重要な側面の 1 つは、 機械学習 モデルの評価です。モデルを評価するには何らかのメカニズムが必要です。ここで、これらのパフォーマンス指標が登場し、モデルがどれほど優れているかを知ることができます。いくつかの基本を理解している場合は、 機械学習 精度、精度、再現率、auc-roc など、分類タスクに一般的に使用されるメトリクスのいくつかに遭遇したことがあるはずです。この記事では、そのような指標の 1 つである AUC-ROC 曲線について詳しく説明します。
目次
- AUC-ROC曲線とは何ですか?
- AUC および ROC 曲線で使用される重要な用語
- 感度、特異性、FPR、およびしきい値の関係。
- AUC-ROCはどのように機能しますか?
- AUC-ROC 評価指標はいつ使用する必要がありますか?
- モデルのパフォーマンスを推測する
- AUC-ROC 曲線を理解する
- 2 つの異なるモデルを使用した実装
- マルチクラス モデルに ROC-AUC を使用するにはどうすればよいですか?
- 機械学習における AUC ROC 曲線に関する FAQ
AUC-ROC曲線とは何ですか?
AUC-ROC 曲線、または受信者動作特性曲線下の面積は、さまざまな分類しきい値でのバイナリ分類モデルのパフォーマンスをグラフで表現したものです。これは機械学習で一般的に、2 つのクラス、通常はポジティブ クラス (例: 病気の存在) とネガティブ クラス (例: 病気の不在) を区別するモデルの能力を評価するために使用されます。
まずはこの2つの用語の意味を理解しましょう ROC そして AUC 。
- ROC : 受信機の動作特性
- AUC : 曲線下の面積
受信機動作特性 (ROC) 曲線
ROC は受信者動作特性の略で、ROC 曲線は二項分類モデルの有効性をグラフで表したものです。さまざまな分類しきい値での真陽性率 (TPR) と偽陽性率 (FPR) をプロットします。
曲線下の面積 (AUC) 曲線:
AUC は、Area Under the Curve の略で、AUC 曲線は ROC 曲線の下の面積を表します。これは、二項分類モデルの全体的なパフォーマンスを測定します。 TPR と FPR の範囲は両方とも 0 ~ 1 であるため、領域は常に 0 ~ 1 の間にあり、AUC の値が大きいほどモデルのパフォーマンスが優れていることを示します。私たちの主な目標は、指定されたしきい値で最高の TPR と最低の FPR を実現するために、この領域を最大化することです。 AUC は、モデルがランダムに選択されたポジティブ インスタンスに、ランダムに選択されたネガティブ インスタンスと比較してより高い予測確率を割り当てる確率を測定します。
それは、 確率 これにより、モデルはターゲットに存在する 2 つのクラスを区別できます。
ROC-AUC 分類評価指標
AUC および ROC 曲線で使用される重要な用語
1.TPRとFPR
これは、AUC-ROC を Google で検索するときに遭遇する最も一般的な定義です。基本的に、ROC 曲線は、考えられるすべてのしきい値 (しきい値とは、それを超えると点が特定のクラスに属すると言える特定の値) での分類モデルのパフォーマンスを示すグラフです。曲線は 2 つのパラメータ間にプロットされます
- TPR – 真陽性率
- FPR – 誤検知率
理解する前に、TPR と FPR について簡単に見てみましょう。 混同行列 。
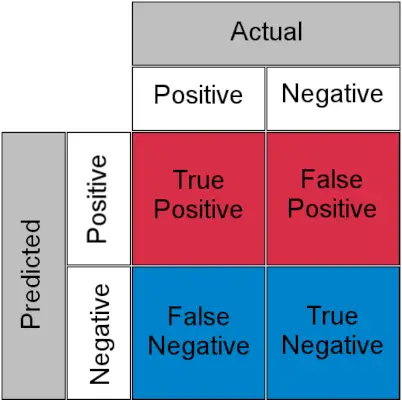
分類タスクの混同行列
- 真陽性 : 実際の陽性および陽性として予測
- 真の陰性 : 実際の陰性および陰性として予測される
- 誤検知 (タイプ I エラー) : 実際は陰性だが陽性と予測される
- 偽陰性(タイプ II エラー) : 実際は陽性だが陰性と予測される
簡単に言えば、誤検知を「誤検知」と呼ぶことができます。 誤報 および偽陰性 逃す 。ここで、TPR と FPR が何であるかを見てみましょう。
2. 感度/真陽性率/リコール
基本的に、TPR/再現率/感度は、正しく識別された陽性例の比率です。これは、ポジティブなインスタンスを正しく識別するモデルの能力を表し、次のように計算されます。

感度/再現率/TPR は、モデルによって陽性として正しく識別される実際の陽性インスタンスの割合を測定します。
3. 誤検知率
FPR は、誤って分類された陰性例の割合です。

4. 特異性
特異性は、モデルによって陰性として正しく識別される実際の陰性インスタンスの割合を測定します。ネガティブなインスタンスを正しく識別するモデルの能力を表します。

そして、前に述べたように、ROC はすべての可能なしきい値にわたる TPR と FPR の間のプロットにほかならず、AUC はこの ROC 曲線の下の領域全体です。
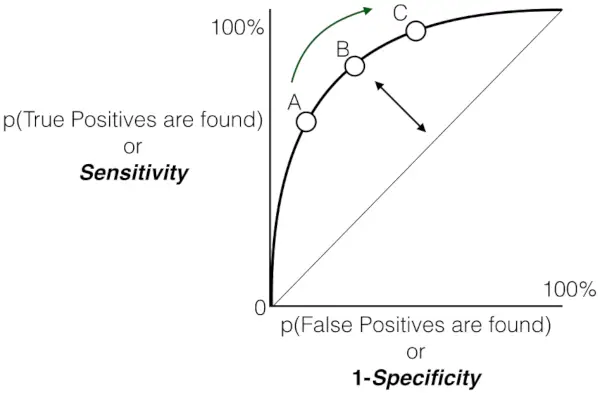
感度対誤検知率のプロット
感度、特異度、FPR、閾値の関係 。
感度と特異性:
- 逆の関係: 感度と特異度は逆相関の関係にあります。一方が増加すると、他方は減少する傾向があります。これは、真陽性率と真陰性率の間の固有のトレードオフを反映しています。
- しきい値によるチューニング: 閾値を調整することで、感度と特異度のバランスを制御できます。しきい値が低いと、感度が高くなります (真陽性が多くなります) が、特異性 (偽陽性が多くなります) が犠牲になります。逆に、しきい値を上げると特異性は向上します (偽陽性が少なくなります) が、感度は犠牲になります (偽陰性が増加します)。
しきい値と誤検知率 (FPR):
- FPR と特異性の関係: 偽陽性率 (FPR) は、単に特異性の補数です (FPR = 1 – 特異性)。これは、それらの間の直接的な関係を示しています。つまり、特異性が高いほど FPR は低くなり、その逆も同様です。
- TPR による FPR の変更: 同様に、観察したように、真陽性率 (TPR) と FPR もリンクされています。一般に、TPR の増加 (真陽性の増加) は、FPR (偽陽性の増加) の増加につながります。逆に、TPR が低下すると (真陽性が少なくなり)、FPR も低下します (偽陽性が少なくなります)。
AUC-ROCはどのように機能しますか?
幾何学的解釈を見てきましたが、0.75 AUC が実際に何を意味するのかを理解するにはまだ不十分だと思います。次に、確率論的な観点から AUC-ROC を見てみましょう。まず AUC が何をするのかについて話しましょう。その後、これに基づいて理解を深めていきます。
AUC は、モデルが次のものをどの程度区別できるかを測定します。 クラス。
AUC が 0.75 ということは、実際には、別々のクラスに属する 2 つのデータ ポイントを取得したとすると、モデルがデータ ポイントを正しく分離またはランク付けできる可能性が 75% あることを意味します。つまり、正のポイントの予測確率が負のポイントよりも高いということです。クラス。 (予測確率が高いということは、ポイントが理想的にはポジティブ クラスに属することを意味すると仮定します)。物事をより明確にするために、ここに小さな例を示します。
索引 | クラス | 確率 |
|---|---|---|
P1 | 1 | 0.95 |
P2 | 1 | 0.90 |
P3 | 0 | 0.85 |
P4 | 0 | 0.81 |
P5 | 1 | 0.78 |
P6 | 0 | 0.70 |
ここには、P1、P2、および P5 がクラス 1 に属し、P3、P4、および P6 がクラス 0 に属する 6 つの点があり、別々のクラスに属する 2 つの点を取得した場合に述べたように、[確率] 列の予測確率に対応しています。クラスの場合、モデルのランクがクラスを正しく順序付けする確率はどれくらいですか。
1 つの点がクラス 1 に属し、もう 1 つの点がクラス 0 に属するようなすべての可能なペアを取得します。合計 9 つのペアがあり、以下はこれら 9 つの可能なペアすべてです。
ペア | 正しい |
|---|---|
(P1、P3) | はい |
(P1、P4) | はい |
(P1、P6) | はい |
(P2、P3) | はい |
(P2、P4) | はい |
(P2、P6) | はい |
(P3、P5) | いいえ |
(P4、P5) | いいえ |
(P5、P6) | はい |
ここで列が「正しい」は、言及されたペアが予測確率に基づいて正しくランク付けされているかどうかを示します。つまり、クラス 1 ポイントの確率がクラス 0 ポイントよりも高い、これら 9 つの可能なペアのうち 7 つで、クラス 1 がクラス 0 よりも高いランクにある、または別のクラスに属する点のペアを選択した場合、モデルがそれらを正しく区別できる可能性は 77% あると言えます。さて、この AUC 数値の背後にある直感が少しあると思いますが、さらなる疑問を解消するために、Scikit の AUC-ROC 実装を学習して検証してみましょう。
Python3
import> numpy as np> from> sklearn .metrics>import> roc_auc_score> y_true>=> [>1>,>1>,>0>,>0>,>1>,>0>]> y_pred>=> [>0.95>,>0.90>,>0.85>,>0.81>,>0.78>,>0.70>]> auc>=> np.>round>(roc_auc_score(y_true, y_pred),>3>)> print>(>'Auc for our sample data is {}'>.>format>(auc))> |
>
>
出力:
AUC for our sample data is 0.778>
AUC-ROC 評価指標はいつ使用する必要がありますか?
ROC-AUC の使用が理想的ではない領域がいくつかあります。データセットが著しく不均衡な場合、 ROC 曲線は、モデルのパフォーマンスについて過度に楽観的な評価を与える可能性があります 。この楽観的なバイアスは、実際の陰性の数が多い場合、ROC 曲線の偽陽性率 (FPR) が非常に小さくなる可能性があるために発生します。
FPRの公式を見ると、

Javaのリターンコマンド
私たちは観察します 、
- ネガティブ クラスが多数派であり、FPR の分母は真のネガティブによって支配されているため、FPR は少数派のクラス (ポジティブ クラス) に関連する予測の変化に対する感度が低くなります。
- ROC 曲線は、偽陽性と偽陰性のコストのバランスが取れており、データセットの不均衡が著しくない場合に適切である可能性があります。
そういった場合には、 適合率と再現率の曲線 これは、ポジティブ (少数派) クラスに関する分類子のパフォーマンスに焦点を当て、不均衡なデータセットにより適した代替評価メトリックを提供するために使用できます。
モデルのパフォーマンスを推測する
- 高い AUC (1 に近い) は、優れた識別力を示します。これは、モデルが 2 つのクラスを区別するのに効果的であり、その予測が信頼できることを意味します。
- AUC が低い (0 に近い) 場合は、パフォーマンスが低いことを示します。この場合、モデルはポジティブなクラスとネガティブなクラスを区別するのに苦労しており、その予測は信頼できない可能性があります。
- AUC が約 0.5 ということは、モデルが基本的にランダムな推測を行っていることを意味します。クラスを分離する機能がないことは、モデルがデータから意味のあるパターンを学習していないことを示しています。
AUC-ROC 曲線を理解する
ROC 曲線では、通常、x 軸は偽陽性率 (FPR) を表し、y 軸は真陽性率 (TPR) (感度または再現率とも呼ばれます) を表します。したがって、ROC 曲線の X 軸の値が高い (右に向かう) と偽陽性率が高いことを示し、Y 軸の値が高い (上に向かう) と真陽性率が高いことを示します。ROC 曲線はグラフです。さまざまなしきい値での真陽性率と偽陽性率の間のトレードオフを表します。これは、さまざまな分類しきい値での分類モデルのパフォーマンスを示します。 AUC (曲線下面積) は、ROC 曲線のパフォーマンスの概要測定値です。しきい値の選択は、解決しようとしている問題の特定の要件と、偽陽性と偽陰性の間のトレードオフによって決まります。あなたの文脈では受け入れられます。
- 誤検知を減らすことを優先したい場合 (実際ではないのに陽性と判断される可能性を最小限に抑えたい場合)、誤検知率が低くなるしきい値を選択するとよいでしょう。
- 真陽性の増加 (できるだけ多くの実際の陽性を捕捉) を優先したい場合は、真陽性率が高くなるしきい値を選択するとよいでしょう。
さまざまな用途に対して ROC 曲線がどのように生成されるかを説明する例を考えてみましょう。 しきい値 そして、特定のしきい値が混同行列にどのように対応するか。あるとします。 二項分類問題 電子メールがスパム (ポジティブ) かスパムではない (ネガティブ) かを予測するモデルを使用します。
仮説的なデータを考えてみましょう。
真のラベル: [1、0、1、0、1、1、0、0、1、0]
予測確率: [0.8、0.3、0.6、0.2、0.7、0.9、0.4、0.1、0.75、0.55]
ケース 1: しきい値 = 0.5
真のラベル | 予測される確率 | 予測されたラベル |
|---|---|---|
| 1 | 0.8 js配列 | 1 |
| 0 | 0.3 | 0 |
| 1 | 0.6 | 1 |
| 0 | 0.2 | 0 |
| 1 | 0.7 | 1 |
| 1 | 0.9 | 1 |
| 0 | 0.4 | 0 |
| 0 | 0.1 | 0 |
| 1 | 0.75 | 1 |
| 0 | 0.55 | 1 |
上記の予測に基づく混同行列
| 予測 = 0 | 予測 = 1 |
|---|---|---|
実際 = 0 | TP=4 | FN=1 |
実際 = 1 | FP=0 | TN=5 |
それに応じて、
- 真陽性率 (TPR) :
分類子によって正しく識別された実際の陽性者の割合は次のとおりです。

- 誤検知率 (FPR) :
実際に陽性と誤って分類された陰性の割合



したがって、しきい値 0.5 では次のようになります。
- 真陽性率(感度):0.8
- 誤検知率: 0
このしきい値では、モデルは実際の陽性 (TPR) の 80% を正しく識別しますが、実際の陰性の 0% を陽性 (FPR) として誤って分類すると解釈されます。
したがって、さまざまなしきい値に対して、次の結果が得られます。
ケース 2: しきい値 = 0.7
真のラベル | 予測される確率 | 予測されたラベル |
|---|---|---|
| 1 | 0.8 | 1 |
| 0 | 0.3 | 0 |
| 1 | 0.6 | 0 |
| 0 | 0.2 | 0 |
| 1 | 0.7 | 0 |
| 1 | 0.9 | 1 |
| 0 | 0.4 | 0 |
| 0 | 0.1 | 0 |
| 1 | 0.75 | 1 |
| 0 | 0.55 | 0 |
上記の予測に基づく混同行列
| 予測 = 0 | 予測 = 1 |
|---|---|---|
実際 = 0 | TP=5 | FN=0 |
実際 = 1 | FP=2 | TN=3 |
それに応じて、
- 真陽性率 (TPR) :
分類子によって正しく識別された実際の陽性者の割合は次のとおりです。

- 誤検知率 (FPR) :
実際に陽性と誤って分類された陰性の割合



ケース 3: しきい値 = 0.4
真のラベル | 予測される確率 | 予測されたラベル |
|---|---|---|
| 1 | 0.8 | 1 |
| 0 | 0.3 | 0 |
| 1 | 0.6 | 1 |
| 0 | 0.2 | 0 |
| 1 | 0.7 | 1 |
| 1 | 0.9 | 1 |
| 0 | 0.4 | 0 |
| 0 | 0.1 | 0 |
| 1 | 0.75 | 1 |
| 0 | 0.55 | 1 |
上記の予測に基づく混同行列
| 予測 = 0 | 予測 = 1 |
|---|---|---|
実際 = 0 | TP=4 | FN=1 |
実際 = 1 | FP=0 | TN=5 |
それに応じて、
- 真陽性率 (TPR) :
分類子によって正しく識別された実際の陽性者の割合は次のとおりです。
- 誤検知率 (FPR) :
実際に陽性と誤って分類された陰性の割合
ケース 4: しきい値 = 0.2
真のラベル | 予測される確率 | 予測されたラベル |
|---|---|---|
| 1 | 0.8 | 1 |
| 0 | 0.3 | 1 |
| 1 | 0.6 | 1 |
| 0 | 0.2 | 0 |
| 1 | 0.7 | 1 |
| 1 | 0.9 | 1 C++ intから文字列へ |
| 0 | 0.4 | 1 |
| 0 | 0.1 | 0 |
| 1 | 0.75 | 1 |
| 0 | 0.55 | 1 |
上記の予測に基づく混同行列
| 予測 = 0 | 予測 = 1 |
|---|---|---|
実際 = 0 | TP=2 | FN=3 |
実際 = 1 | FP=0 | TN=5 |
それに応じて、
- 真陽性率 (TPR) :
分類子によって正しく識別された実際の陽性者の割合は次のとおりです。

- 誤検知率 (FPR) :
実際に陽性と誤って分類された陰性の割合

ケース 5: しきい値 = 0.85
真のラベル | 予測される確率 | 予測されたラベル |
|---|---|---|
| 1 | 0.8 | 0 |
| 0 | 0.3 | 0 |
| 1 | 0.6 | 0 |
| 0 | 0.2 | 0 |
| 1 | 0.7 | 0 |
| 1 | 0.9 | 1 |
| 0 | 0.4 | 0 |
| 0 | 0.1 | 0 |
| 1 | 0.75 | 0 |
| 0 | 0.55 | 0 |
上記の予測に基づく混同行列
| 予測 = 0 | 予測 = 1 |
|---|---|---|
実際 = 0 | TP=5 | FN=0 |
実際 = 1 アルファベット番号付き | FP=4 | TN=1 |
それに応じて、
- 真陽性率 (TPR) :
分類子によって正しく識別された実際の陽性者の割合は次のとおりです。
- 誤検知率 (FPR) :
実際に陽性と誤って分類された陰性の割合


上記の結果に基づいて、ROC 曲線をプロットします。
Python3
true_positive_rate>=> [>0.4>,>0.8>,>0.8>,>1.0>,>1>]> false_positive_rate>=> [>0>,>0>,>0>,>0.2>,>0.8>]> plt.plot(false_positive_rate, true_positive_rate,>'o-'>, label>=>'ROC'>)> plt.plot([>0>,>1>], [>0>,>1>],>'--'>, color>=>'grey'>, label>=>'Worst case'>)> plt.xlabel(>'False Positive Rate'>)> plt.ylabel(>'True Positive Rate'>)> plt.title(>'ROC Curve'>)> plt.legend()> plt.show()> |
>
>
出力:
グラフから次のことが示唆されます。
- 灰色の破線は最悪のシナリオを表しており、モデルの予測、つまり TPR と FPR が同じです。この斜線は最悪のシナリオと考えられ、偽陽性と偽陰性の可能性が等しいことを示しています。
- 点がランダムな推測線から左上隅に向かって外れるにつれて、モデルのパフォーマンスが向上します。
- 曲線下面積 (AUC) は、モデルの識別能力の定量的な尺度です。 AUC 値が高く、1.0 に近いほど、パフォーマンスが優れていることを示します。可能な最良の AUC 値は 1.0 で、これは 100% の感度と 100% の特異性を達成するモデルに相当します。
全体として、受信者動作特性 (ROC) 曲線は、バイナリ分類モデルの真陽性率 (感度) とさまざまな判定しきい値での偽陽性率の間のトレードオフをグラフで表現したものとして機能します。曲線が左上隅に向かって優雅に上昇していることは、信頼度のしきい値の範囲にわたって陽性と陰性のインスタンスを区別するモデルの賞賛に値する能力を示しています。この上向きの軌道は、誤検知を最小限に抑えながら高い感度が達成され、パフォーマンスが向上していることを示しています。 A、B、C、D、E で示される注釈付きのしきい値は、さまざまな信頼レベルでのモデルの動的な動作についての貴重な洞察を提供します。
2 つの異なるモデルを使用した実装
ライブラリのインストール
Python3
import> numpy as np> import> pandas as pd> import> matplotlib.pyplot as plt> from> sklearn.datasets>import> make_classification> from> sklearn.model_selection>import> train_test_split> from> sklearn.linear_model>import> LogisticRegression> from> sklearn.ensemble>import> RandomForestClassifier> from> sklearn.metrics>import> roc_curve, auc> |
>
>
を訓練するために、 ランダムフォレスト そして ロジスティック回帰 モデルを作成し、その ROC 曲線を AUC スコアとともに提示するために、アルゴリズムは人工的な二値分類データを作成します。
データの生成とデータの分割
Python3
# Generate synthetic data for demonstration> X, y>=> make_classification(> >n_samples>=>1000>, n_features>=>20>, n_classes>=>2>, random_state>=>42>)> # Split the data into training and testing sets> X_train, X_test, y_train, y_test>=> train_test_split(> >X, y, test_size>=>0.2>, random_state>=>42>)> |
>
>
このアルゴリズムは、80:20 の分割比を使用して、20 の特徴を持つ人工バイナリ分類データを作成し、それをトレーニング セットとテスト セットに分割し、再現性を確保するためにランダム シードを割り当てます。
さまざまなモデルをトレーニングする
Python3
# Train two different models> logistic_model>=> LogisticRegression(random_state>=>42>)> logistic_model.fit(X_train, y_train)> random_forest_model>=> RandomForestClassifier(n_estimators>=>100>, random_state>=>42>)> random_forest_model.fit(X_train, y_train)> |
>
>
このメソッドは、反復性を確保するために固定ランダム シードを使用して、トレーニング セット上でロジスティック回帰モデルを初期化し、トレーニングします。同様の方法で、トレーニング データと同じランダム シードを使用して、100 個のツリーでランダム フォレスト モデルを初期化してトレーニングします。
予測
Python3
# Generate predictions> y_pred_logistic>=> logistic_model.predict_proba(X_test)[:,>1>]> y_pred_rf>=> random_forest_model.predict_proba(X_test)[:,>1>]> |
>
>
テストデータとトレーニング済みのデータを使用する ロジスティック回帰 モデルでは、コードは陽性クラスの確率を予測します。同様に、テスト データを使用して、トレーニングされたランダム フォレスト モデルを使用して、陽性クラスの予測確率を生成します。
データフレームの作成
Python3
# Create a DataFrame> test_df>=> pd.DataFrame(> >{>'True'>: y_test,>'Logistic'>: y_pred_logistic,>'RandomForest'>: y_pred_rf})> |
>
>
このコードは、テスト データを使用して、True、Logistic、および RandomForest というラベルの列を持つ test_df という名前のデータフレームを作成し、真のラベルとランダム フォレスト モデルとロジスティック回帰モデルからの予測確率を追加します。
モデルの ROC 曲線をプロットする
Python3
# Plot ROC curve for each model> plt.figure(figsize>=>(>7>,>5>))> for> model>in> [>'Logistic'>,>'RandomForest'>]:> >fpr, tpr, _>=> roc_curve(test_df[>'True'>], test_df[model])> >roc_auc>=> auc(fpr, tpr)> >plt.plot(fpr, tpr, label>=>f>'{model} (AUC = {roc_auc:.2f})'>)> # Plot random guess line> plt.plot([>0>,>1>], [>0>,>1>],>'r--'>, label>=>'Random Guess'>)> # Set labels and title> plt.xlabel(>'False Positive Rate'>)> plt.ylabel(>'True Positive Rate'>)> plt.title(>'ROC Curves for Two Models'>)> plt.legend()> plt.show()> |
>
>
出力:

このコードは、8 x 6 インチの図を含むプロットを生成します。各モデル (ランダム フォレストとロジスティック回帰) の AUC 曲線と ROC 曲線を計算し、ROC 曲線をプロットします。の ROC曲線 ランダムな推測の場合も赤い破線で表され、視覚化のためにラベル、タイトル、凡例が設定されます。
マルチクラス モデルに ROC-AUC を使用するにはどうすればよいですか?
マルチクラス設定の場合、単純に 1 つ対すべての手法を使用するだけで、クラスごとに 1 つの ROC 曲線が得られます。 4 つのクラス A、B、C、D があるとします。その場合、4 つのクラスすべてに ROC 曲線と対応する AUC 値が存在します。つまり、A が 1 つのクラスとなり、B、C、D を組み合わせたものが他のクラスになります。 、同様に、B は 1 つのクラス、A、C、D は他のクラスとして結合されます。
マルチクラス分類モデルのコンテキストで AUC-ROC を使用するための一般的な手順は次のとおりです。
一対すべての方法論:
- マルチクラス問題の各クラスをポジティブ クラスとして扱い、他のすべてのクラスをネガティブ クラスに結合します。
- 各クラスのバイナリ分類器を残りのクラスに対してトレーニングします。
各クラスの AUC-ROC を計算します。
- ここでは、指定されたクラスの ROC 曲線を残りのクラスに対してプロットします。
- 各クラスの ROC 曲線を同じグラフにプロットします。各曲線は、特定のクラスのモデルの識別パフォーマンスを表します。
- 各クラスの AUC スコアを調べます。 AUC スコアが高いほど、その特定のクラスの識別が優れていることを示します。
多クラス分類における AUC-ROC の実装
ライブラリのインポート
Python3
import> numpy as np> import> matplotlib.pyplot as plt> from> sklearn.datasets>import> make_classification> from> sklearn.model_selection>import> train_test_split> from> sklearn.preprocessing>import> label_binarize> from> sklearn.multiclass>import> OneVsRestClassifier> from> sklearn.linear_model>import> LogisticRegression> from> sklearn.ensemble>import> RandomForestClassifier> from> sklearn.metrics>import> roc_curve, auc> from> itertools>import> cycle> |
>
>
プログラムは人工的なマルチクラス データを作成し、それをトレーニング セットとテスト セットに分割して、 One-vs-Restclassifier ランダム フォレストとロジスティック回帰の両方の分類器をトレーニングする手法。最後に、2 つのモデルのマルチクラス ROC 曲線をプロットして、さまざまなクラスをどのように区別できるかを示します。
データの生成と分割
Python3
# Generate synthetic multiclass data> X, y>=> make_classification(> >n_samples>=>1000>, n_features>=>20>, n_classes>=>3>, n_informative>=>10>, random_state>=>42>)> # Binarize the labels> y_bin>=> label_binarize(y, classes>=>np.unique(y))> # Split the data into training and testing sets> X_train, X_test, y_train, y_test>=> train_test_split(> >X, y_bin, test_size>=>0.2>, random_state>=>42>)> |
>
>
3 つのクラスと 20 の機能が、コードによって生成される合成マルチクラス データを構成します。ラベルの二値化後、データは 80 対 20 の比率でトレーニング セットとテスト セットに分割されます。
トレーニングモデル
Python3
# Train two different multiclass models> logistic_model>=> OneVsRestClassifier(LogisticRegression(random_state>=>42>))> logistic_model.fit(X_train, y_train)> rf_model>=> OneVsRestClassifier(> >RandomForestClassifier(n_estimators>=>100>, random_state>=>42>))> rf_model.fit(X_train, y_train)> |
>
>
このプログラムは 2 つのマルチクラス モデルをトレーニングします。1 つは 100 個の推定器を備えたランダム フォレスト モデル、もう 1 つはロジスティック回帰モデルです。 1 対残りのアプローチ 。データのトレーニング セットを使用すると、両方のモデルが適合されます。
AUC-ROC 曲線のプロット
Python3
# Compute ROC curve and ROC area for each class> fpr>=> dict>()> tpr>=> dict>()> roc_auc>=> dict>()> models>=> [logistic_model, rf_model]> plt.figure(figsize>=>(>6>,>5>))> colors>=> cycle([>'aqua'>,>'darkorange'>])> for> model, color>in> zip>(models, colors):> >for> i>in> range>(model.classes_.shape[>0>]):> >fpr[i], tpr[i], _>=> roc_curve(> >y_test[:, i], model.predict_proba(X_test)[:, i])> >roc_auc[i]>=> auc(fpr[i], tpr[i])> >plt.plot(fpr[i], tpr[i], color>=>color, lw>=>2>,> >label>=>f>'{model.__class__.__name__} - Class {i} (AUC = {roc_auc[i]:.2f})'>)> # Plot random guess line> plt.plot([>0>,>1>], [>0>,>1>],>'k--'>, lw>=>2>, label>=>'Random Guess'>)> # Set labels and title> plt.xlabel(>'False Positive Rate'>)> plt.ylabel(>'True Positive Rate'>)> plt.title(>'Multiclass ROC Curve with Logistic Regression and Random Forest'>)> plt.legend(loc>=>'lower right'>)> plt.show()> |
>
>
出力:

ランダム フォレスト モデルとロジスティック回帰モデルの ROC 曲線と AUC スコアは、各クラスのコードによって計算されます。次に、マルチクラス ROC 曲線がプロットされ、各クラスの識別性能が示され、ランダムな推測を表す線が特徴付けられます。結果として得られるプロットは、モデルの分類パフォーマンスのグラフィック評価を提供します。
結論
機械学習では、バイナリ分類モデルのパフォーマンスは、受信者動作特性下面積 (AUC-ROC) と呼ばれる重要な指標を使用して評価されます。さまざまな決定しきい値にわたって、感度と特異性がどのようにトレードオフされるかを示します。通常、AUC スコアが高いモデルほど、陽性例と陰性例の区別が大きくなります。 0.5 は偶然を表しますが、1 は完璧なパフォーマンスを表します。モデルの最適化と選択は、クラス間を識別するモデルの能力について AUC-ROC 曲線が提供する有用な情報によって支援されます。偽陽性と偽陰性でコストが異なる不均衡なデータセットやアプリケーションを扱う場合、包括的な尺度として特に役立ちます。
機械学習における AUC ROC 曲線に関する FAQ
1. AUC-ROC 曲線とは何ですか?
さまざまな分類しきい値について、真陽性率 (感度) と偽陽性率 (特異度) の間のトレードオフは、AUC-ROC 曲線によってグラフで表されます。
2. 完璧な AUC-ROC 曲線はどのようなものですか?
理想的な AUC-ROC 曲線上の面積 1 は、モデルがすべてのしきい値で最適な感度と特異度を達成していることを意味します。
3. AUC 値 0.5 は何を意味しますか?
AUC 0.5 は、モデルのパフォーマンスがランダムな確率のパフォーマンスに匹敵することを示します。それは識別能力の欠如を示唆しています。
4. AUC-ROC はマルチクラス分類に使用できますか?
AUC-ROC は、バイナリ分類に関連する問題に頻繁に適用されます。マルチクラス分類では、マクロ平均またはミクロ平均 AUC などの変動を考慮できます。
5. AUC-ROC 曲線はモデルの評価にどのように役立ちますか?
クラスを区別するモデルの能力は、AUC-ROC 曲線によって包括的に要約されます。不均衡なデータセットを扱う場合、これは特に役立ちます。