SQL の条件式は次のとおりです。
- CASE 式 : プロシージャを呼び出さずに IF-THEN-ELSE ステートメントを使用できます。
-
Input: SELECT GREATEST('XYZ', 'xyz') from dual;>Output: GREATEST('XYZ', 'xyz') xyz>説明: 小さいアルファベットの ASCII 値が大きくなります。
-
Input: SELECT GREATEST('XYZ', null, 'xyz') from dual; Output: GREATEST('XYZ', null, 'xyz') ->説明: null が存在するため、(上記の説明で注意したように) null が出力として表示されます。
-
Input: SELECT IFNULL(1,0) FROM dual;>
Output: - 1>
説明 : したがって、null になる式はありません。
私のモニターのサイズは何ですか
-
Input: SELECT IFNULL(NULL,10) FROM dual; Output: -- 10>
説明: expr1 は null であるため、expr2 が表示されます。
-
strong>入力: SELECT LEAST('XYZ', 'xyz') からデュアル;出力: LEAST('XYZ', 'xyz') XYZ>>'説明: 大文字のアルファベットの ASCII 値は小さくなります。
JavaでCSVファイルから読み取る方法
-
説明: null が存在するため、(上記の説明で注意したように) null が出力として表示されます。
単純な CASE 式では、SQL は expr がcomparison_expr に等しい最初の WHEN……THEN ペアを検索し、return_expr を返します。上記の条件が満たされない場合、ELSE 句が存在し、SQL は else_expr を返します。それ以外の場合は、NULL を返します。
return_expr と else_expr にリテラル null を指定することはできません。すべての式 (expr、comparison_expr、return_expr) は同じデータ型である必要があります。
構文:
CASE expr WHEN comparison_expr1 THEN return_expr1 [ WHEN comparison_expr2 THEN return_expr2 . . . WHEN comparison_exprn THEN return_exprn ELSE else_expr] END>
例:
Input : SELECT first_name, department_id, salary, CASE department_id WHEN 50 THEN 1.5*salary WHEN 12 THEN 2.0*salary ELSE salary END 'REVISED SALARY' FROM Employee;>
出力:
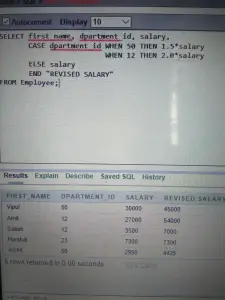
説明 : 上記の SQL ステートメントでは、Department_id の値がデコードされます。 50の場合は給与が1.5倍、12の場合は給与が2倍、それ以外の場合は給与は変わりません。 DECODE 関数 : CASE または IF-THEN-ELSE ステートメントの作業を実行することで、条件付きの問い合わせを容易にします。
DECODE 関数は、さまざまな言語で使用される IF-THEN-ELSE ロジックと同様の方法で式をデコードします。 DECODE 関数は、各検索値と比較した後、式をデコードします。式が検索と同じ場合、結果が返されます。
デフォルト値を省略した場合、検索値が結果値のいずれにも一致しない場合は null 値が返されます。
構文:
DECODE (col/expression, search1, result1 [, search2, result2,........,] [, default])>
Input : SELECT first_name, department_id, salary, DECODE(department_id, 50, 1.5*salary, 12, 2.0*salary, salary) 'REVISED SALARY' FROM Employee;>
出力:

説明: 上記の SQL ステートメントでは、Department_id の値がテストされます。 50の場合は給与が1.5倍、12の場合は給与が2倍、それ以外の場合は給与は変わりません。
注: CASE 式と同様に、COALESCE も、最初に見つかった null 以外の引数の右側の引数を評価しません。
構文:
COALESCE( value [, ......] )>
Input: SELECT COALESCE(last_name, '- NA -') from Employee;>
出力:
説明: - NA - 姓が null の場合は、それぞれの姓が表示されます。 GREATEST: 任意の数の式のリストから最大の値を返します。比較では大文字と小文字が区別されます。リスト内のすべての式のデータ型が同じでない場合、残りのすべての式は比較のために最初の式のデータ型に変換されます。この変換が不可能な場合、SQL はエラーをスローします。
注記: リスト内のいずれかの式が null の場合は、null を返します。
構文:
GREATEST( expr1, expr2 [, .....] )>
構文:
IFNULL( expr1, expr2 )>
注: CASE 式や COALESCE 式と同様に、IN も最初に見つかった null 以外の引数の右側の引数を評価しません。
構文:
WHERE column IN ( x1, x2, x3 [,......] )>
Input: SELECT * from Employee WHERE department_id IN(50, 12);>
出力:
説明: 従業員のすべてのデータは部門 ID 50 または 12 で表示されます。
LEAST: 任意の数の式のリストから最小値を返します。比較では大文字と小文字が区別されます。リスト内のすべての式のデータ型が同じでない場合、残りのすべての式は比較のために最初の式のデータ型に変換されます。この変換が不可能な場合、SQL はエラーをスローします。注: リスト内のいずれかの式が null の場合は、null を返します。
構文:
LEAST( expr1, expr2 [, ......] )>
構文:
NULLIF( value1, value2 )>
例:
Input: SELECT NULLIF(9995463931, contact_num) from Employee;>
出力:

説明: 指定された番号と一致する従業員には NULL が表示されます。残りの従業員については、value1 が返されます。