アンインフォームド検索は、ブルートフォース方式で動作する汎用検索アルゴリズムの一種です。無情報検索アルゴリズムには、ツリーのトラバース方法以外に状態や検索空間に関する追加情報がないため、ブラインド検索とも呼ばれます。
以下に、さまざまなタイプの非情報検索アルゴリズムを示します。
1. 幅優先検索:
- 幅優先検索は、ツリーまたはグラフを走査するための最も一般的な検索戦略です。このアルゴリズムはツリーまたはグラフ内を幅方向に検索するため、幅優先検索と呼ばれます。
- BFS アルゴリズムは、ツリーのルート ノードから検索を開始し、次のレベルのノードに移動する前に、現在のレベルのすべての後続ノードを展開します。
- 幅優先探索アルゴリズムは、一般的なグラフ探索アルゴリズムの一例です。
- FIFO キュー データ構造を使用して実装された幅優先検索。
利点:
- 解決策が存在する場合、BFS は解決策を提供します。
- 特定の問題に対して複数の解決策がある場合、BFS は最小限のステップ数を必要とする最小限の解決策を提供します。
短所:
- 次のレベルを展開するにはツリーの各レベルをメモリに保存する必要があるため、大量のメモリが必要になります。
- ソリューションがルート ノードから遠く離れている場合、BFS には多くの時間がかかります。
例:
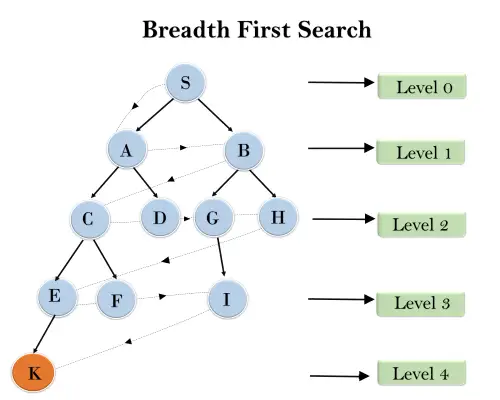
以下のツリー構造では、BFS アルゴリズムを使用してルート ノード S からゴール ノード K までツリーのトラバースを示しています。BFS 検索アルゴリズムはレイヤーをトラバースするため、点線の矢印で示されたパスに従います。通過するパスは次のようになります。
S---> A--->B---->C--->D---->G--->H--->E---->F---->I---->K
時間計算量: BFS アルゴリズムの時間計算量は、BFS で最も浅いノードまで通過するノードの数によって取得できます。ここで、 d = 最も浅い解の深さ、 b は各状態のノードです。
T (b) = 1+b2+b3+....+bd= O (bd)
空間の複雑さ: BFS アルゴリズムの空間計算量は、フロンティアのメモリ サイズによって与えられ、O(bd)。
完全: BFS が完了しました。これは、最も浅いゴール ノードが有限の深さにある場合、BFS が解決策を見つけることを意味します。
最適性: BFS は、パス コストがノードの深さの減少しない関数である場合に最適です。
2. 深さ優先検索
- 深さ優先検索は、ツリーまたはグラフのデータ構造を走査するための再帰的アルゴリズムです。
- これは、ルート ノードから開始し、各パスをその最大の深さのノードまでたどってから次のパスに移動するため、深さ優先検索と呼ばれます。
- DFS は実装にスタック データ構造を使用します。
- DFS アルゴリズムのプロセスは BFS アルゴリズムと似ています。
注: バックトラッキングは、再帰を使用して考えられるすべての解決策を見つけるためのアルゴリズム手法です。
アドバンテージ:
- DFS は、ルート ノードから現在のノードまでのパス上のノードのスタックを保存するだけでよいため、必要なメモリは非常に少なくなります。
- BFS アルゴリズムよりもゴール ノードに到達するのにかかる時間が短くなります (正しいパスを通過した場合)。
不利益:
ディレクトリの名前を変更する Linux
- 多くの状態が再発し続ける可能性があり、解決策が見つかる保証はありません。
- DFS アルゴリズムは徹底的な検索を行うため、場合によっては無限ループに陥る可能性があります。
例:
以下の検索ツリーでは深さ優先検索の流れを示しており、次のような順序になります。
ルートノード ---> 左ノード ----> 右ノード。
ルート ノード S から検索を開始し、A、B、D、E とたどります。E をたどった後、E には他に後続ノードがなく、ゴール ノードが見つからないため、ツリーをバックトラックします。バックトラックした後、ノード C を通過し、次にノード G を通過し、ゴール ノードを見つけたのでここで終了します。

完全: DFS 検索アルゴリズムは、限られた検索ツリー内ですべてのノードを展開するため、有限状態空間内で完了します。
時間計算量: DFS の時間計算量は、アルゴリズムが通過するノードに相当します。それは次のように与えられます。
T(n)= 1+n2+n3+....+nメートル=O(nメートル)
ここで、m = 任意のノードの最大深度であり、これは d (最も浅いソリューションの深さ) よりもはるかに大きくなる可能性があります。
空間の複雑さ: DFS アルゴリズムは、ルート ノードからのパスを 1 つだけ保存する必要があるため、DFS のスペースの複雑さはフリンジ セットのサイズと同等になります。 O(bm) 。
最適な: DFS 検索アルゴリズムは、目標ノードに到達するまでに大量のステップや高コストが発生する可能性があるため、最適ではありません。
3. 深さ制限された検索アルゴリズム:
深さ制限検索アルゴリズムは、事前に制限を設けた深さ優先検索に似ています。深さ制限探索は、深さ優先探索における無限パスの欠点を解決できます。このアルゴリズムでは、深さ制限にあるノードは、それ以上の後続ノードが存在しないものとして扱われます。
深さ制限された検索は、次の 2 つの失敗条件で終了する可能性があります。
- 標準故障値: 問題に解決策がないことを示します。
- カットオフ失敗値: 指定された深さ制限内では問題の解決策が定義されていません。
利点:
深さを制限した検索はメモリ効率が高くなります。
短所:
- 深さ制限された検索には、不完全であるという欠点もあります。
- 問題に複数の解決策がある場合、最適ではない可能性があります。
例:

完全: 解が深さ制限を超えている場合、DLS 検索アルゴリズムは完了します。
時間計算量: DLS アルゴリズムの時間計算量は O(bℓ) 。
空間の複雑さ: DLS アルゴリズムの空間計算量は O (bℓ) 。
最適な: 深さ制限探索は DFS の特殊なケースとみなすことができ、たとえ ℓ>d であっても最適ではありません。
4.均一コスト検索アルゴリズム:
均一コスト検索は、重み付きツリーまたはグラフを走査するために使用される検索アルゴリズムです。このアルゴリズムは、エッジごとに異なるコストが利用可能な場合に機能します。均一コスト検索の主な目的は、累積コストが最も低いゴール ノードへのパスを見つけることです。均一コスト検索では、ルート ノードからのパス コストに従ってノードを拡張します。最適なコストが求められるグラフ/ツリーを解くために使用できます。均一コスト検索アルゴリズムは、優先キューによって実装されます。累積コストが最も低いものに最大の優先順位が与えられます。すべてのエッジのパス コストが同じ場合、均一コスト検索は BFS アルゴリズムと同等です。
利点:
- すべての状態で最小コストのパスが選択されるため、均一コスト検索が最適です。
短所:
LinuxでJavaのバージョンを確認する
- 検索に必要なステップ数は考慮せず、パス コストのみを考慮します。そのため、このアルゴリズムは無限ループに陥る可能性があります。
例:

完全:
解決策があれば UCS が見つけるなど、均一コストの検索が完了します。
時間計算量:
int を文字列 Java にキャストします
C* にしてみましょう は最適解のコストです 、 そして e 目標ノードに近づくための各ステップです。この場合、ステップ数は = C*/ε+1 となります。ここでは、状態 0 から開始して C*/ε まで終了するため、+1 をとりました。
したがって、均一コスト検索の最悪の場合の時間計算量は次のようになります。 O(b1 + [C*/e])/ 。
空間の複雑さ:
同じロジックが空間複雑さについても当てはまります。したがって、均一コスト探索の最悪の場合の空間複雑さは次のようになります。 O(b1 + [C*/e]) 。
最適な:
均一コスト検索は、パス コストが最も低いパスのみを選択するため、常に最適です。
5. 反復深化深さ優先検索:
反復深化アルゴリズムは、DFS アルゴリズムと BFS アルゴリズムを組み合わせたものです。この検索アルゴリズムは、最適な深さの制限を見つけ出し、目標が見つかるまで制限を徐々に増やすことによって実行します。
このアルゴリズムは、特定の「深さ制限」まで深さ優先検索を実行し、目的のノードが見つかるまで反復ごとに深さ制限を増やし続けます。
この検索アルゴリズムは、幅優先検索の高速検索と深さ優先検索のメモリ効率の利点を組み合わせています。
反復検索アルゴリズムは、検索空間が大きく、ゴール ノードの深さが不明な場合に、情報なしの検索に役立ちます。
利点:
- 高速検索とメモリ効率の点で、BFS と DFS 検索アルゴリズムの利点を組み合わせています。
短所:
- IDDFS の主な欠点は、前のフェーズの作業をすべて繰り返すことです。
例:
以下のツリー構造は、反復深化深さ優先探索を示しています。 IDDFS アルゴリズムは、目標ノードが見つからなくなるまでさまざまな反復を実行します。アルゴリズムによって実行される反復は次のように与えられます。

1 回目の反復-----> A
2 回目の反復 ----> A、B、C
3 番目の反復------>A、B、D、E、C、F、G
4 番目の反復------>A、B、D、H、I、E、C、F、K、G
4 回目の反復では、アルゴリズムはゴール ノードを見つけます。
完全:
このアルゴリズムは、分岐係数が有限である場合に完成します。
Linuxの無料のipconfig
時間計算量:
b が分岐係数、深さが d であると仮定すると、最悪の場合の時間計算量は次のようになります。 O(bd) 。
空間の複雑さ:
IDDFS の空間複雑さは次のようになります。 O(bd) 。
最適な:
IDDFS アルゴリズムは、パス コストがノードの深さの減少しない関数である場合に最適です。
6. 双方向検索アルゴリズム:
双方向検索アルゴリズムは、2 つの同時検索を実行します。1 つは前方検索と呼ばれる初期状態からの検索、もう 1 つは後方検索と呼ばれるゴール ノードからの検索で、ゴール ノードを見つけます。双方向検索は、1 つの検索グラフを 2 つの小さなサブグラフに置き換えます。1 つは最初の頂点から検索を開始し、もう 1 つはゴール頂点から検索を開始します。これら 2 つのグラフが交差すると検索が停止します。
双方向検索では、BFS、DFS、DLS などの検索手法を使用できます。
利点:
- 双方向検索は高速です。
- 双方向検索で必要なメモリが少なくなります
短所:
- 双方向探索木の実装は難しい。
例:
以下の検索ツリーでは、双方向検索アルゴリズムが適用されます。このアルゴリズムは、1 つのグラフ/ツリーを 2 つのサブグラフに分割します。ノード 1 から順方向にトラバースを開始し、ゴール ノード 16 から逆方向にトラバースを開始します。
アルゴリズムは、2 つの検索が交わるノード 9 で終了します。

完全: 両方の検索で BFS を使用すると、双方向検索が完了します。
時間計算量: BFS を使用した双方向検索の時間計算量は、 O(bd) 。
空間の複雑さ: 双方向検索の空間複雑度は O(bd) 。
最適な: 双方向検索が最適です。