パンダ データフレーム.corr() は、Python で Pandas データフレーム内のすべての列のペアごとの相関を見つけるために使用されます。どれでも NaN 値は自動的に除外されます。数値以外の値を無視するには、パラメータ numeric_only = True を使用します。この記事では、DataFrame.corr() メソッドについて学びます。 パイソン 。
Pandas DataFrame corr() メソッドの構文
構文: DataFrame.corr(self、method='pearson'、min_periods=1、numeric_only = False)
パラメーター:
- 方法 :
- ピアソン: 標準相関係数
- kendall: ケンダル・タウ相関係数
- スピアマン: スピアマンのランク相関
- min_periods : 有効な結果を得るために、列のペアごとに必要な観測値の最小数。現在、ピアソンとスピアマンの相関関係でのみ使用可能です
- numeric_only : 数値のみを操作するかどうか。デフォルトでは False に設定されています。
戻り値: カウント :y : データフレーム
Pandas データ相関の corr() メソッド
良好な相関関係は用途によって異なりますが、少なくとも 0.6 (または -0.6) があれば良好な相関関係と言えるでしょう。相関関係がどのように機能するかを示す簡単な例 パイソン 。
Python3
import> pandas as pd> df>=> {> >'Array_1'>: [>30>,>70>,>100>],> >'Array_2'>: [>65.1>,>49.50>,>30.7>]> }> data>=> pd.DataFrame(df)> print>(data.corr())> |
>
Javaオブジェクトからのjson
>
出力
Array_1 Array_2 Array_1 1.000000 -0.990773 Array_2 -0.990773 1.000000>
サンプルデータフレームの作成
データフレームの最初の 10 行を印刷します。
注記: 変数とそれ自体の相関関係は 1 です。コードで使用される CSV ファイルへのリンクについては、 ここ
Python3
# importing pandas as pd> import> pandas as pd> # Making data frame from the csv file> df>=> pd.read_csv(>'nba.csv'>)> # Printing the first 10 rows of the data frame for visualization> df[:>10>]> |
>
>
Javaのnullチェック
出力

Python Pandas DataFrame corr() メソッドの例
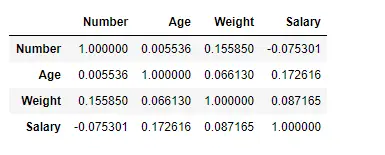
pearson メソッドを使用して列間の相関関係を見つける
ここでは、corr() 関数を使用して、「ピアソン」メソッドを使用してデータフレーム内の列間の相関関係を見つけます。データフレームには数値列が 4 つしかありません。出力データフレームは、任意のセルについて、行変数と列変数の相関がセルの値であると解釈できます。前述したように、変数とそれ自体の相関は 1 です。そのため、対角値はすべて 1.00 になります。
Python3
vlcはyoutubeからビデオをダウンロードします
# To find the correlation among> # the columns using pearson method> df.corr(method>=>'pearson'>)> |
>
>
出力
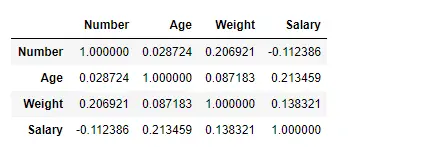
Kendall メソッドを使用して列間の相関関係を見つける
Pandas df.corr() 関数を使用して、「kendall」メソッドを使用してデータフレーム内の列間の相関関係を見つけます。出力データフレームは、任意のセルについて、行変数と列変数の相関がセルの値であると解釈できます。前述したように、変数とそれ自体の相関は 1 です。そのため、対角値はすべて 1.00 になります。
Python3
# importing pandas as pd> import> pandas as pd> # Making data frame from the csv file> df>=> pd.read_csv(>'nba.csv'>)> # To find the correlation among> # the columns using kendall method> df.corr(method>=>'kendall'>)> |
等価法則
>
>
出力