- 距離ベクトル アルゴリズムは動的アルゴリズムです。
- 主に ARPANET や RIP で使用されます。
- 各ルーターは、として知られる距離テーブルを維持します。 ベクター 。
距離ベクトル ルーティング アルゴリズムの動作を理解するための 3 つの鍵:
距離ベクトル ルーティング アルゴリズム
しましょうバツ(y) は、ノード x からノード y までの最小コストのパスのコストです。最小コストはベルマン・フォード方程式によって関係付けられます。
d<sub>x</sub>(y) = min<sub>v</sub>{c(x,v) + d<sub>v</sub>(y)} どこ minv は、すべての近傍 x に対して取られる方程式です。 x から v に移動した後、v から y への最小コストのパスを考慮すると、パスのコストは c(x,v)+d になります。で(y)。 x から y までの最小コストは c(x,v)+d の最小値ですで(y) すべての隣人を引き継いだ。
距離ベクトル ルーティング アルゴリズムを使用すると、ノード x には次のルーティング情報が含まれます。
- 各近傍 v のコスト c(x,v) は、x から直接接続された近傍 v までのパス コストです。
- 距離ベクトル x、つまり Dバツ= [ Dバツ(y) : y in N ]、すべての宛先 y へのコストが N に含まれます。
- 隣接するそれぞれの距離ベクトル、つまり Dで= [ Dで(y) : x の各近傍 v に対する y in N ]。
距離ベクトル ルーティングは、ノード x がその距離ベクトルのコピーをすべての隣接ノードに送信する非同期アルゴリズムです。ノード x が隣接するベクトル v の 1 つから新しい距離ベクトルを受け取ると、ノード x は v の距離ベクトルを保存し、ベルマン・フォード方程式を使用して自身の距離ベクトルを更新します。方程式は以下のようになります。
HTMLからjs関数を呼び出す
d<sub>x</sub>(y) = min<sub>v</sub>{ c(x,v) + d<sub>v</sub>(y)} for each node y in N ノード x は、上記の方程式を使用して自身の距離ベクトル テーブルを更新し、その更新されたテーブルをすべての近隣ノードに送信して、各ノードが自身の距離ベクトルを更新できるようにします。
アルゴリズム
At each node x, <p> <strong>Initialization</strong> </p> for all destinations y in N: D<sub>x</sub>(y) = c(x,y) // If y is not a neighbor then c(x,y) = ∞ for each neighbor w D<sub>w</sub>(y) = ? for all destination y in N. for each neighbor w send distance vector D<sub>x</sub> = [ D<sub>x</sub>(y) : y in N ] to w <strong>loop</strong> <strong>wait</strong> (until I receive any distance vector from some neighbor w) for each y in N: D<sub>x</sub>(y) = minv{c(x,v)+D<sub>v</sub>(y)} If D<sub>x</sub>(y) is changed for any destination y Send distance vector D<sub>x</sub> = [ D<sub>x</sub>(y) : y in N ] to all neighbors <strong>forever</strong> 注: 距離ベクトル アルゴリズムでは、ノード x は、直接リンクされた 1 つのノードでコストの変化を確認したとき、または近隣ノードからベクトルの更新を受信したときに、そのテーブルを更新します。
例を通して理解しましょう:
情報の共有
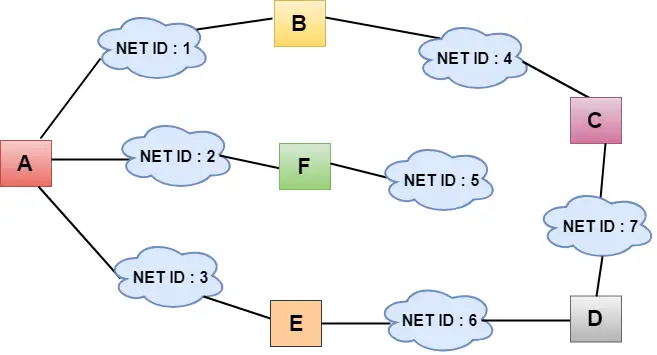
- 上の図では、それぞれの雲がネットワークを表し、雲の中の数字がネットワーク ID を表しています。
- すべての LAN はルーターによって接続されており、A、B、C、D、E、F というラベルの付いたボックスで表されます。
- 距離ベクトル ルーティング アルゴリズムは、すべてのリンクのコストを 1 単位と想定することでルーティング プロセスを簡素化します。したがって、送信効率は、宛先に到達するまでのリンクの数によって測定できます。
- ディスタンス ベクトル ルーティングでは、コストはホップ数に基づきます。

上の図では、ルーターがすぐ隣のルーターに知識を送信していることがわかります。隣接者は、この知識を自身の知識に追加し、更新されたテーブルを自身の隣接者に送信します。このようにして、ルーターは独自の情報に加えて、近隣ルーターに関する新しい情報を取得します。
ルーティングテーブル
次の 2 つのプロセスが発生します。
- テーブルの作成
- テーブルの更新
テーブルの作成
最初に、ネットワーク ID、コスト、ネクスト ホップなど、少なくとも 3 種類の情報を含むルーティング テーブルがルーターごとに作成されます。


- 上の図では、すべてのルーターの元のルーティング テーブルが示されています。ルーティング テーブルでは、最初の列はネットワーク ID を表し、2 番目の列はリンクのコストを表し、3 番目の列は空です。
- これらのルーティング テーブルはすべての近隣ノードに送信されます。
例えば:
A sends its routing table to B, F & E. B sends its routing table to A & C. C sends its routing table to B & D. D sends its routing table to E & C. E sends its routing table to A & D. F sends its routing table to A.
テーブルの更新
- A は B からルーティング テーブルを受信すると、その情報を使用してテーブルを更新します。
- B のルーティング テーブルは、パケットがネットワーク 1 と 4 にどのように移動できるかを示しています。
- B は A ルーターの近隣ルーターであり、A から B へのパケットは 1 ホップで到達できます。したがって、B のテーブルに示されているすべてのコストに 1 が加算され、その合計が特定のネットワークに到達するためのコストになります。

- 調整後、A はこのテーブルと独自のテーブルを結合して結合テーブルを作成します。

- 結合されたテーブルには重複データが含まれる場合があります。上図では、ルータ A の結合テーブルには重複データが含まれているため、コストが最も低いデータのみが保持されます。たとえば、A は 2 つの方法でネットワーク 1 にデータを送信できます。 1 つ目は次のルーターを使用しないため、1 ホップかかります。 2 番目のホップには 2 つのホップが必要です (A から B、次に B からネットワーク 1)。最初のオプションのコストが最も低いため、それが維持され、2 番目のオプションは削除されます。

- ルーティング テーブルを作成するプロセスは、すべてのルーターに対して続行されます。すべてのルーターは近隣ルーターから情報を受信し、ルーティング テーブルを更新します。
すべてのルーターの最終的なルーティング テーブルを以下に示します。
