次のアーキテクチャは、Hive へのクエリの送信フローを説明しています。
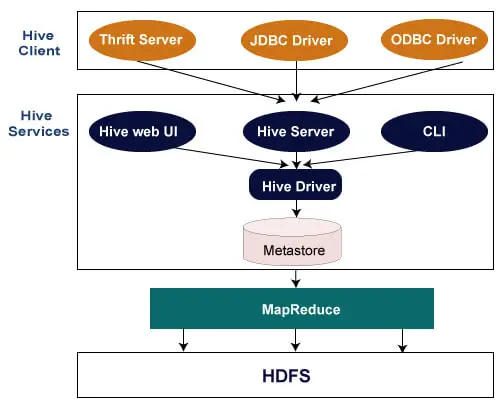
ハイブクライアント
Hive を使用すると、Java、Python、C++ などのさまざまな言語でアプリケーションを作成できます。次のようなさまざまなタイプのクライアントをサポートします。
- Thrift Server - Thrift をサポートするすべてのプログラミング言語からのリクエストに対応する、言語をまたいだサービス プロバイダー プラットフォームです。
- JDBC ドライバー - ハイブと Java アプリケーション間の接続を確立するために使用されます。 JDBC ドライバーは、クラス org.apache.hadoop.hive.jdbc.HiveDriver に存在します。
- ODBC ドライバー - ODBC プロトコルをサポートするアプリケーションが Hive に接続できるようにします。
ハイブサービス
Hive が提供するサービスは次のとおりです:-
- Hive CLI - Hive CLI (コマンド ライン インターフェイス) は、Hive クエリとコマンドを実行できるシェルです。
- Hive Web ユーザー インターフェイス - Hive Web UI は、Hive CLI の単なる代替品です。 Hive クエリとコマンドを実行するための Web ベースの GUI を提供します。
- Hive MetaStore - ウェアハウス内のさまざまなテーブルとパーティションのすべての構造情報を保存する中央リポジトリです。また、列のメタデータとその型情報、データの読み取りと書き込みに使用されるシリアライザーとデシリアライザー、およびデータが保存される対応する HDFS ファイルも含まれます。
- Hive サーバー - Apache Thrift サーバーと呼ばれます。さまざまなクライアントからのリクエストを受け入れ、それを Hive Driver に提供します。
- Hive ドライバー - Web UI、CLI、Thrift、JDBC/ODBC ドライバーなどのさまざまなソースからクエリを受け取ります。クエリをコンパイラに転送します。
- Hive コンパイラー - コンパイラーの目的は、クエリを解析し、さまざまなクエリ ブロックと式に対してセマンティック分析を実行することです。 HiveQL ステートメントを MapReduce ジョブに変換します。
- Hive 実行エンジン - オプティマイザーは、マップリデュース タスクと HDFS タスクの DAG 形式で論理プランを生成します。最終的に、実行エンジンは受信したタスクを依存関係の順序で実行します。