この記事では、ADT について学習しますが、ADT が何であるかを理解する前に、提供されているさまざまな組み込みデータ型について考えてみましょう。 int、float、double、long などのデータ型は組み込みデータ型とみなされ、加算、減算、除算、乗算などの基本的な演算を実行できます。ユーザー定義のデータ型に対する操作を定義する必要があります。これらの操作は、必要な場合にのみ定義できます。したがって、問題解決のプロセスを簡素化するために、データ構造とその操作を作成できます。このような組み込みではないデータ構造は、抽象データ型 (ADT) として知られています。
Javaオブジェクト
抽象データ型 (ADT) は、一連の値と一連の操作によって動作が定義されるオブジェクトの型 (またはクラス) です。 ADT の定義では、どのような操作が実行されるかについてのみ言及されており、これらの操作がどのように実装されるかについては言及されていません。データがメモリ内でどのように編成されるか、および操作の実装にどのようなアルゴリズムが使用されるかについては指定されていません。これは実装に依存しないビューを提供するため、抽象と呼ばれます。
本質的なものだけを提供し、詳細を隠すプロセスは、抽象化として知られています。
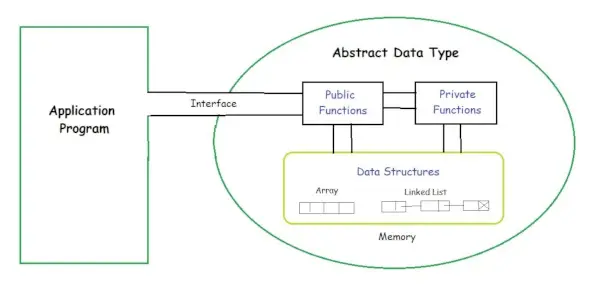
のユーザー したがって、ユーザーはデータ型で何ができるかを知る必要があるだけで、それがどのように実装されるかは知りません。 ADT は、データ型の内部構造と設計を隠すブラック ボックスと考えてください。ここで 3 つの ADT を定義します。 リスト ADT、 列 ADT。
charをint Javaに変換します
1.ADTのリスト
リストの争い
- 通常、データはキー シーケンスに従ってリストに格納されます。リストの先頭構造は次のとおりです。 カウント 、 ポインタ そして 比較関数のアドレス リスト内のデータを比較するために必要です。
- データノードには、 ポインタ データ構造と 自己参照ポインタ これはリスト内の次のノードを指します。
- の ADT 関数のリスト を以下に示します。
- get() – リストの任意の位置にある要素を返します。
- insert() – リストの任意の位置に要素を挿入します。
- Remove() – 空でないリストから最初に出現した要素を削除します。
- RemoveAt() – 空ではないリストから指定された位置にある要素を削除します。
- replace() – 任意の位置の要素を別の要素に置き換えます。
- size() – リスト内の要素の数を返します。
- isEmpty() – リストが空の場合は true を返し、それ以外の場合は false を返します。
- isFull() – リストがいっぱいの場合は true を返し、それ以外の場合は false を返します。
2. スタックADT
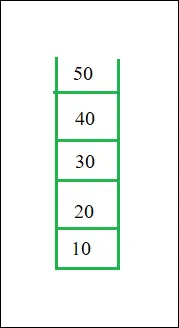
スタックのビュー
- Stack ADT 実装では、データが各ノードに格納されるのではなく、データへのポインタが格納されます。
- プログラムはメモリを割り当てます。 データ そして 住所 スタック ADT に渡されます。
- ヘッド ノードとデータ ノードは ADT にカプセル化されます。呼び出し元の関数はスタックへのポインターのみを参照できます。
- スタック ヘッド構造体には、次へのポインタも含まれています。 上 そして カウント 現在スタックにあるエントリの数。
- Push() – スタックの一方の端に要素を挿入します。top と呼ばれます。
- Pop() – スタックの先頭にある要素が空でない場合は、要素を削除して返します。
- Peak() – スタックが空でない場合、スタックの先頭にある要素を削除せずに返します。
- size() – スタック内の要素の数を返します。
- isEmpty() – スタックが空の場合は true を返し、それ以外の場合は false を返します。
- isFull() – スタックがいっぱいの場合は true を返し、それ以外の場合は false を返します。
3. キューADT
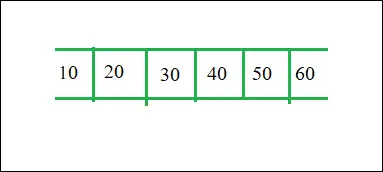
キューのビュー
- キュー抽象データ型 (ADT) は、スタック抽象データ型の基本設計に従います。
- 各ノードには、 データ そしてその リンクポインタ キュー内の次の要素に移動します。プログラムの責任は、データを保存するためのメモリを割り当てることです。
- enqueue() – キューの最後に要素を挿入します。
- dequeue() – キューが空でない場合は、キューの最初の要素を削除して返します。
- Peak() – キューが空でない場合、キューの要素を削除せずに返します。
- size() – キュー内の要素の数を返します。
- isEmpty() – キューが空の場合は true を返し、それ以外の場合は false を返します。
- isFull() – キューがいっぱいの場合は true を返し、それ以外の場合は false を返します。
ADTの特徴:
抽象データ型 (ADT) は、データとそのデータに対する操作を 1 つのユニットにカプセル化する方法です。 ADT の主な機能には次のようなものがあります。
二分木と二分探索木の違い
- 抽象化: ユーザーは、必要なものだけが提供されるため、データ構造の実装を知る必要はありません。
- より良い概念化: ADT を使用すると、現実世界をより適切に概念化できます。
- 屈強: このプログラムは堅牢であり、エラーを検出する機能があります。
- カプセル化 : ADT はデータの内部詳細を隠し、ユーザーがデータを操作するためのパブリック インターフェイスを提供します。これにより、データ構造のメンテナンスと変更が容易になります。
- データの抽象化 : ADT は、データの実装詳細からあるレベルの抽象化を提供します。ユーザーは、データに対して実行できる操作のみを知る必要があり、それらの操作がどのように実装されるかは知りません。
- データ構造の独立性 : ADT は、ADT の機能に影響を与えることなく、配列やリンク リストなどのさまざまなデータ構造を使用して実装できます。
- 情報の隠蔽: ADT は、許可されたユーザーと操作のみにアクセスを許可することで、データの整合性を保護できます。これは、エラーやデータの悪用を防ぐのに役立ちます。
- モジュール性 : ADT を他の ADT と組み合わせて、より大規模で複雑なデータ構造を形成できます。これにより、プログラミングの柔軟性とモジュール性が向上します。
全体として、ADT は、構造化された効率的な方法でデータを整理および操作するための強力なツールを提供します。
抽象データ型 (ADT) には、ソフトウェア開発で使用することを決定する際に考慮する必要があるいくつかの長所と短所があります。 ADT を使用する主な利点と欠点をいくつか示します。
利点:
- カプセル化 : ADT は、データと操作を 1 つのユニットにカプセル化する方法を提供し、データ構造の管理と変更を容易にします。
- 抽象化 : ADT を使用すると、ユーザーは実装の詳細を知らなくてもデータ構造を操作できるため、プログラミングが簡素化され、エラーが削減されます。
- データ構造の独立性 : ADT はさまざまなデータ構造を使用して実装できるため、変化するニーズや要件に簡単に適応できます。
- 情報の隠蔽 : ADT は、アクセスを制御し、不正な変更を防止することでデータの整合性を保護できます。
- モジュール性 : ADT を他の ADT と組み合わせて、より複雑なデータ構造を形成できるため、プログラミングの柔軟性とモジュール性が向上します。
短所:
- オーバーヘッド : ADT を実装すると、メモリと処理の点でオーバーヘッドが追加され、パフォーマンスに影響を与える可能性があります。
- 複雑 : ADT は、特に大規模で複雑なデータ構造の場合、実装が複雑になることがあります。
- 学ぶ Curve: ADT を使用するには、その実装と使用法に関する知識が必要であり、習得には時間と労力がかかる場合があります。
- 柔軟性が限られている: 一部の ADT は機能が制限されている場合や、すべての種類のデータ構造に適していない場合があります。
- 料金 : ADT の実装には追加のリソースと投資が必要になる場合があり、開発コストが増加する可能性があります。
全体として、ADT の利点は欠点を上回ることが多く、構造化された効率的な方法でデータを管理および操作するためにソフトウェア開発で広く使用されています。ただし、ADT を使用するかどうかを決定するときは、プロジェクトの特定のニーズと要件を考慮することが重要です。
10/50.00
これらの定義から、これらの ADT がどのように表現され、どのように操作が実行されるかが定義で指定されていないことが明確にわかります。 ADT を実装するにはさまざまな方法があります。たとえば、リスト ADT は、配列、単一リンク リスト、二重リンク リストを使用して実装できます。同様に、スタック ADT とキュー ADT は、配列またはリンク リストを使用して実装できます。