コンピューターの発明以来、人々は「」という用語を使用してきました。 データ ' 送信または保存されたコンピュータ情報を指します。ただし、注文タイプにも存在するデータがあります。データとは、紙に書かれた数字やテキスト、電子機器のメモリ内に保存されたビットやバイトの形式、または人の心の中に保存された事実のことです。世界が近代化し始めると、このデータはすべての人の日常生活の重要な側面となり、さまざまな実装により、データを異なる方法で保存できるようになりました。
データ 事実と数値のコレクション、または値のセット、または項目値の単一セットを参照する特定の形式の値です。次に、データ項目はサブ項目に分類されます。サブ項目とは、項目の単純な主形式として知られていない項目のグループです。
従業員名が First、Middle、Last の 3 つのサブ項目に分類できる例を考えてみましょう。ただし、従業員に割り当てられた ID は通常、単一のアイテムとみなされます。
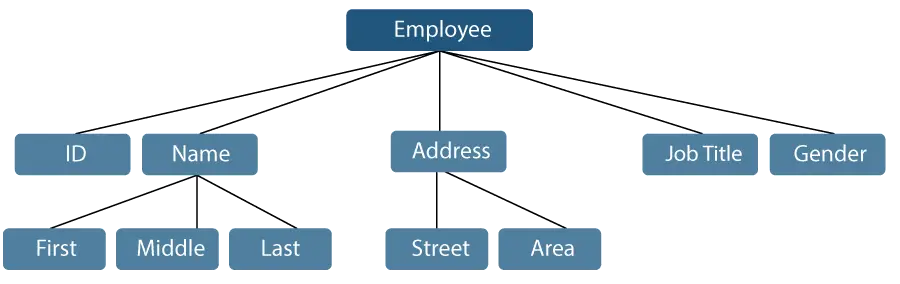
図1: データ項目の表現
上述の例では、ID、年齢、性別、姓、中、姓、番地、地域等の項目が基本データ項目である。対照的に、名前とアドレスはグループ データ項目です。
データ構造とは何ですか?
データ構造 コンピュータサイエンスの一分野です。データ構造を研究すると、プロセスやプログラムの効率を高めるためのデータの構成とデータ フローの管理を理解できるようになります。データ構造は、将来必要になったときにこれらのデータを簡単に取得して効率的に利用できるように、コンピュータのメモリにデータを保存および編成するための特別な方法です。データはさまざまな方法で管理できます。たとえば、特定のデータ構成の論理モデルまたは数学モデルはデータ構造と呼ばれます。
特定のデータ モデルの範囲は、次の 2 つの要素によって決まります。
- まず、データと実世界のオブジェクトとの明確な相関関係を反映するために、データを構造に十分にロードする必要があります。
- 第 2 に、必要なときにいつでもデータを効率的に処理できるように、構成が非常に単純である必要があります。
データ構造の例としては、配列、リンク リスト、スタック、キュー、ツリーなどが挙げられます。データ構造は、コンパイラー設計、オペレーティング システム、グラフィックス、人工知能など、コンピューター サイエンスのほぼすべての側面で広く使用されています。
データ構造は、プログラマーが効果的な方法でデータを管理できるようにするため、多くのコンピューター サイエンス アルゴリズムの主要部分です。ソフトウェアの主な目的はユーザーのデータをできるだけ早く保存および取得することであるため、プログラムまたはソフトウェアのパフォーマンスを向上させる上で重要な役割を果たします。
正規表現Javaとは何ですか
データ構造に関する基本用語
データ構造は、あらゆるソフトウェアまたはプログラムの構成要素です。プログラムに適したデータ構造を選択することは、プログラマーにとって非常に困難な作業です。
以下は、データ構造が関係する場合に必ず使用される基本的な用語です。
| 属性 | ID | 名前 | 性別 | 役職 |
|---|---|---|---|---|
| 価値観 | 1234 | ステイシー・M・ヒル | 女性 | ソフトウェア開発者 |
類似の属性を持つエンティティは、 エンティティセット 。エンティティ セットの各属性には値の範囲、つまり特定の属性に割り当てることができるすべての値のセットがあります。
「情報」という用語は、意味のあるデータまたは処理されたデータの特定の属性を持つデータに対して使用されることがあります。
データ構造の必要性を理解する
アプリケーションはますます複雑になり、データ量は日々増加しているため、データの検索、処理速度、複数のリクエストの処理などで問題が発生する可能性があります。データ構造は、データを効率的に編成、管理、保存するためのさまざまな方法をサポートしています。データ構造の助けを借りて、データ項目を簡単に横断することができます。データ構造は、効率、再利用性、抽象化を実現します。
なぜデータ構造を学ぶ必要があるのでしょうか?
- データ構造とアルゴリズムは、コンピューター サイエンスの 2 つの重要な側面です。
- データ構造を使用するとデータを整理して保存できますが、アルゴリズムを使用するとそのデータを有意義に処理できます。
- データ構造とアルゴリズムを学ぶことは、より優れたプログラマーになるのに役立ちます。
- より効果的で信頼性の高いコードを作成できるようになります。
- また、問題をより迅速かつ効率的に解決できるようになります。
データ構造の目的を理解する
データ構造は、次の 2 つの相補的な目的を満たします。
データ構造のいくつかの重要な特徴を理解する
データ構造の重要な機能には次のようなものがあります。
順序ツリーの走査
データ構造の分類
データ構造は、さまざまな方法で相互に関連する構造化された変数のセットを提供します。これは、データ要素間の関係を示し、プログラマーがデータを効率的に処理できるようにするプログラミング ツールの基礎を形成します。
データ構造は次の 2 つのカテゴリに分類できます。
- プリミティブデータ構造
- 非プリミティブデータ構造
次の図は、データ構造のさまざまな分類を示しています。

図2: データ構造の分類
プリミティブデータ構造
- これらのデータ構造は、マシンレベルの命令によって直接操作または操作できます。
- 次のような基本的なデータ型 整数、浮動小数点、文字 、 そして ブール値 プリミティブ データ構造に分類されます。
- これらのデータ型は次のように呼ばれます。 単純なデータ型 、それ以上分割できない文字が含まれているため、
非プリミティブデータ構造
- これらのデータ構造は、マシンレベルの命令によって直接操作または操作することはできません。
- これらのデータ構造の焦点は、次のいずれかのデータ要素のセットを形成することにあります。 同種の (同じデータ型) または 異質な (異なるデータ型)。
- データの構造と配置に基づいて、これらのデータ構造は 2 つのサブカテゴリに分類できます。
- 線形データ構造
- 非線形データ構造
線形データ構造
データ要素間の線形接続を保持するデータ構造は、線形データ構造として知られています。データの配置は線形に行われ、最初と最後のデータ要素を除く各要素は後続要素と先行要素で構成されます。ただし、メモリの場合は配列が連続していない可能性があるため、必ずしもそうとは限りません。
メモリ割り当てに基づいて、線形データ構造はさらに 2 つのタイプに分類されます。
の 配列 これは、サイズが固定されており、データは後で変更できるため、静的データ構造の最良の例です。
リンクされたリスト、スタック 、 そして テイルス は動的データ構造の一般的な例です
線形データ構造の種類
以下は、私たちが通常使用する線形データ構造のリストです。
1. 配列
アン 配列 同じデータ型の複数のデータ要素を 1 つの変数に収集するために使用されるデータ構造です。同じデータ型の複数の値を別々の変数名で保存する代わりに、それらすべてを 1 つの変数にまとめて保存できます。このステートメントは、プログラム内の同じデータ型のすべての値をそのデータ型の 1 つの配列に結合する必要があることを意味するものではありません。ただし、同じデータ型の特定の変数がすべて、配列に適した方法で相互に関連している場合がよくあります。
配列は要素のリストであり、各要素はリスト内で一意の位置を持ちます。配列のデータ要素は同じ変数名を共有します。ただし、それぞれには添字と呼ばれる異なるインデックス番号が付けられます。リスト内のデータ要素の位置を利用して、リストの任意のデータ要素にアクセスできます。したがって、理解すべき配列の重要な特徴は、データが連続したメモリ位置に格納され、ユーザーがそれぞれのインデックスを使用して配列のデータ要素を横断できることです。

図3. 配列
配列はさまざまなタイプに分類できます。
配列のいくつかのアプリケーション:
ターミナルカリLinux
- 同じデータ型に属するデータ要素のリストを保存できます。
- 配列は、他のデータ構造の補助記憶域として機能します。
- この配列は、固定数のバイナリ ツリーのデータ要素を格納するのにも役立ちます。
- 配列は行列のストレージとしても機能します。
2. リンクされたリスト
あ リンクされたリスト これは、データ要素のコレクションを動的に格納するために使用される線形データ構造の別の例です。このデータ構造内のデータ要素は、リンクまたはポインタを使用して接続されたノードによって表されます。各ノードには 2 つのフィールドが含まれており、情報フィールドは実際のデータで構成され、ポインタ フィールドはリスト内の後続のノードのアドレスで構成されます。リンクされたリストの最後のノードのポインタは、何も指していないため、ヌル ポインタで構成されます。配列とは異なり、ユーザーは要件に応じてリンク リストのサイズを動的に調整できます。

図4. リンクされたリスト
リンク リストはさまざまなタイプに分類できます。
リンクされたリストのいくつかの応用:
- リンク リストは、スタック、キュー、バイナリ ツリー、および事前定義されたサイズのグラフを実装するのに役立ちます。
- 動的メモリ管理のためのオペレーティング システムの機能を実装することもできます。
- リンク リストでは、数学演算の多項式の実装も可能です。
- 循環リンク リストを使用して、タスクをラウンド ロビンで実行するオペレーティング システムまたはアプリケーション機能を実装できます。
- 循環リンク リストは、ユーザーが最後のスライドが表示された後に最初のスライドに戻る必要があるスライド ショーでも役立ちます。
- Double Linked List は、Web サイトの開いたページ内を前後に移動するために、ブラウザに「進む」ボタンと「戻る」ボタンを実装するために利用されます。
3. スタック
あ スタック は、次の線形データ構造です。 LIFO (後入れ先出し) 原則により、スタックの一端 (つまり、先頭) からの挿入や削除などの操作が可能になります。スタックは、連続メモリである配列と、不連続メモリであるリンク リストを利用して実装できます。スタックの実際の例としては、本の山、カードの山、お金の山などが挙げられます。

図5. スタックの実例
上の図は、スタックの最上部への新しい本の挿入と削除など、操作が一方の端からのみ実行されるスタックの実際の例を表しています。これは、スタック内の挿入と削除はスタックの先頭からのみ実行できることを意味します。いつでもスタックの最上位にのみアクセスできます。
スタック内の主な操作は次のとおりです。

図6. スタック
スタックのいくつかのアプリケーション:
- スタックは、再帰操作の一時ストレージ構造として使用されます。
- スタックは、関数呼び出し、ネストされた操作、および延期/延期された関数の補助ストレージ構造としても利用されます。
- スタックを使用して関数呼び出しを管理できます。
- スタックは、さまざまなプログラミング言語の算術式を評価するためにも利用されます。
- スタックは、中置式を後置式に変換する場合にも役立ちます。
- スタックを使用すると、プログラミング環境で式の構文をチェックできます。
- スタックを使用して括弧を一致させることができます。
- スタックを使用して文字列を反転できます。
- スタックは、バックトラッキングに基づいて問題を解決するのに役立ちます。
- グラフおよびツリー走査での深さ優先検索でスタックを使用できます。
- スタックはオペレーティング システムの機能でも使用されます。
- スタックは、編集時の UNDO および REDO 機能でも使用されます。
4. しっぽ
あ 列 要素の挿入と削除にいくつかの制限がある、スタックに似た線形データ構造です。キューへの要素の挿入は一方の端で行われ、削除は他方の端で行われます。したがって、Queue データ構造は FIFO (先入れ先出し) 原則に従ってデータ要素を操作すると結論付けることができます。キューの実装は、配列、リンク リスト、またはスタックを使用して実行できます。キューの実例としては、チケット カウンターの列、エスカレーター、洗車場などがあります。

図7。 キューの実例
オフセット高さ
上の画像は、映画のチケット カウンターの実際の図です。これは、最初に来た顧客が常に最初にサービスを受けるキューを理解するのに役立ちます。最後に到着した顧客は間違いなく最後にサービスを受けることになります。キューの両端は開いており、さまざまな操作を実行できます。別の例としては、フードコートの列で、顧客は後端から挿入され、顧客が要求したサービスを提供した後、前端で取り除かれる場合があります。
キューの主な操作は次のとおりです。

図8。 列
キューのいくつかの応用:
- キューは通常、グラフの範囲検索操作で使用されます。
- キューは、ユーザーが押したキーを格納するキーボード バッファ キューや、プリンタで印刷されたドキュメントを格納するプリント バッファ キューなど、オペレーティング システムのジョブ スケジューラ操作でも使用されます。
- キューは、CPU スケジューリング、ジョブ スケジューリング、およびディスク スケジューリングを担当します。
- プライオリティ キューは、ブラウザでのファイルのダウンロード操作に利用されます。
- キューは、周辺機器と CPU の間でデータを転送するためにも使用されます。
- キューは、CPU のユーザー アプリケーションによって生成された割り込みの処理も担当します。
非線形データ構造
非線形データ構造は、データ要素が順番に配置されていないデータ構造です。ここでは、データの挿入と削除を線形的に実行することはできません。個々のデータ項目の間には階層関係が存在します。
非線形データ構造の種類
以下は、私たちが通常使用する非線形データ構造のリストです。
1. 木
ツリーは非線形データ構造であり、ツリーの各ノードが値と他のノード (「子」) への参照のリストを格納するノードのコレクションを含む階層です。
ツリー データ構造は、コンピュータ内のデータを整理して収集し、より効果的に利用するための特殊な方法です。これには、中心ノード、構造ノード、およびエッジを介して接続されたサブノードが含まれます。ツリーデータ構造は、根、枝、葉がつながったものであるとも言えます。

図9。 木
木はさまざまな種類に分類できます。
木の応用例:
- ツリーは、ディレクトリやファイル システムなどのコンピュータ システムの階層構造を実装します。
- ツリーは、Web サイトのナビゲーション構造を実装するためにも使用されます。
- Trees を使用すると、ハフマン コードのようなコードを生成できます。
- ツリーは、ゲーム アプリケーションでの意思決定にも役立ちます。
- ツリーは、優先度ベースの OS スケジューリング機能のための優先度キューの実装を担当します。
- ツリーは、さまざまなプログラミング言語のコンパイラーで式やステートメントを解析する役割も果たします。
- ツリーを使用して、データベース管理システム (DBMS) のインデックス作成用のデータ キーを保存できます。
- スパニング ツリーを使用すると、コンピュータおよび通信ネットワークで意思決定をルーティングできるようになります。
- ツリーは、人工知能 (AI)、ロボット工学、およびビデオ ゲーム アプリケーションに実装される経路探索アルゴリズムでも使用されます。
2. グラフ
グラフは、有限数のノードまたは頂点とそれらを接続するエッジで構成される非線形データ構造の別の例です。グラフは現実世界の問題に対処するために利用され、問題領域をソーシャル ネットワーク、回線ネットワーク、電話ネットワークなどのネットワークとして示します。たとえば、グラフのノードまたは頂点は電話ネットワーク内の 1 人のユーザーを表すことができ、エッジは電話を介したユーザー間のリンクを表します。
グラフ データ構造 G は、以下に示すように、一連の頂点 V と一連のエッジ E で構成される数学的構造とみなされます。
G = (V,E)

図10。 グラフ
上の図は、7 つの頂点 A、B、C、D、E、F、G と 10 個のエッジ [A、B]、[A、C]、[B、C]、[B、D] を持つグラフを表しています。 [B、E]、[C、D]、[D、E]、[D、F]、[E、F]、[E、G]。
頂点とエッジの位置に応じて、グラフはさまざまなタイプに分類できます。
グラフの応用例:
- グラフは、交通、旅行、通信アプリケーションでルートとネットワークを表現するのに役立ちます。
- グラフは GPS でルートを表示するために使用されます。
- グラフは、ソーシャル ネットワークやその他のネットワーク ベースのアプリケーションの相互接続を表現するのにも役立ちます。
- グラフはマッピング アプリケーションで利用されます。
- グラフは、電子商取引アプリケーションでユーザーの好みを表現する役割を果たします。
- グラフは、地方自治体の企業に生じる問題を特定するために、公共事業ネットワークでも使用されます。
- グラフは、組織内のリソースの使用状況と可用性を管理するのにも役立ちます。
- グラフは、ハイパーリンクを介したページ間の接続を表示するために、Web サイトのドキュメント リンク マップを作成するためにも使用されます。
- グラフはロボットの動作やニューラル ネットワークでも使用されます。
データ構造の基本操作
次のセクションでは、あらゆるデータ構造のデータを操作するために実行できるさまざまな種類の操作について説明します。
- コンパイル時
- ランタイム
たとえば、 malloc() 関数はC言語でデータ構造を作成するために使用されます。
抽象データ型を理解する
によると 米国国立標準技術研究所 (NIST) 、データ構造は、アルゴリズムの効率を高めるために、一般にメモリ内に配置された情報です。データ構造には、リンク リスト、スタック、キュー、ツリー、辞書が含まれます。また、人の名前や住所のような理論的な実体である場合もあります。
上記の定義から、データ構造における操作には次のものが含まれると結論付けることができます。
ビューとテーブル
- リストへの項目の追加や削除などの高度な抽象化。
- リスト内の項目を検索および並べ替えます。
- リスト内の最も優先度の高い項目にアクセスします。
データ構造がそのような操作を行うとき、それは常に、 抽象データ型 (ADT) 。
これを、データに対する操作とともにデータ要素のセットとして定義できます。 「抽象」という用語は、データとそのデータに定義されている基本的な操作が、その実装とは独立して研究されているという事実を指します。これには、データをどのように実行できるかではなく、データを使用して何ができるかが含まれます。
ADI 実装には、基本的な操作のためのデータ要素とアルゴリズムを保存するためのストレージ構造が含まれています。配列、リンク リスト、キュー、スタックなどのすべてのデータ構造は ADT の例です。
ADT を使用する利点を理解する
現実の世界では、プログラムは新しい制約や要件の結果として進化するため、プログラムを変更するには、通常、1 つまたは複数のデータ構造の変更が必要になります。たとえば、各従業員に関する詳細を追跡するために、従業員のレコードに新しいフィールドを挿入するとします。この場合、配列を Linked 構造に置き換えることでプログラムの効率を向上させることができます。このような状況では、変更された構造を利用するすべてのプロシージャを書き直すことは適切ではありません。したがって、より良い代替案は、データ構造をその実装情報から分離することです。これが、抽象データ型 (ADT) の使用の背後にある原則です。
データ構造のいくつかの応用
データ構造のいくつかの応用例を次に示します。
- データ構造は、コンピュータのメモリ内のデータの編成に役立ちます。
- データ構造は、データベース内の情報を表現するのにも役立ちます。
- データ構造を使用すると、データを検索するアルゴリズムの実装が可能になります (検索エンジンなど)。
- データ構造を使用して、データを操作するアルゴリズムを実装できます (ワード プロセッサなど)。
- データ構造 (データマイナーなど) を使用してデータを分析するアルゴリズムを実装することもできます。
- データ構造は、データを生成するアルゴリズム (乱数ジェネレーターなど) をサポートします。
- データ構造は、データを圧縮および解凍するアルゴリズム (zip ユーティリティなど) もサポートします。
- データ構造を使用して、データを暗号化および復号化するアルゴリズムを実装することもできます (セキュリティ システムなど)。
- データ構造の助けを借りて、ファイルとディレクトリを管理できるソフトウェア (ファイル マネージャーなど) を構築できます。
- データ構造を使用してグラフィックをレンダリングできるソフトウェアを開発することもできます。 (たとえば、Web ブラウザーや 3D レンダリング ソフトウェア)。
これら以外にも、前述したように、目的のソフトウェアの構築に役立つデータ構造のアプリケーションが他にもたくさんあります。