導入:
URL 短縮機能は、大きいサイズの URL を小さいサイズの URL にマッピングするためのハッシュの一例です。
ハッシュ関数の例:
- キー % バケット数
- 文字の ASCII 値 * PrimeNumberバツ。ここで、x = 1、2、3….n
- 独自のハッシュ関数を作成することもできますが、衝突の数が少ない適切なハッシュ関数である必要があります。
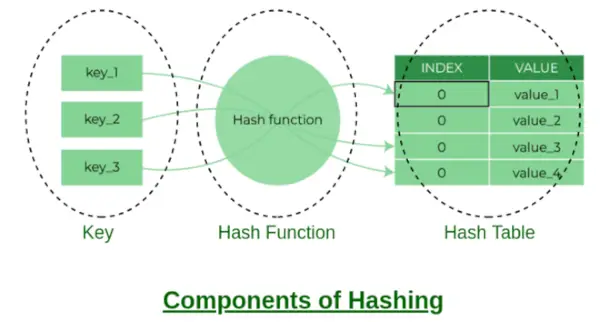
ハッシュの構成要素
バケットインデックス:
ハッシュ関数によって返される値は、別のチェーン メソッドのキーのバケット インデックスです。配列内の各インデックスはリンク リストのバケットであるため、バケットと呼ばれます。
学校はどうやって発明されたのか
焼き直し:
リハッシュは、現在のハッシュ テーブルの要素が増加したときに衝突を減らす概念です。これは 2 倍のサイズの新しい配列を作成し、以前の配列要素をそこにコピーします。これは C++ の Vector の内部動作に似ています。明らかに、ハッシュ関数は、容量が増加したときに何らかの変更を反映する必要があるため、動的である必要があります。ハッシュ関数にはハッシュ テーブルの容量が含まれているため、前の配列からキー値をコピーすると、ハッシュ関数はハッシュ テーブルの容量 (バケット) に依存するため、異なるバケット インデックスを与えます。一般に、負荷係数の値が 0.5 より大きい場合、再ハッシュが行われます。
- 配列のサイズを 2 倍にします。
- 以前の配列の要素を新しい配列にコピーします。各ノードを新しい配列に再度コピーするときにハッシュ関数を使用するため、衝突が軽減されます。
- メモリから前の配列を削除し、ハッシュ マップの内部配列ポインタがこの新しい配列を指すようにします。
- 一般に、負荷係数 = ハッシュ マップ内の要素の数 / バケットの総数 (容量) となります。
衝突:
衝突とは、バケット インデックスが空でない場合の状況です。これは、リンクされたリストのヘッドがそのバケット インデックスに存在することを意味します。同じバケット インデックスにマップされる値が 2 つ以上あります。
プログラムの主な機能
- 挿入
- 検索
- ハッシュ関数
- 消去
- 焼き直し
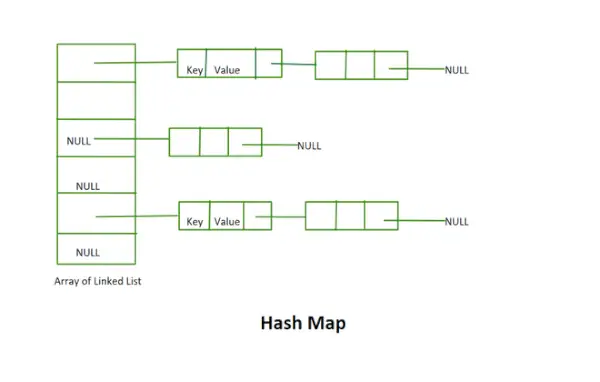
ハッシュマップ
リハッシュなしの実装:
C
#include> #include> #include> // Linked List node> struct> node {> >// key is string> >char>* key;> >// value is also string> >char>* value;> >struct> node* next;> };> // like constructor> void> setNode(>struct> node* node,>char>* key,>char>* value)> {> >node->キー = キー;>> >node->値 = 値;>>' ;> };> struct> hashMap {> >// Current number of elements in hashMap> >// and capacity of hashMap> >int> numOfElements, capacity;> >// hold base address array of linked list> >struct> node** arr;> };> // like constructor> void> initializeHashMap(>struct> hashMap* mp)> {> >// Default capacity in this case> >mp->容量 = 100;>> >// array of size = 1> >mp->arr = (>>struct> node**)>malloc>(>sizeof>(>struct> node*)> >* mp->容量);>> ;> }> int> hashFunction(>struct> hashMap* mp,>char>* key)> {> >int> bucketIndex;> >int> sum = 0, factor = 31;> >for> (>int> i = 0; i <>strlen>(key); i++) {> >// sum = sum + (ascii value of> >// char * (primeNumber ^ x))...> >// where x = 1, 2, 3....n> >sum = ((sum % mp->容量)> >+ (((>int>)key[i]) * factor) % mp->容量)> >% mp->容量;>> >// number....(prime> >// number) ^ x> >factor = ((factor % __INT16_MAX__)> >* (31 % __INT16_MAX__))> >% __INT16_MAX__;> >}> >bucketIndex = sum;> >return> bucketIndex;> }> void> insert(>struct> hashMap* mp,>char>* key,>char>* value)> {> >// Getting bucket index for the given> >// key - value pair> >int> bucketIndex = hashFunction(mp, key);> >struct> node* newNode = (>struct> node*)>malloc>(> >// Creating a new node> >sizeof>(>struct> node));> >// Setting value of node> >setNode(newNode, key, value);> >// Bucket index is empty....no collision> >if> (mp->arr[bucketIndex] == NULL) {> >mp->arr[bucketIndex] = newNode;>> >}> >// Collision> >else> {> >// Adding newNode at the head of> >// linked list which is present> >// at bucket index....insertion at> >// head in linked list> >newNode->next = mp->arr[bucketIndex];>> >mp->arr[bucketIndex] = newNode;>> >}> >return>;> }> void> delete> (>struct> hashMap* mp,>char>* key)> {> >// Getting bucket index for the> >// given key> >int> bucketIndex = hashFunction(mp, key);> >struct> node* prevNode = NULL;> >// Points to the head of> >// linked list present at> >// bucket index> >struct> node* currNode = mp->arr[バケットインデックス];>> >while> (currNode != NULL) {> >// Key is matched at delete this> >// node from linked list> >if> (>strcmp>(key, currNode->キー) == 0) {> >// Head node> >// deletion> >if> (currNode == mp->arr[bucketIndex]) {>> >mp->arr[bucketIndex] = currNode->next;>> >}> >// Last node or middle node> >else> {> >prevNode->next = currNode->next;>> >}> >free>(currNode);> >break>;> >}> >prevNode = currNode;> >currNode = currNode->次へ;>> >return>;> }> char>* search(>struct> hashMap* mp,>char>* key)> {> >// Getting the bucket index> >// for the given key> >int> bucketIndex = hashFunction(mp, key);> >// Head of the linked list> >// present at bucket index> >struct> node* bucketHead = mp->arr[バケットインデックス];>> >while> (bucketHead != NULL) {> >// Key is found in the hashMap> >if> (bucketHead->キー == キー) {>> >return> bucketHead->値;>>' >bucketHead = bucketHead->次へ;>> >// If no key found in the hashMap> >// equal to the given key> >char>* errorMssg = (>char>*)>malloc>(>sizeof>(>char>) * 25);> >errorMssg =>'Oops! No data found.
'>;> >return> errorMssg;> }> // Drivers code> int> main()> {> >// Initialize the value of mp> >struct> hashMap* mp> >= (>struct> hashMap*)>malloc>(>sizeof>(>struct> hashMap));> >initializeHashMap(mp);> >insert(mp,>'Yogaholic'>,>'Anjali'>);> >insert(mp,>'pluto14'>,>'Vartika'>);> >insert(mp,>'elite_Programmer'>,>'Manish'>);> >insert(mp,>'GFG'>,>'techcodeview.com'>);> >insert(mp,>'decentBoy'>,>'Mayank'>);> >printf>(>'%s
'>, search(mp,>'elite_Programmer'>));> >printf>(>'%s
'>, search(mp,>'Yogaholic'>));> >printf>(>'%s
'>, search(mp,>'pluto14'>));> >printf>(>'%s
'>, search(mp,>'decentBoy'>));> >printf>(>'%s
'>, search(mp,>'GFG'>));> >// Key is not inserted> >printf>(>'%s
'>, search(mp,>'randomKey'>));> >printf>(>'
After deletion :
'>);> >// Deletion of key> >delete> (mp,>'decentBoy'>);> >printf>(>'%s
'>, search(mp,>'decentBoy'>));> >return> 0;> }> |
>
Javaの動的配列
>
C++
雪と氷
#include> #include> // Linked List node> struct> node {> >// key is string> >char>* key;> >// value is also string> >char>* value;> >struct> node* next;> };> // like constructor> void> setNode(>struct> node* node,>char>* key,>char>* value) {> >node->キー = キー;>> >node->値 = 値;>>' ;> }> struct> hashMap {> >// Current number of elements in hashMap> >// and capacity of hashMap> >int> numOfElements, capacity;> >// hold base address array of linked list> >struct> node** arr;> };> // like constructor> void> initializeHashMap(>struct> hashMap* mp) {> >// Default capacity in this case> >mp->容量 = 100;>> >// array of size = 1> >mp->arr = (>>struct> node**)>malloc>(>sizeof>(>struct> node*) * mp->容量);>> ;> }> int> hashFunction(>struct> hashMap* mp,>char>* key) {> >int> bucketIndex;> >int> sum = 0, factor = 31;> >for> (>int> i = 0; i <>strlen>(key); i++) {> >// sum = sum + (ascii value of> >// char * (primeNumber ^ x))...> >// where x = 1, 2, 3....n> >sum = ((sum % mp->容量) + (((>> >// number....(prime> >// number) ^ x> >factor = ((factor % __INT16_MAX__) * (31 % __INT16_MAX__)) % __INT16_MAX__;> >}> >bucketIndex = sum;> >return> bucketIndex;> }> void> insert(>struct> hashMap* mp,>char>* key,>char>* value) {> >// Getting bucket index for the given> >// key - value pair> >int> bucketIndex = hashFunction(mp, key);> >struct> node* newNode = (>struct> node*)>malloc>(> >// Creating a new node> >sizeof>(>struct> node));> >// Setting value of node> >setNode(newNode, key, value);> >// Bucket index is empty....no collision> >if> (mp->arr[bucketIndex] == NULL) {> >mp->arr[bucketIndex] = newNode;>> >}> >// Collision> >else> {> >// Adding newNode at the head of> >// linked list which is present> >// at bucket index....insertion at> >// head in linked list> >newNode->next = mp->arr[bucketIndex];>> >mp->arr[bucketIndex] = newNode;>> >}> >return>;> }> void> deleteKey(>struct> hashMap* mp,>char>* key) {> >// Getting bucket index for the> >// given key> >int> bucketIndex = hashFunction(mp, key);> >struct> node* prevNode = NULL;> >// Points to the head of> >// linked list present at> >// bucket index> >struct> node* currNode = mp->arr[バケットインデックス];>> >while> (currNode != NULL) {> >// Key is matched at delete this> >// node from linked list> >if> (>strcmp>(key, currNode->キー) == 0) {> >// Head node> >// deletion> >if> (currNode == mp->arr[bucketIndex]) {>> >mp->arr[bucketIndex] = currNode->next;>> >}> >// Last node or middle node> >else> {> >prevNode->next = currNode->next;>> }> free>(currNode);> break>;> }> prevNode = currNode;> >currNode = currNode->次へ;>> return>;> }> char>* search(>struct> hashMap* mp,>char>* key) {> // Getting the bucket index for the given key> int> bucketIndex = hashFunction(mp, key);> // Head of the linked list present at bucket index> struct> node* bucketHead = mp->arr[バケットインデックス];>> while> (bucketHead != NULL) {> > >// Key is found in the hashMap> >if> (>strcmp>(bucketHead->キー、キー) == 0) {> >return> bucketHead->値;>>' > >bucketHead = bucketHead->次へ;>> char>* errorMssg = (>char>*)>malloc>(>sizeof>(>char>) * 25);> strcpy>(errorMssg,>'Oops! No data found.
'>);> return> errorMssg;> }> // Drivers code> int> main()> {> // Initialize the value of mp> struct> hashMap* mp = (>struct> hashMap*)>malloc>(>sizeof>(>struct> hashMap));> initializeHashMap(mp);> insert(mp,>'Yogaholic'>,>'Anjali'>);> insert(mp,>'pluto14'>,>'Vartika'>);> insert(mp,>'elite_Programmer'>,>'Manish'>);> insert(mp,>'GFG'>,>'techcodeview.com'>);> insert(mp,>'decentBoy'>,>'Mayank'>);> printf>(>'%s
'>, search(mp,>'elite_Programmer'>));> printf>(>'%s
'>, search(mp,>'Yogaholic'>));> printf>(>'%s
'>, search(mp,>'pluto14'>));> printf>(>'%s
'>, search(mp,>'decentBoy'>));> printf>(>'%s
'>, search(mp,>'GFG'>));> // Key is not inserted> printf>(>'%s
'>, search(mp,>'randomKey'>));> printf>(>'
After deletion :
'>);> // Deletion of key> deleteKey(mp,>'decentBoy'>);> // Searching the deleted key> printf>(>'%s
'>, search(mp,>'decentBoy'>));> return> 0;> }> |
>
>出力
Manish Anjali Vartika Mayank techcodeview.com Oops! No data found. After deletion : Oops! No data found.>
説明:
- 挿入: 指定されたバケット インデックスに存在するリンク リストの先頭にキーと値のペアを挿入します。 hashFunction: 指定されたキーのバケット インデックスを与えます。私たちの ハッシュ関数 = 文字の ASCII 値 * 素数バツ 。この場合の素数は 31 で、キー内の連続する文字の x の値は 1 から n まで増加します。削除: 指定されたキーのハッシュ テーブルからキーと値のペアを削除します。キーと値のペアを保持するリンク リストからノードを削除します。検索: 指定されたキーの値を検索します。
- この実装では、再ハッシュの概念は使用されません。これは、リンクされたリストの固定サイズの配列です。
- この例では、キーと値は両方とも文字列です。
時間の複雑さと空間の複雑さ:
ハッシュ テーブルの挿入および削除操作の時間計算量は平均して O(1) です。それを証明する数学的計算があります。
- 挿入の時間計算量: 平均的な場合、それは一定です。最悪の場合は直線的になります。検索の時間計算量: 平均的な場合、それは一定です。最悪の場合は直線的になります。削除の時間計算量: 平均的な場合、それは一定です。最悪の場合は直線的になります。空間複雑度: n 個の要素があるため O(n)。
関連記事:
- ハッシュにおける個別のチェーン衝突処理技術。