- Redshift は、クラウド上の高速かつ強力なフルマネージドのペタバイト規模のデータ ウェアハウス サービスです。
- 顧客は Redshift を 1 時間あたりわずか 0.25 ドルで、コミットメントや前払い費用なしで使用でき、年間 1 テラバイトあたり 1,000 ドルでペタバイト以上に拡張できます。
OLAP
OLAP は、 オンライン分析処理システム によって使用されます 赤方偏移 。
OLAP トランザクションの例:
デジタル ラジオ製品の EMEA と太平洋地域の純利益を計算するとします。これには、大量のレコードを取得する必要があります。純利益の計算に必要な記録は次のとおりです。
- EMEA で販売されたラジオの合計。
- 太平洋地域で販売されたラジオの合計。
- 各地域の無線の単価。
- 各ラジオの販売価格
- 販売価格 - 単価
上記のレコードを取得するには、複雑なクエリが必要です。データ ウェアハウス データベースは、データベースの観点とインフラストラクチャ層の両方の観点から、異なるタイプのアーキテクチャを使用します。
赤方偏移構成
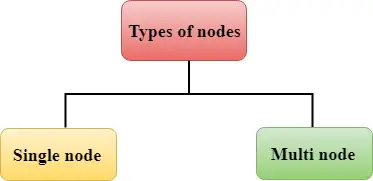
Redshift は 2 種類のノードで構成されます。
単一ノード: 単一ノードは最大 160 GB を保存します。
マルチノード: マルチノードは、複数のノードで構成されるノードです。これには次の 2 つのタイプがあります。
クライアント接続を管理し、クエリを受信します。リーダー ノードは、クライアント アプリケーションからクエリを受信し、クエリを解析して、実行計画を作成します。これらのプランの並列実行をコンピューティング ノードと調整し、すべてのノードの中間結果を結合して、最終結果をクライアント アプリケーションに返します。
コンピューティング ノードは実行プランを実行し、中間結果はクライアント アプリケーションに送り返される前に集約のためにリーダー ノードに送信されます。最大 128 個の計算ノードを含めることができます。
例を通して、リーダー ノードとコンピューティング ノードの概念を理解しましょう。
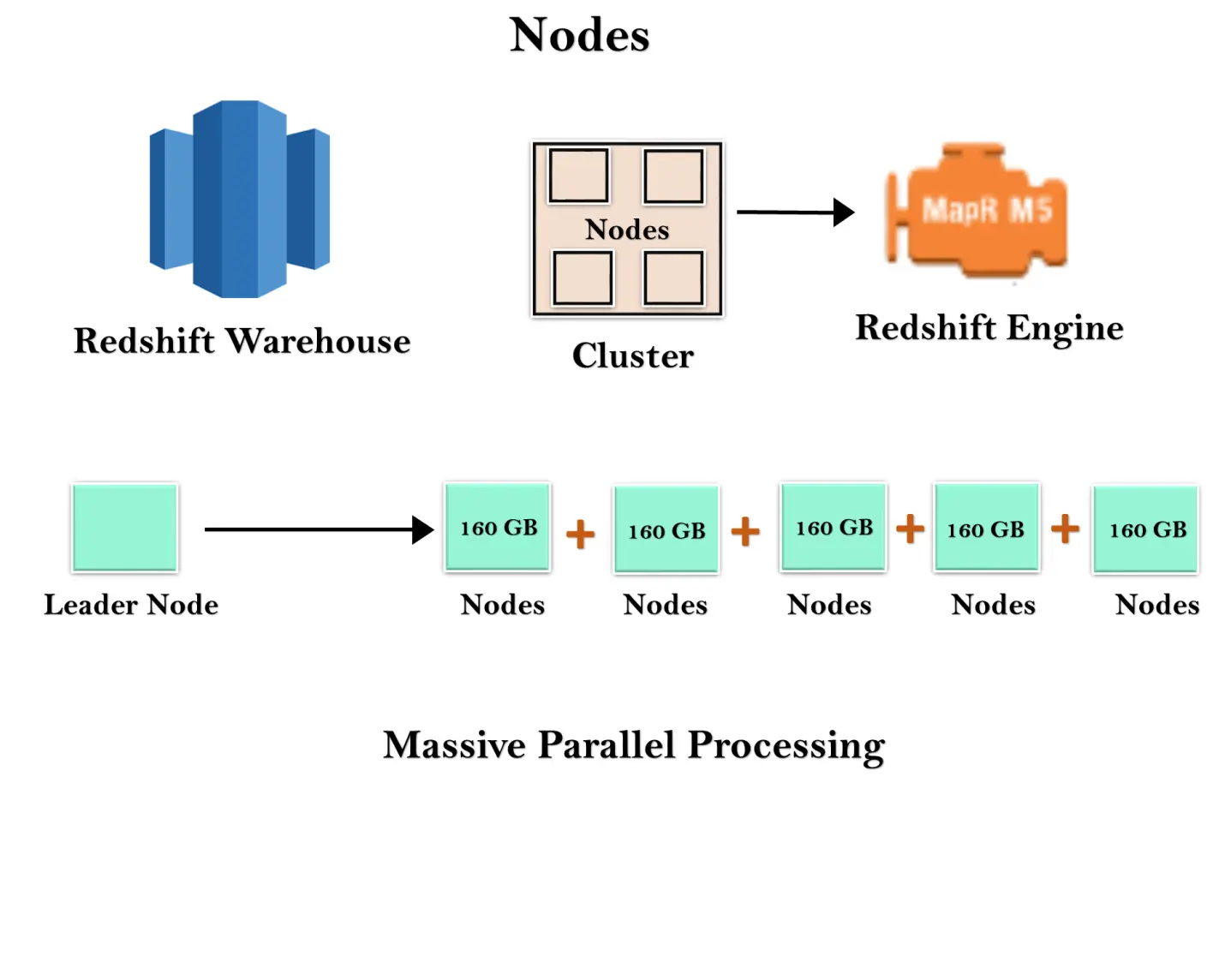
Redshift ウェアハウスはノードと呼ばれるコンピューティング リソースの集合であり、これらのノードはクラスターと呼ばれるグループに編成されます。各クラスターは、1 つ以上のデータベースを含む Redshift Engine で実行されます。
Redshift インスタンスを起動すると、サイズ 160 GB の単一ノードから開始されます。拡張したい場合は、ノードを追加して並列処理を利用できます。複数のノードを管理するリーダー ノードがあります。リーダー ノードは、クライアント接続と計算ノードを処理します。データを計算ノードに保存し、クエリを実行します。
Redshift が 10 倍高速な理由
Redshift は次の理由により 10 倍高速です。
Amazon Redshift では、データを一連の行として保存するのではなく、列ごとにデータを整理します。行ベースのシステムはトランザクション処理に最適ですが、列ベースのシステムは、クエリに大規模なデータ セットに対して実行される集計が含まれることが多いデータ ウェアハウジングや分析に最適です。クエリに含まれる列のみが処理され、列形式のデータがストレージ メディアに順次格納されるため、列ベースのシステムでは必要な I/O が少なくなり、クエリのパフォーマンスが向上します。
列指向のデータ ストアは、同様のデータがディスク上に順番に保存されるため、行ベースのデータ ストアよりもはるかに圧縮できます。 Amazon Redshift は複数の圧縮技術を採用しており、多くの場合、従来のリレーション データ ストアと比べて大幅な圧縮を実現できます。
Amazon Redshift はインデックスやマテリアライズド ビューを必要としないため、従来のリレーショナル データベース システムよりも必要なスペースが少なくなります。空のテーブルにデータをロードすると、Amazon Redshift はデータを自動的にサンプリングし、最も適切な圧縮技術を選択します。
Amazon Redshift は、データを自動的に分散し、さまざまなノードにクエリをロードします。 Amazon Redshift を使用すると、データ ウェアハウスに新しいノードを簡単に追加できるため、データ ウェアハウスの成長に合わせてより高速なクエリ パフォーマンスを実現できます。
赤方偏移の特徴
Redshift の機能は次のとおりです。
スプリングモジュール
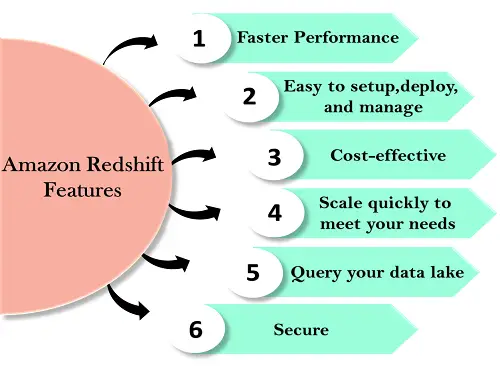
Redshift はセットアップと操作が簡単です。 AWS コンソールで数回クリックするだけで新しいデータ ウェアハウスをデプロイでき、Redshift がインフラストラクチャを自動的にプロビジョニングします。 AWS では、バックアップやレプリケーションなどのすべての管理タスクが自動化されているため、管理ではなくデータに集中する必要があります。
Redshift はデータを S3 に自動的にバックアップします。災害復旧のために、別のリージョンの S3 にスナップショットをレプリケートすることもできます。
Amazon Redshift は、使用した分だけ料金を支払う必要があるため、最も費用対効果の高いデータ ウェアハウス サービスです。
そのコストは、コミットメントや前払い費用なしで 1 時間あたり 0.25 ドルから始まり、年間 1 テラバイトあたり 250 ドルまでスケールアウトできます。
Amazon Redshift は、前払い費用なしのオンデマンド価格を提供する唯一のデータ ウェアハウス サービスであり、1 ~ 3 年の期間を提供することで最大 75% 節約できるリザーブド インスタンス価格も提供します。
2 つのノードのいずれかを選択して Redshift を最適化できます。
高密度コンピューティング ノードは、高速 CPU、大量の RAM、ソリッド ステート ディスクを使用して、高性能のデータ ウェアハウスを作成できます。
コストを削減したい場合は、高密度ストレージ ノードを使用できます。大容量のハードディスク ドライブを使用して、コスト効率の高いデータ ウェアハウスを作成します。
Amazon Redshift は、ニーズの変化に応じてノードを自動的にスケールアップまたはスケールダウンします。 AWS コンソールで数回クリックするか、API を 1 回呼び出すだけで、データ ウェアハウス内のノードの数を簡単に変更できます。
これは、Amazon S3 内のエクサバイトのデータに対してクエリを実行できるようにする Redshift の機能です。 Amazon S3 は、オープン形式で無制限のデータを保存できる、安全でコスト効率の高いデータです。
これは Redshift の機能であり、複数のクエリが Amazon S3 内の同じデータにアクセスできることを意味します。これにより、クエリの複雑さやデータ量に関係なく、複数のノードにわたってクエリを実行できます。
Amazon Redshift は、データをロードせずに Amazon S3 データレイクにクエリを実行するために使用される唯一のデータ ウェアハウスです。これにより、頻繁にアクセスされるデータは Redshift に保存され、非構造化データまたはアクセス頻度の低いデータは Amazon S3 に保存されるため、柔軟性が得られます。
いくつかのパラメーター設定を使用すると、SSL を使用してデータを保護するように Redshift を設定できます。暗号化を有効にすることもでき、ディスクに書き込まれるすべてのデータが暗号化されます。
Amazon Redshift は、列指向のデータ ストレージ、圧縮、並列処理を提供して、クエリの実行に必要な I/O の量を削減します。これにより、クエリのパフォーマンスが向上します。