of_threads):
ステップ 4: ファイル名の設定とファイル サイズの決定
ダウンロードをスレッド間で分割し、サーバーが範囲ダウンロードをサポートしていることを確認するには、ファイル サイズが必要です。
Python r = requests.head(url_of_file) file_name = name if name else url_of_file.split('/')[-1] try: file_size = int(r.headers['Content-Length']) except: print('Invalid URL or missing Content-Length header.') return
ステップ 5: ファイルスペースを事前に割り当てる
事前割り当てにより、チャンクを特定のバイト範囲に書き込む前に、ファイルが正しいサイズであることが保証されます。
Python part = file_size // number_of_threads with open(file_name 'wb') as fp: fp.write(b'�' * file_size)
ステップ 6: スレッドを作成する
スレッドには、並列ダウンロードする特定のバイト範囲が割り当てられます。
Python threads = [] for i in range(number_of_threads): start = part * i end = file_size - 1 if i == number_of_threads - 1 else (start + part - 1) t = threading.Thread(target=Handler kwargs={ 'start': start 'end': end 'url': url_of_file 'filename': file_name }) threads.append(t) t.start()
ステップ 7: スレッドに参加する
プログラムが終了する前にすべてのスレッドが完了するようにします。
Python for t in threads: t.join() print(f'{file_name} downloaded successfully!') if __name__ == '__main__': download_file()
コード:
Pythonimport click import requests import threading def Handler(start end url filename): headers = {'Range': f'bytes={start}-{end}'} r = requests.get(url headers=headers stream=True) with open(filename 'r+b') as fp: fp.seek(start) fp.write(r.content) @click.command(help='Downloads the specified file with given name using multi-threading') @click.option('--number_of_threads' default=4 help='Number of threads to use') @click.option('--name' type=click.Path() help='Name to save the file as (with extension)') @click.argument('url_of_file' type=str) def download_file(url_of_file name number_of_threads): r = requests.head(url_of_file) if name: file_name = name else: file_name = url_of_file.split('/')[-1] try: file_size = int(r.headers['Content-Length']) except: print('Invalid URL or missing Content-Length header.') return part = file_size // number_of_threads with open(file_name 'wb') as fp: fp.write(b'�' * file_size) threads = [] for i in range(number_of_threads): start = part * i # Make sure the last part downloads till the end of file end = file_size - 1 if i == number_of_threads - 1 else (start + part - 1) t = threading.Thread(target=Handler kwargs={ 'start': start 'end': end 'url': url_of_file 'filename': file_name }) threads.append(t) t.start() for t in threads: t.join() print(f'{file_name} downloaded successfully!') if __name__ == '__main__': download_file()
コーディング部分は完了したので、次に示すコマンドに従って .py ファイルを実行します。
python filename.py –-help出力:
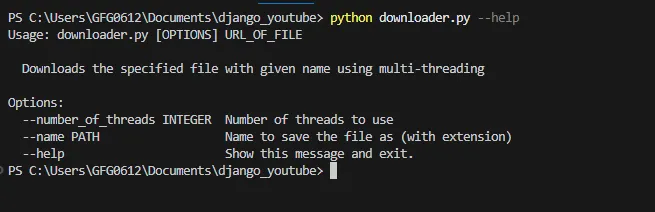 Python ファイル名.py –-ヘルプ
Python ファイル名.py –-ヘルプ
フィボナッチ数列Java
このコマンドは、クリック コマンド ツールの使用法とツールが受け入れることができるオプションを示します。以下は、URL から jpg 画像ファイルをダウンロードし、名前とスレッド数を指定するサンプル コマンドです。
 jpgをダウンロードするサンプルコマンド
jpgをダウンロードするサンプルコマンドすべてが正常に実行されると、以下に示すように、フォルダー ディレクトリにファイル (この場合はflower.webp) が表示されるようになります。
 ディレクトリ
ディレクトリこれは、Python でシンプルなマルチスレッド ダウンロード マネージャーを構築する方法の 1 つです。