現実の世界では、私たちが扱うすべてのデータにターゲット変数があるわけではありません。この種のデータは、教師あり学習アルゴリズムを使用して分析することはできません。教師なしアルゴリズムの助けが必要です。教師なし学習における最も一般的なタイプの分析の 1 つは次のとおりです。 顧客のセグメンテーション ターゲットを絞った広告や、未知の感染領域や新たな感染領域を見つけるための医療画像処理など、この記事でさらに詳しく説明する多くの使用例に使用されます。
目次
クラスタリングとは何ですか?
相互の類似性に基づいてデータ ポイントをグループ化するタスクは、クラスタリングまたはクラスター分析と呼ばれます。このメソッドは、のブランチで定義されています。 教師なし学習 、ラベルのないデータポイントから洞察を得ることを目的としています。 教師あり学習 ターゲット変数はありません。
クラスタリングは、異種のデータセットから同種のデータ ポイントのグループを形成することを目的としています。ユークリッド距離、コサイン類似度、マンハッタン距離などのメトリックに基づいて類似性を評価し、最も高い類似性スコアを持つ点をグループ化します。
たとえば、以下のグラフでは、距離に基づいて 3 つの円形クラスターが形成されていることがはっきりとわかります。
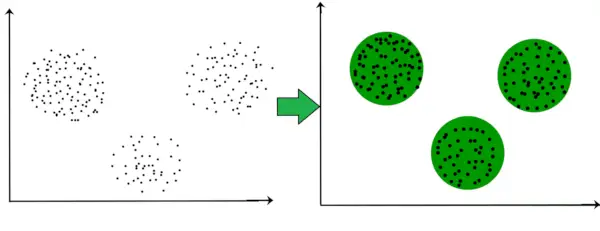
ここで、形成されるクラスターの形状が円形である必要はありません。クラスターの形状は任意です。任意の形状のクラスターの検出に適したアルゴリズムが多数あります。
たとえば、以下のグラフでは、形成されたクラスターの形状が円形ではないことがわかります。

Javaメソッド
クラスタリングの種類
大まかに言うと、類似したデータ ポイントをグループ化するために実行できるクラスタリングには 2 つのタイプがあります。
- ハードクラスタリング: このタイプのクラスタリングでは、各データ ポイントが完全にクラスターに属するかどうかに関係なく、クラスターに属します。たとえば、4 つのデータ ポイントがあり、それらを 2 つのクラスターにクラスター化する必要があるとします。したがって、各データ ポイントはクラスター 1 またはクラスター 2 のいずれかに属します。
| データポイント | クラスター |
|---|---|
| あ | C1 |
| B | C2 |
| C | C2 |
| D | C1 |
- ソフトクラスタリング: このタイプのクラスタリングでは、各データ ポイントを個別のクラスターに割り当てる代わりに、そのポイントがそのクラスターである確率または尤度が評価されます。たとえば、4 つのデータ ポイントがあり、それらを 2 つのクラスターにクラスター化する必要があるとします。したがって、両方のクラスターに属するデータ ポイントの確率を評価します。この確率はすべてのデータ ポイントに対して計算されます。
| データポイント | C1の確率 | C2の確率 |
| あ | 0.91 | 0.09 |
| B | 0.3 | 0.7 |
| C | 0.17 | 0.83 |
| D | 1 | 0 |
クラスタリングの用途
クラスタリング アルゴリズムの種類について説明する前に、クラスタリング アルゴリズムの使用例について説明します。クラスタリング アルゴリズムは主に次の用途に使用されます。
- 市場セグメンテーション – 企業はクラスタリングを使用して顧客をグループ化し、ターゲットを絞った広告を使用してより多くの視聴者を引き付けます。
- ソーシャルネットワーク分析 – ソーシャル メディア サイトは、ユーザーのデータを使用してユーザーの閲覧行動を理解し、ターゲットを絞った友人の推奨事項やコンテンツの推奨事項を提供します。
- 医用画像 – 医師はクラスタリングを使用して、X 線などの診断画像から疾患領域を見つけます。
- 異常検出 – リアルタイム データセットのストリーム内で異常値を見つけたり、不正な取引を予測したりするには、クラスタリングを使用して異常値を特定できます。
- 大規模なデータセットの操作を簡素化 – クラスタリングが完了すると、各クラスターにクラスター ID が与えられます。ここで、機能セットの機能セット全体をそのクラスター ID に縮小できます。クラスタリングは、複雑なケースを単純なクラスタ ID で表現できる場合に効果的です。同じ原理を使用して、データをクラスタリングすると、複雑なデータセットを簡素化できます。
クラスタリングの使用例は他にもたくさんありますが、クラスタリングの主要で一般的な使用例がいくつかあります。今後は、上記のタスクの実行に役立つクラスタリング アルゴリズムについて説明します。
クラスタリングアルゴリズムの種類
表面レベルでは、クラスタリングは非構造化データの分析に役立ちます。グラフ作成、最短距離、データ ポイントの密度は、クラスターの形成に影響を与える要素の一部です。クラスタリングは、類似性測定と呼ばれる測定基準に基づいて、オブジェクトがどの程度関連しているかを判断するプロセスです。類似性メトリクスは、特徴のセットが小さいほど見つけやすくなります。特徴の数が増えると、類似性の尺度を作成するのが難しくなります。データ マイニングで利用されるクラスタリング アルゴリズムの種類に応じて、データセットからのデータをグループ化するためにいくつかの手法が使用されます。このパートでは、クラスタリング手法について説明します。さまざまなタイプのクラスタリング アルゴリズムは次のとおりです。
- セントロイドベースのクラスタリング (パーティショニング方法)
- 密度ベースのクラスタリング (モデルベースの手法)
- 接続ベースのクラスタリング (階層型クラスタリング)
- 分散ベースのクラスタリング
これらの各タイプについて簡単に説明します。
1. パーティショニング手法は、最も簡単なクラスタリング アルゴリズムです。データ ポイントは、その近さに基づいてグループ化されます。一般に、これらのアルゴリズムに選択される類似性尺度は、ユークリッド距離、マンハッタン距離、またはミンコフスキー距離です。データセットは所定の数のクラスターに分割され、各クラスターは値のベクトルによって参照されます。ベクトル値と比較すると、入力データ変数に違いはなく、クラスターに参加します。
これらのアルゴリズムの主な欠点は、クラスタリング機械学習システムがデータ ポイントの割り当てを開始する前に、直感的または科学的に (エルボー法を使用して) クラスターの数 k を確立する必要があることです。それにもかかわらず、これは依然として最も人気のあるタイプのクラスタリングです。 K 平均法 そして K-メドイド クラスタリングは、このタイプのクラスタリングの例です。
2. 密度ベースのクラスタリング (モデルベースの手法)
モデルベースの手法である密度ベースのクラスタリングは、データ ポイントの密度に基づいてグループを見つけます。クラスター数を事前に定義する必要があり、初期化の影響を受けやすい重心ベースのクラスタリングとは対照的に、密度ベースのクラスタリングはクラスター数を自動的に決定し、開始位置の影響を受けにくくなります。これらは、さまざまなサイズや形式のクラスターの処理に優れているため、不規則な形状や重複するクラスターを含むデータセットに最適です。これらの方法は、局所的な密度に焦点を当てて、密なデータ領域と疎なデータ領域の両方を管理し、さまざまな形態のクラスターを区別できます。
対照的に、K 平均法のような重心ベースのグループ化では、任意の形状のクラスターを見つけるのが困難です。事前に設定されたクラスター要件の数と、重心の初期位置に対する非常に敏感なため、結果は異なる場合があります。さらに、重心ベースのアプローチでは球状または凸状のクラスターが生成される傾向があるため、複雑または不規則な形状のクラスターを処理する能力が制限されます。結論として、密度ベースのクラスタリングは、クラスタ サイズを自律的に選択し、初期化に対する回復力があり、さまざまなサイズと形式のクラスタを正常にキャプチャすることにより、セントロイド ベースの手法の欠点を克服します。最も一般的な密度ベースのクラスタリング アルゴリズムは次のとおりです。 DBSCAN 。
3. 接続ベースのクラスタリング (階層型クラスタリング)
関連するデータ ポイントを階層クラスターに組み立てる方法は、階層クラスタリングと呼ばれます。各データ ポイントは最初は個別のクラスターとして考慮され、その後、最も類似したクラスターと結合されて、すべてのデータ ポイントを含む 1 つの大きなクラスターが形成されます。
アイテムの類似性に基づいて、アイテムのコレクションをどのように配置するかを考えてください。階層クラスタリングを使用すると、各オブジェクトはツリーの根元にある独自のクラスターとして開始され、樹状図 (ツリー状の構造) が作成されます。アルゴリズムがオブジェクトが互いにどれだけ似ているかを調べた後、クラスターの最も近いペアが結合されて、より大きなクラスターになります。すべてのオブジェクトがツリーの最上位の 1 つのクラスターに収まると、マージ プロセスは完了します。さまざまな粒度レベルを探索することは、階層クラスタリングの楽しい点の 1 つです。特定の数のクラスターを取得するには、 樹状図 特定の高さで。クラスター内にある 2 つのオブジェクトが類似しているほど、それらのオブジェクトの距離は近くなります。これは、家系図に従ってアイテムを分類することに似ています。家系図では、最も近い親戚が集まっており、より幅広い枝はより一般的なつながりを示します。階層的クラスタリングには 2 つのアプローチがあります。
- 分裂的クラスタリング : これはトップダウンのアプローチに従い、ここではすべてのデータ ポイントを 1 つの大きなクラスターの一部とみなして、このクラスターを小さなグループに分割します。
- 凝集クラスタリング : これはボトムアップのアプローチに従っており、ここではすべてのデータ ポイントが個々のクラスターの一部であると考えられ、その後、これらのクラスターがまとめられて、すべてのデータ ポイントを含む 1 つの大きなクラスターが作成されます。
4. 分散ベースのクラスタリング
分布ベースのクラスタリングを使用すると、データ内の同じ確率分布 (ガウス分布、二項分布など) に該当する傾向に従ってデータ ポイントが生成され、編成されます。データ要素は、統計分布に基づく確率ベースの分布を使用してグループ化されます。クラスター内に存在する可能性が高いデータ オブジェクトが含まれます。データ ポイントは、すべてのクラスターに存在するクラスターの中心点から遠ざかるほど、クラスターに含まれる可能性が低くなります。
密度および境界ベースのアプローチの顕著な欠点は、一部のアルゴリズムに対して事前にクラスターを指定する必要があり、主にアルゴリズムの大部分に対してクラスター形式を定義する必要があることです。少なくとも 1 つのチューニングまたはハイパー パラメータを選択する必要があります。これは簡単なはずですが、間違った場合は予期せぬ影響が生じる可能性があります。分布ベースのクラスタリングは、柔軟性、精度、クラスタ構造の点で、近接ベースおよび重心ベースのクラスタリング アプローチよりも明確な利点があります。重要な問題は、それを避けるために、 過学習 、多くのクラスタリング手法は、シミュレートされたデータや製造されたデータ、またはデータ ポイントの大部分が確実に事前設定された分布に属している場合にのみ機能します。最も一般的な分散ベースのクラスタリング アルゴリズムは次のとおりです。 混合ガウスモデル 。
さまざまな分野でのクラスタリングの応用:
- マーケティング: マーケティング目的で顧客セグメントを特徴づけ、発見するために使用できます。
- 生物学: さまざまな種類の植物や動物を分類するために使用できます。
- ライブラリ: トピックや情報に基づいてさまざまな書籍をクラスタリングする際に使用されます。
- 保険: これは、顧客とそのポリシーを確認し、不正行為を特定するために使用されます。
- 都市計画: これは、家のグループを作成し、地理的位置や存在するその他の要因に基づいてその価値を研究するために使用されます。
- 地震の研究: 地震の影響を受けた地域を知ることで、危険なゾーンを判断できます。
- 画像処理 : クラスタリングを使用すると、類似した画像をグループ化し、内容に基づいて画像を分類し、画像データ内のパターンを識別できます。
- 遺伝学: クラスタリングは、同様の発現パターンを持つ遺伝子をグループ化し、生物学的プロセスで連携して機能する遺伝子ネットワークを特定するために使用されます。
- ファイナンス: クラスタリングは、顧客の行動に基づいて市場セグメントを特定し、株式市場データのパターンを特定し、投資ポートフォリオのリスクを分析するために使用されます。
- 顧客サービス: クラスタリングは、顧客からの問い合わせや苦情をカテゴリにグループ化し、共通の問題を特定し、対象を絞ったソリューションを開発するために使用されます。
- 製造業 : クラスタリングは、類似した製品をグループ化し、生産プロセスを最適化し、製造プロセスの欠陥を特定するために使用されます。
- 医学的診断: クラスタリングは、同様の症状や病気を持つ患者をグループ化するために使用され、正確な診断と効果的な治療法の特定に役立ちます。
- 不正行為の検出: クラスタリングは、金融取引における疑わしいパターンや異常を特定するために使用され、詐欺やその他の金融犯罪の検出に役立ちます。
- トラフィック分析: クラスタリングは、ピーク時間、ルート、速度などの類似パターンの交通データをグループ化するために使用され、交通計画やインフラストラクチャの改善に役立ちます。
- ソーシャルネットワーク分析: クラスタリングは、ソーシャル ネットワーク内のコミュニティやグループを識別するために使用され、社会的な行動、影響力、傾向を理解するのに役立ちます。
- サイバーセキュリティ: クラスタリングは、ネットワーク トラフィックやシステム動作の類似したパターンをグループ化するために使用され、サイバー攻撃の検出と防止に役立ちます。
- 気候分析: クラスタリングは、気温、降水量、風などの類似したパターンの気候データをグループ化するために使用され、気候変動とその環境への影響を理解するのに役立ちます。
- スポーツ分析: クラスタリングは、プレーヤーまたはチームのパフォーマンス データの類似パターンをグループ化するために使用されます。これは、プレーヤーまたはチームの長所と短所を分析し、戦略的な意思決定を行うのに役立ちます。
- 犯罪分析: クラスタリングは、場所、時間、種類などの類似したパターンの犯罪データをグループ化するために使用されます。これは、犯罪ホットスポットの特定、将来の犯罪傾向の予測、および犯罪防止戦略の改善に役立ちます。
結論
この記事では、クラスタリング、その種類、そして現実世界におけるアプリケーションについて説明しました。教師なし学習でカバーすべきことはさらに多くあり、クラスター分析は最初のステップにすぎません。この記事は、クラスタリング アルゴリズムを開始し、ポートフォリオに追加できる新しいプロジェクトを取得するのに役立ちます。
クラスタリングに関するよくある質問 (FAQ)
Q. 最適なクラスタリング方法は何ですか?
上位 10 個のクラスタリング アルゴリズムは次のとおりです。
- K 平均法クラスタリング
- 階層的クラスタリング
- DBSCAN (ノイズを含むアプリケーションの密度ベースの空間クラスタリング)
- 混合ガウスモデル (GMM)
- 凝集クラスタリング
- スペクトルクラスタリング
- 平均シフト クラスタリング
- アフィニティの伝播
- OPTICS (クラスタリング構造を識別するための順序付けポイント)
- Birch (階層を使用したバランスのとれた反復的リダクションとクラスタリング)
Q. クラスタリングと分類の違いは何ですか?
クラスタリングと分類の主な違いは、分類は教師あり学習アルゴリズムであるのに対し、クラスタリングは教師なし学習アルゴリズムであることです。つまり、ターゲット変数のないデータセットにクラスタリングを適用します。
Q. クラスタリング分析の利点は何ですか?
クラスター分析の強力な分析ツールを使用して、データを意味のあるグループに整理できます。これを使用すると、セグメントを正確に特定し、隠れたパターンを見つけて、意思決定を改善できます。
Q. 最も高速なクラスタリング方法はどれですか?
K 平均法クラスタリングは、その単純さと計算効率により、最も高速なクラスタリング手法であると考えられています。データ ポイントを最も近いクラスターの重心に繰り返し割り当てるため、次元が低く、クラスターの数が中程度の大規模なデータセットに適しています。
Q. クラスタリングの制限は何ですか?
クラスタリングの制限には、初期条件に対する感度、パラメータの選択への依存、最適なクラスタ数を決定する難しさ、高次元またはノイズの多いデータの処理に関する課題などが含まれます。
Q. クラスタリングの結果の品質は何に依存しますか?
クラスタリング結果の品質は、アルゴリズムの選択、距離メトリック、クラスター数、初期化方法、データ前処理技術、クラスター評価メトリック、ドメイン知識などの要因によって異なります。これらの要素は集合的に、クラスタリング結果の有効性と精度に影響を与えます。