プロセスには次の 2 つのタイプがあります。
- 独立したプロセス。
- 協力プロセス。
独立したプロセスは他のプロセスの実行の影響を受けませんが、協調プロセスは他の実行中のプロセスの影響を受ける可能性があります。独立して実行されるこれらのプロセスは非常に効率的に実行されると考えることができますが、実際には、計算速度、利便性、およびモジュール性を向上させるために協調的な性質を利用できる状況が数多くあります。プロセス間通信 (IPC) は、プロセスが相互に通信し、そのアクションを同期できるようにするメカニズムです。これらのプロセス間の通信は、プロセス間の協力の方法とみなすことができます。プロセスは、次の両方を通じて相互に通信できます。
- 共有メモリ
- メッセージパッシング
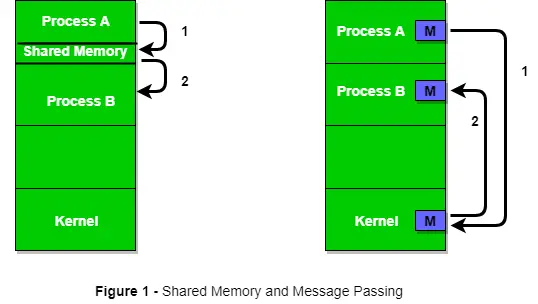
以下の図 1 は、共有メモリ方式とメッセージ パッシング方式によるプロセス間の通信の基本構造を示しています。
オペレーティング システムは両方の通信方法を実装できます。まず、共有メモリの通信方法について説明し、次にメッセージ パッシングについて説明します。共有メモリを使用したプロセス間の通信では、プロセス間で何らかの変数を共有する必要があり、それはプログラマがそれをどのように実装するかに完全に依存します。共有メモリを使用した通信の 1 つの方法は、次のように想像できます。 process1 と process2 が同時に実行され、リソースを共有するか、別のプロセスからの情報を使用するとします。 Process1 は、使用されている特定の計算またはリソースに関する情報を生成し、共有メモリに記録として保持します。 process2 が共有情報を使用する必要がある場合、共有メモリに保存されているレコードをチェックインし、process1 によって生成された情報を記録し、それに応じて動作します。プロセスは共有メモリを使用して、別のプロセスから情報をレコードとして抽出したり、特定の情報を他のプロセスに配信したりできます。
共有メモリ方式を使用したプロセス間の通信の例について説明します。
i) 共有メモリ方式
例: 生産者と消費者の問題
プロデューサーとコンシューマーという 2 つのプロセスがあります。プロデューサはいくつかのアイテムを生産し、コンシューマはそのアイテムを消費します。 2 つのプロセスは、プロデューサーによって生成されたアイテムが保存され、必要に応じてコンシューマーがそこからアイテムを消費する、バッファーとして知られる共通のスペースまたはメモリの場所を共有します。この問題には 2 つのバージョンがあります。1 つ目は、プロデューサーがアイテムを生成し続けることができ、バッファーのサイズに制限がない無制限バッファー問題として知られ、2 つ目は、境界バッファー問題として知られています。プロデューサは、コンシューマが消費するのを待ち始める前に、一定数のアイテムを生成できます。境界バッファの問題について説明します。まず、プロデューサーとコンシューマーが共通のメモリを共有し、次にプロデューサーがアイテムの生産を開始します。生成されたアイテムの合計がバッファーのサイズと等しい場合、プロデューサーは、それがコンシューマーによって消費されるまで待機します。同様に、消費者はまず商品が入手可能かどうかを確認します。利用可能なアイテムがない場合、コンシューマはプロデューサがアイテムを生産するまで待ちます。利用可能なアイテムがある場合、消費者はそれを消費します。デモする疑似コードを以下に示します。
2 つのプロセス間でデータを共有する
C
#define buff_max 25> #define mod %> >struct> item{> >// different member of the produced data> >// or consumed data> >---------> >}> > >// An array is needed for holding the items.> >// This is the shared place which will be> >// access by both process> >// item shared_buff [ buff_max ];> > >// Two variables which will keep track of> >// the indexes of the items produced by producer> >// and consumer The free index points to> >// the next free index. The full index points to> >// the first full index.> >int> free_index = 0;> >int> full_index = 0;> > |
>
>
プロデューサープロセスコード
C
item nextProduced;> > >while>(1){> > >// check if there is no space> >// for production.> >// if so keep waiting.> >while>((free_index+1) mod buff_max == full_index);> > >shared_buff[free_index] = nextProduced;> >free_index = (free_index + 1) mod buff_max;> >}> |
>
>
消費者プロセスコード
C
item nextConsumed;> > >while>(1){> > >// check if there is an available> >// item for consumption.> >// if not keep on waiting for> >// get them produced.> >while>((free_index == full_index);> > >nextConsumed = shared_buff[full_index];> >full_index = (full_index + 1) mod buff_max;> >}> |
>
>
上記のコードでは、(free_index+1) mod buff max が解放されると、プロデューサーは再び生産を開始します。これは、解放されていない場合は、コンシューマーが消費できるアイテムがまだ存在することを意味するため、その必要はありません。もっと生産するために。同様に、無料インデックスと完全インデックスが同じインデックスを指している場合、これは消費する項目がないことを意味します。
全体的な C++ 実装:
C++
#include> #include> #include> #include> #define buff_max 25> #define mod %> struct> item {> >// different member of the produced data> >// or consumed data> >// ---------> };> // An array is needed for holding the items.> // This is the shared place which will be> // access by both process> // item shared_buff[buff_max];> // Two variables which will keep track of> // the indexes of the items produced by producer> // and consumer The free index points to> // the next free index. The full index points to> // the first full index.> std::atomic<>int>>free_index(0);>>' >full_index(0);>>' producer() {> >item new_item;> >while> (>true>) {> >// Produce the item> >// ...> >std::this_thread::sleep_for(std::chrono::milliseconds(100));> >// Add the item to the buffer> >while> (((free_index + 1) mod buff_max) == full_index) {> >// Buffer is full, wait for consumer> >std::this_thread::sleep_for(std::chrono::milliseconds(100));> >}> >mtx.lock();> >// Add the item to the buffer> >// shared_buff[free_index] = new_item;> >free_index = (free_index + 1) mod buff_max;> >mtx.unlock();> >}> }> void> consumer() {> >item consumed_item;> >while> (>true>) {> >while> (free_index == full_index) {> >// Buffer is empty, wait for producer> >std::this_thread::sleep_for(std::chrono::milliseconds(100));> >}> >mtx.lock();> >// Consume the item from the buffer> >// consumed_item = shared_buff[full_index];> >full_index = (full_index + 1) mod buff_max;> >mtx.unlock();> >// Consume the item> >// ...> >std::this_thread::sleep_for(std::chrono::milliseconds(100));> >}> }> int> main() {> >// Create producer and consumer threads> >std::vectorthread>スレッド。 スレッド.emplace_back(プロデューサー); スレッド.emplace_back(consumer); // スレッドが終了するのを待ちます for (auto& thread : thread) { thread.join(); 0を返します。 }>> |
>
>
ビープラスツリー
アトミック クラスは、共有変数 free_index および full_index がアトミックに更新されるようにするために使用されることに注意してください。ミューテックスは、共有バッファがアクセスされる重要なセクションを保護するために使用されます。 sleep_for 関数は、アイテムの生産と消費をシミュレートするために使用されます。
ii) メッセージの受け渡し方法
ここで、メッセージ パッシングを介したプロセス間の通信について説明します。この方法では、プロセスは共有メモリを一切使用せずに相互に通信します。 2 つのプロセス p1 と p2 が相互に通信したい場合、次のように処理します。
- 通信リンクを確立します(すでにリンクが存在する場合、再度確立する必要はありません)。
- 基本的なプリミティブを使用してメッセージの交換を開始します。
少なくとも 2 つのプリミティブが必要です。
– 送信 (メッセージ、宛先) または 送信 (メッセージ)
– 受け取る (メッセージ、ホスト) または 受け取る (メッセージ)

メッセージ サイズは、固定サイズまたは可変サイズにすることができます。固定サイズの場合、OS 設計者にとっては簡単ですが、プログラマにとっては複雑です。可変サイズの場合、プログラマにとっては簡単ですが、OS 設計者にとっては複雑です。標準メッセージには 2 つの部分があります。 ヘッダーとボディ。
の ヘッダー部分 メッセージ タイプ、宛先 ID、送信元 ID、メッセージ長、および制御情報を格納するために使用されます。制御情報には、バッファスペースがなくなった場合の対処方法、シーケンス番号、優先度などの情報が含まれます。通常、メッセージは FIFO スタイルを使用して送信されます。
通信リンクを通過するメッセージ。
直接および間接的なコミュニケーションリンク
ここからは、通信リンクの実装方法について説明します。リンクを実装する際には、次のような点に留意する必要があります。
- リンクはどのように確立されますか?
- リンクを 3 つ以上のプロセスに関連付けることはできますか?
- 通信プロセスの各ペア間にリンクはいくつ存在できますか?
- リンクの容量はどれくらいですか?リンクが収容できるメッセージのサイズは固定ですか、それとも可変ですか?
- リンクは単方向ですか、それとも双方向ですか?
リンクには、一時的に存在できるメッセージの数を決定するある程度の容量があり、すべてのリンクには、ゼロ容量、制限付き容量、または制限なし容量のキューが関連付けられています。容量がゼロの場合、送信者は、受信者が送信者にメッセージを受信したことを通知するまで待機します。容量がゼロ以外の場合、プロセスは送信操作後にメッセージが受信されたかどうかを知りません。このためには、送信者は受信者と明示的に通信する必要があります。リンクの実装は状況に応じて異なり、直接通信リンクまたは間接通信リンクのいずれかになります。
ダイレクトコミュニケーションリンク プロセスが通信に特定のプロセス識別子を使用する場合に実装されますが、送信者を事前に特定するのは困難です。
たとえば、プリント サーバーです。
間接的なコミュニケーション メッセージのキューで構成される共有メールボックス (ポート) を介して実行されます。送信者はメッセージをメールボックスに保管し、受信者はメッセージを受け取ります。
メッセージパッシング メッセージの交換。
同期および非同期のメッセージ パッシング:
ブロックされたプロセスは、リソースが使用可能になる、または I/O 操作が完了するなど、何らかのイベントを待機しているプロセスです。 IPC は、同じコンピュータ上のプロセス間だけでなく、別のコンピュータ (ネットワーク/分散システム) で実行されているプロセス間でも可能です。どちらの場合も、メッセージの送信中またはメッセージの受信試行中にプロセスがブロックされる場合とブロックされない場合があるため、メッセージ パッシングがブロックされる場合もあれば、ブロックされない場合もあります。ブロッキングが考慮されます 同期 そして 送信をブロックする 受信者がメッセージを受信するまで送信者がブロックされることを意味します。同様に、 受信をブロックする メッセージが利用可能になるまで受信者ブロックを持ちます。ノンブロッキングを考慮 非同期 ノンブロッキング送信では、送信者がメッセージを送信して続行します。同様に、ノンブロッキング受信では、受信者は有効なメッセージまたは null を受信します。慎重に分析した結果、メッセージを別のプロセスに送信する必要がある可能性があるため、送信者にとってはメッセージの受け渡し後に非ブロッキングにする方が自然であるという結論に達することができます。ただし、送信が失敗した場合に備えて、送信者は受信者からの確認応答を期待します。同様に、受信メッセージからの情報はさらなる実行に使用される可能性があるため、受信側が受信を発行した後にブロックする方が自然です。同時に、メッセージの送信が失敗し続けると、受信者は無限に待機する必要があります。このため、メッセージ パッシングの他の可能性も検討します。基本的に推奨される組み合わせは 3 つあります。
- 送信のブロックと受信のブロック
- ノンブロッキング送信とノンブロッキング受信
- ノンブロッキング送信とブロッキング受信(主に使用)
ダイレクトメッセージパッシングでは , 通信を行うプロセスは、通信の受信者または送信者を明示的に指定する必要があります。
例えば send(p1, メッセージ) メッセージを p1 に送信することを意味します。
同様に、 受信(p2, メッセージ) p2からのメッセージを受信することを意味します。
この通信方法では、通信リンクが自動的に確立され、一方向または双方向のいずれかになりますが、1 つの送信者と受信者のペアの間で 1 つのリンクを使用できます。また、1 つの送信者と受信者のペアは複数のペアを所有する必要はありません。リンク。送信と受信の間の対称性と非対称性も実装できます。つまり、両方のプロセスがメッセージの送受信のためにお互いに名前を付けるか、送信者のみがメッセージを送信するために受信者に名前を付け、受信者が送信者に名前を付ける必要がありません。メッセージを受信しています。この通信方法の問題は、1 つのプロセスの名前が変更されると、この方法が機能しなくなることです。
間接メッセージパッシングの場合 、プロセスはメッセージの送受信にメールボックス (ポートとも呼ばれます) を使用します。各メールボックスには一意の ID があり、プロセスはメールボックスを共有する場合にのみ通信できます。プロセスが共通のメールボックスを共有し、単一のリンクを多くのプロセスに関連付けることができる場合にのみ、リンクが確立されます。プロセスの各ペアは複数の通信リンクを共有でき、これらのリンクは一方向または双方向の場合があります。 2 つのプロセスが間接メッセージ パッシングを通じて通信したいとすると、必要な操作は次のとおりです。メールボックスを作成し、このメールボックスをメッセージの送受信に使用し、その後メールボックスを破棄します。使用される標準プリミティブは次のとおりです。 メッセージを送ります) これは、メッセージをメールボックス A に送信することを意味します。メッセージを受信するためのプリミティブも同様に機能します。 受信しました (A、メッセージ) 。このメールボックスの実装には問題があります。同じメールボックスを共有するプロセスが 3 つ以上あり、プロセス p1 がメールボックスにメッセージを送信すると仮定します。どのプロセスが受信者になりますか?これは、2 つのプロセスのみが 1 つのメールボックスを共有できるように強制するか、特定の時間に 1 つのプロセスのみが受信を実行できるように強制するか、任意のプロセスをランダムに選択して送信者に受信者について通知することで解決できます。メールボックスは、単一の送信者/受信者のペアに対してプライベートにすることができ、複数の送信者/受信者のペア間で共有することもできます。ポートは、複数の送信者と 1 つの受信者を持つことができるメールボックスの実装です。これはクライアント/サーバー アプリケーションで使用されます (この場合、サーバーが受信側です)。ポートは受信側プロセスによって所有され、受信側プロセスの要求に応じて OS によって作成され、受信側がそれ自体を終了するときに同じ受信側プロセッサの要求に応じて破棄できます。相互排除の概念を使用して、1 つのプロセスのみが受信を実行できるように強制できます。 ミューテックスメールボックス nプロセスで共有されるものが作成されます。送信者はノンブロッキングでメッセージを送信します。受信を実行する最初のプロセスはクリティカル セクションに入り、他のすべてのプロセスはブロックされて待機します。
ここで、メッセージ パッシングの概念を使用して、プロデューサーとコンシューマーの問題について説明しましょう。プロデューサはアイテム (メッセージ内) をメールボックスに配置し、コンシューマはメールボックスに少なくとも 1 つのメッセージが存在する場合にアイテムを消費できます。コードを以下に示します。
プロデューサーコード
C
void> Producer(>void>){> > >int> item;> >Message m;> > >while>(1){> > >receive(Consumer, &m);> >item = produce();> >build_message(&m , item ) ;> >send(Consumer, &m);> >}> >}> |
>
>
消費者法
C
void> Consumer(>void>){> > >int> item;> >Message m;> > >while>(1){> > >receive(Producer, &m);> >item = extracted_item();> >send(Producer, &m);> >consume_item(item);> >}> >}> |
>
>
IPCシステムの例
- Posix : 共有メモリ方式を使用します。
- Mach : メッセージパッシングを使用します
- Windows XP : ローカル手続き呼び出しを使用したメッセージ パッシングを使用します。
クライアント/サーバー アーキテクチャでの通信:
さまざまなメカニズムがあります。
- パイプ
- ソケット
- リモート プロシージャル コール (RPC)
上記の 3 つの方法はすべて非常に概念的なものであり、個別の記事に値するため、後の記事で説明します。
参考文献:
- Galvin らによるオペレーティング システムの概念
- バルイラン大学、アリエル・J・フランクの講義ノート/ppt
プロセス間通信 (IPC) は、プロセスまたはスレッドがコンピューター上またはネットワーク上で相互に通信し、データを交換できるメカニズムです。 IPC は、さまざまなプロセスの連携とリソースの共有を可能にし、効率と柔軟性の向上につながるため、最新のオペレーティング システムの重要な側面です。
IPC の利点:
- プロセスが相互に通信してリソースを共有できるようになり、効率と柔軟性が向上します。
- 複数のプロセス間の調整が容易になり、システム全体のパフォーマンスが向上します。
- 複数のコンピュータまたはネットワークにまたがる分散システムの作成が可能になります。
- セマフォ、パイプ、ソケットなどのさまざまな同期および通信プロトコルを実装するために使用できます。
IPC の欠点:
- システムの複雑さが増し、設計、実装、デバッグが困難になります。
- プロセスが他のプロセスに属するデータにアクセスしたり変更したりできる可能性があるため、セキュリティ上の脆弱性が発生する可能性があります。
- IPC 操作によってシステム全体のパフォーマンスが低下しないように、メモリや CPU 時間などのシステム リソースを慎重に管理する必要があります。
複数のプロセスが同時に同じデータにアクセスまたは変更しようとすると、データの不整合が発生する可能性があります。 - 全体として、IPC は最新のオペレーティング システムに必要なメカニズムであり、プロセスが連携して柔軟かつ効率的な方法でリソースを共有できるようにするため、IPC の利点は欠点を上回ります。ただし、潜在的なセキュリティ脆弱性やパフォーマンスの問題を回避するために、IPC システムを慎重に設計および実装するように注意する必要があります。
詳細参照:
http://nptel.ac.in/courses/106108101/pdf/Lecture_Notes/Mod%207_LN.pdf
https://www.youtube.com/watch?v=lcRqHwIn5Dk