動物園の飼育員 は、分散アプリケーション用の分散オープンソース調整サービスです。これは、同期、構成保守、グループと名前付けのための高レベルのサービスを実装するための単純なプリミティブのセットを公開します。
分散システムでは、相互に通信し、動作を調整する必要がある複数のノードまたはマシンが存在します。 ZooKeeper は、これらのノードが互いを認識し、それらのアクションを調整できるようにする方法を提供します。これは、と呼ばれるデータ ノードの階層ツリーを維持することによって行われます。 Zノード 、データの保存と取得、および状態情報の維持に使用できます。 ZooKeeper は、分散システム内のノードのアクションを調整するために使用できる、ロック、バリア、キューなどのプリミティブのセットを提供します。また、システムの障害に対する耐性を確保するのに役立つ、リーダー選出、フェイルオーバー、リカバリなどの機能も提供します。 ZooKeeper は、Hadoop、Kafka、HBase などの分散システムで広く使用されており、多くの分散アプリケーションの不可欠なコンポーネントとなっています。
なぜそれが必要なのでしょうか?
- コーディネートサービス : 分散環境におけるサービスの統合/通信。
- 調整サービスを適切に行うのは複雑です。特に競合状態やデッドロックなどのエラーが発生しやすくなります。
- 競合状態 - 2 つ以上のシステムが何らかのタスクを実行しようとしています。
- デッドロック – 2 つ以上の操作が相互に待機している。
- 分散環境間の調整を容易にするために、開発者は、分散アプリケーションを調整サービスを最初から実装する責任から解放する必要がないように、zookeeper と呼ばれるアイデアを思いつきました。
分散システムとは何ですか?
- 複数のコンピュータ システムが 1 つの問題に取り組んでいます。
- これは、分散ミドルウェアを使用して接続された自律型コンピューターで構成されるネットワークです。
- 主な特長 : 同時実行、リソース共有、独立、グローバル、耐障害性が高く、価格/パフォーマンス比がはるかに優れています。
- 主な目標 s: 透明性、信頼性、パフォーマンス、拡張性。
- 課題 : セキュリティ、障害、調整、リソース共有。
コーディネーションチャレンジ
- 分散システムにおける調整が難しい問題なのはなぜですか?
- 多数のシステムを持つ分散アプリケーションの調整または構成管理。
- クラスターデータが保存されるマスターノード。
- ワーカー ノードまたはスレーブ ノードは、このマスター ノードからデータを取得します。
- 単一障害点。
- 同期は簡単ではありません。
- 慎重な設計と実装が必要です。
アパッチ動物園の飼育員
Apache Zookeeper は、分散システム用の分散型オープンソース調整サービスです。これは、分散アプリケーションがデータを保存し、相互に通信し、アクティビティを調整するための中心的な場所を提供します。 Zookeeper は、分散プロセスとサービスを調整するために分散システムで使用されます。シンプルなツリー構造のデータ モデル、シンプルな API、分散プロトコルを提供し、データの一貫性と可用性を確保します。 Zookeeper は信頼性と耐障害性が高く、高レベルの読み取りおよび書き込みスループットを処理できるように設計されています。
Zookeeper は Java で実装されており、分散システム、特に Hadoop エコシステムで広く使用されています。これは Apache Software Foundation プロジェクトであり、Apache License 2.0 に基づいてリリースされています。
動物園飼育員の建築
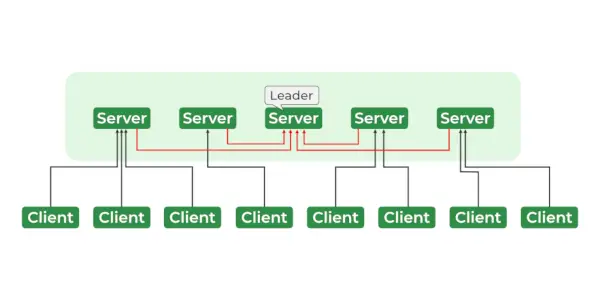
動物園飼育員サービス
ZooKeeper アーキテクチャは、ツリー状の構造に編成された znode と呼ばれるノードの階層で構成されます。各 znode はデータを保存でき、znode へのアクセスを制御する一連の権限を持っています。 znode は、ファイル システムと同様に、階層的な名前空間で編成されます。階層のルートにはルート znode があり、他のすべての znode はルート znode の子です。この階層はファイル システムの階層に似ており、各 znode は子や孫などを持つことができます。
Zookeeper の重要なコンポーネント
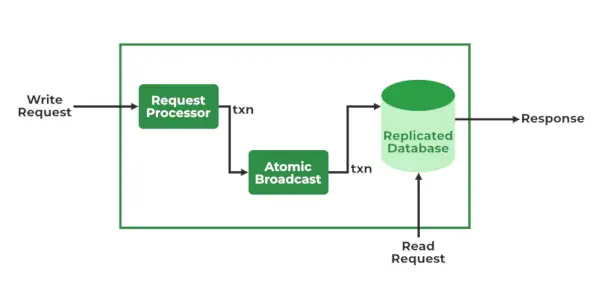
ZooKeeper サービス
- リーダーとフォロワー
- リクエストプロセッサ – リーダー ノードでアクティブになり、書き込みリクエストの処理を担当します。処理後、変更をフォロワーノードに送信します。
- アトミックブロードキャスト – リーダー ノードとフォロワー ノードの両方に存在します。変更を他のノードに送信する責任があります。
- インメモリデータベース (複製されたデータベース) - 動物園の飼育員にデータを保存する役割を果たします。すべてのノードには独自のデータベースが含まれています。データはファイル システムにも書き込まれ、クラスターに問題が発生した場合に回復できるようになります。
その他のコンポーネント
- クライアント – 分散アプリケーション クラスター内のノードの 1 つ。サーバーから情報にアクセスします。すべてのクライアントはサーバーにメッセージを送信して、クライアントが生きていることをサーバーに知らせます。
- サーバ – クライアントにすべてのサービスを提供します。クライアントに承認を与えます。
- アンサンブル – Zookeeper サーバーのグループ。アンサンブルを形成するために必要なノードの最小数は 3 です。
Zookeeper データ モデル
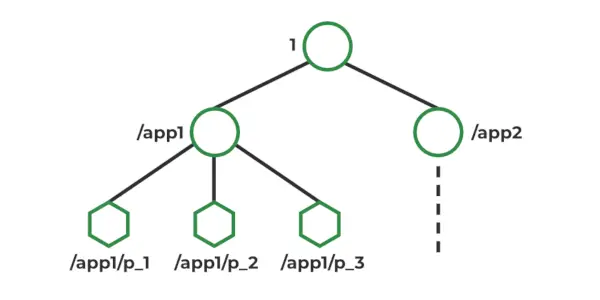
ZooKeeper データモデル
Zookeeper では、データはファイル システムと同様の階層名前空間に保存されます。名前空間内の各ノードは Znode と呼ばれ、データを保存し、子を持つことができます。 Znode は、ファイル システム内のファイルやディレクトリに似ています。 Zookeeper は、Znode を作成、読み取り、書き込み、削除するためのシンプルな API を提供します。また、ウォッチやトリガーなど、Znode に保存されているデータへの変更を検出するためのメカニズムも提供します。 Znode は、バージョン番号、ACL、タイムスタンプ、データ長を含む統計構造を維持します。
Znodeの種類 :
- 持続性 : 明示的に削除されるまで存続します。
- 一時的な : クライアント接続がアクティブになるまでアクティブです。
- 一連 : 永続的または一時的なもの。
Hadoop に ZooKeeper が必要な理由は何ですか?
Zookeeper は、NameNode、DataNode、ResourceManager などの Hadoop クラスター内のノードを管理および調整するために使用されます。 Hadoop クラスターでは、Zookeeper は次のことに役立ちます。
- 構成情報の維持: Zookeeper は、NameNode、DataNode、および ResourceManager の場所を含む、Hadoop クラスターの構成情報を保存します。
- クラスターの状態を管理する: Zookeeper は、Hadoop クラスター内のノードの状態を追跡し、ノードに障害が発生したり使用できなくなったりしたことを検出するために使用できます。
- 分散プロセスの調整: Zookeeper を使用すると、ジョブのスケジュール設定やリソース割り当てなど、Hadoop クラスター内のノード全体で分散プロセスを調整できます。
Zookeeper は、クラスター内のノードに中央調整サービスを提供することで、Hadoop クラスターの可用性と信頼性を確保するのに役立ちます。
Hadoop の ZooKeeper はどのように機能しますか?
ZooKeeper は分散ファイル システムとして動作し、クライアントがファイル システムに対してデータを読み書きできるようにする単純な API セットを公開します。データは znode と呼ばれるツリー状の構造に保存されます。znode は、従来のファイル システムのファイルまたはディレクトリと考えることができます。 ZooKeeper はコンセンサス アルゴリズムを使用して、すべてのサーバーが Znode に保存されているデータの一貫したビューを確保できるようにします。これは、クライアントが znode にデータを書き込むと、そのデータが ZooKeeper アンサンブル内の他のすべてのサーバーに複製されることを意味します。
ZooKeeper の重要な機能の 1 つは、時計の概念をサポートできることです。ウォッチを使用すると、クライアントは、znode に保存されているデータが変更されたときの通知を登録できます。これは、ZooKeeper に保存されているデータへの変更を監視し、分散システムでそれらの変更に対応する場合に役立ちます。
Hadoop では、ZooKeeper は次のようなさまざまな目的に使用されます。
- 構成情報の保存: ZooKeeper は、複数の Hadoop コンポーネントによって共有される構成情報を保存するために使用されます。たとえば、Hadoop クラスター内の NameNode の場所や JobTracker ノードのアドレスを保存するために使用される場合があります。
- 分散同期の提供: ZooKeeper は、さまざまな Hadoop コンポーネントのアクティビティを調整し、それらが一貫した方法で連携していることを確認するために使用されます。たとえば、Hadoop クラスター内で一度に 1 つの NameNode だけがアクティブになるようにするために使用できます。
- ネーミングの維持: ZooKeeper は、Hadoop コンポーネントの一元的なネーミング サービスを維持するために使用されます。これは、分散システム内のリソースを識別して見つけるのに役立ちます。
ZooKeeper は Hadoop の重要なコンポーネントであり、さまざまなサブコンポーネントのアクティビティを調整する上で重要な役割を果たします。
Apache Zookeeper での読み取りと書き込み
ZooKeeper は、データの読み取りと書き込みのためのシンプルで信頼性の高いインターフェイスを提供します。データは、ファイル システムに似た、znode と呼ばれるノードを持つ階層名前空間に保存されます。各 znode はデータを保存し、子 znode を持つことができます。 ZooKeeper クライアントは、それぞれ getData() メソッドと setData() メソッドを使用して、これらの znode に対してデータの読み取りと書き込みを行うことができます。 ZooKeeper Java API を使用したデータの読み取りと書き込みの例を次に示します。
ジャワ
// Connect to the ZooKeeper ensemble> ZooKeeper zk =>new> ZooKeeper(>'localhost:2181'>,>3000>,>null>);> // Write data to the znode '/myZnode'> String path =>'/myZnode'>;> String data =>'hello world'>;> zk.create(path, data.getBytes(), Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);> // Read data from the znode '/myZnode'> byte>[] bytes = zk.getData(path,>false>,>null>);> String readData =>new> String(bytes);> // Prints 'hello world'> System.out.println(readData);> // Closing the connection> // to the ZooKeeper ensemble> zk.close();> |
>
>
Python3
from> kazoo.client>import> KazooClient> # Connect to ZooKeeper> zk>=> KazooClient(hosts>=>'localhost:2181'>)> zk.start()> # Create a node with some data> zk.ensure_path(>'/gfg_node'>)> zk.>set>(>'/gfg_node'>, b>'some_data'>)> # Read the data from the node> data, stat>=> zk.get(>'/gfg_node'>)> print>(data)> # Stop the connection to ZooKeeper> zk.stop()> |
>
Cの配列内の文字列
>
セッションとウォッチ
セッション
- セッション内のリクエストは FIFO 順に実行されます。
- セッションが確立されると、 セッションID クライアントに割り当てられます。
- クライアントが送信する 鼓動 セッションを有効に保つために
- セッションタイムアウトは通常ミリ秒単位で表されます
時計
- ウォッチは、クライアントが Zookeeper の変更に関する通知を受け取るためのメカニズムです。
- クライアントは特定の znode を読み取りながら監視できます。
- Znode の変更は、znode に関連付けられたデータの変更、または znode の子の変更です。
- ウォッチは 1 回だけトリガーされます。
- セッションが期限切れになると、監視も削除されます。