ご存知のとおり、教師あり機械学習アルゴリズムは、回帰アルゴリズムと分類アルゴリズムに大別できます。回帰アルゴリズムでは、連続値の出力を予測しましたが、カテゴリ値を予測するには、分類アルゴリズムが必要です。
分類アルゴリズムとは何ですか?
分類アルゴリズムは、トレーニング データに基づいて新しい観測のカテゴリを識別するために使用される教師あり学習手法です。分類では、プログラムは指定されたデータセットまたは観測値から学習し、新しい観測値をいくつかのクラスまたはグループに分類します。のような、 はいまたはいいえ、0 または 1、スパムまたはスパムではない、猫または犬、 クラスは、ターゲット/ラベル、またはカテゴリとして呼び出すことができます。
ローマ数字チャート 1 100
回帰とは異なり、分類の出力変数は、「緑か青」、「果物か動物」などの値ではなくカテゴリです。分類アルゴリズムは教師あり学習手法であるため、ラベル付きの入力データを受け取ります。対応する出力を伴う入力が含まれていることを意味します。
分類アルゴリズムでは、離散出力関数 (y) が入力変数 (x) にマッピングされます。
y=f(x), where y = categorical output
ML 分類アルゴリズムの最良の例は次のとおりです。 電子メールスパム検出器 。
分類アルゴリズムの主な目的は、特定のデータセットのカテゴリを識別することであり、これらのアルゴリズムは主にカテゴリ データの出力を予測するために使用されます。
分類アルゴリズムは、以下の図を使用するとよりよく理解できます。以下の図には、クラス A とクラス B の 2 つのクラスがあります。これらのクラスは、互いに似た機能と他のクラスとは異なる機能を持っています。
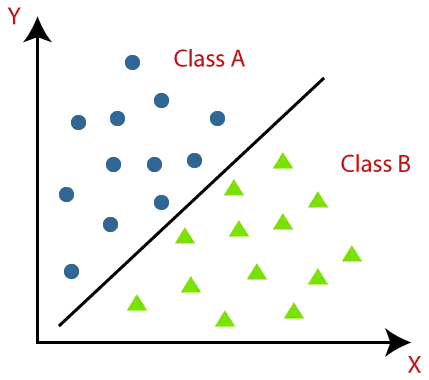
データセットに分類を実装するアルゴリズムは、分類子として知られています。分類には次の 2 種類があります。
例: はいまたはいいえ、男性または女性、スパムまたは非スパム、猫または犬など。
例: 作物の種類の分類、音楽の種類の分類。
分類問題の学習者:
分類問題には、次の 2 種類の学習者がいます。
例: K-NN アルゴリズム、ケースベースの推論
ML 分類アルゴリズムの種類:
分類アルゴリズムは、主に 2 つのカテゴリにさらに分類できます。
- ロジスティック回帰
- サポートベクターマシン
- K最近傍法
- カーネルSVM
- ナイーブ・ベイズ
- デシジョン ツリーの分類
- ランダムフォレスト分類
注: 上記のアルゴリズムについては後の章で学習します。
分類モデルの評価:
モデルが完成したら、そのパフォーマンスを評価する必要があります。それは分類モデルまたは回帰モデルのいずれかです。したがって、分類モデルを評価するには、次の方法があります。
1. 対数損失またはクロスエントロピー損失:
- これは、出力が 0 と 1 の間の確率値である分類器のパフォーマンスを評価するために使用されます。
- 優れたバイナリ分類モデルの場合、対数損失の値は 0 に近いはずです。
- 予測値が実際の値から乖離すると、対数損失の値が増加します。
- 対数損失が低いほど、モデルの精度が高いことを表します。
- 二項分類の場合、クロスエントロピーは次のように計算できます。
?(ylog(p)+(1?y)log(1?p))
ここで、y = 実際の出力、p = 予測された出力。
ジャワプリント
2. 混同マトリックス:
- 混同行列は出力として行列/テーブルを提供し、モデルのパフォーマンスを説明します。
- 誤差行列とも呼ばれます。
- マトリックスは、正しい予測と不正確な予測の合計数を含む、要約された形式の予測結果で構成されます。マトリックスは以下の表のようになります。
| 実際の陽性 | 実際のマイナス | |
|---|---|---|
| 陽性予測 | 真陽性 | 誤検知 |
| 陰性の予測 | 偽陰性 | トゥルーネガティブ |

3. AUC-ROC 曲線:
- ROC カーブの略称 受信機動作特性曲線 AUC は 曲線下の面積 。
- これは、さまざまなしきい値での分類モデルのパフォーマンスを示すグラフです。
- マルチクラス分類モデルのパフォーマンスを視覚化するために、AUC-ROC 曲線を使用します。
- ROC 曲線は TPR と FPR でプロットされます。Y 軸は TPR (真陽性率)、X 軸は FPR (偽陽性率) です。
分類アルゴリズムの使用例
分類アルゴリズムはさまざまな場所で使用できます。以下に、分類アルゴリズムの一般的な使用例をいくつか示します。
- 電子メールのスパム検出
- 音声認識
- がん腫瘍細胞の同定。
- 医薬品の分類
- 生体認証など