BFS と DFS の違いを説明する前に、まず BFS と DFS について別々に理解する必要があります。
BFSとは何ですか?
BFS を意味する 幅優先検索 。としても知られています レベル順序のトラバース 。 Queue データ構造は、幅優先検索のトラバーサルに使用されます。グラフ内の走査に BFS アルゴリズムを使用する場合、任意のノードをルート ノードとみなすことができます。
幅優先検索トラバーサルに関する以下のグラフを考えてみましょう。
mysqlで列の型を変更する
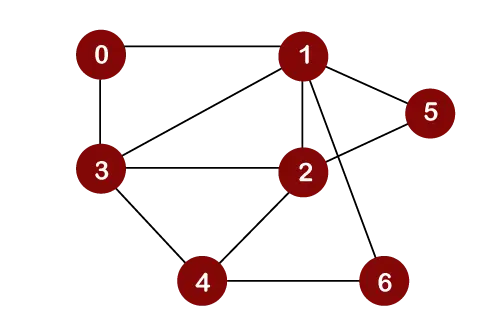
ノード 0 をルート ノードとみなすとします。したがって、トラバースはノード 0 から開始されます。

ノード 0 がキューから削除されると、出力され、ノード 0 としてマークされます。 訪問したノード。
ノード 0 がキューから削除されると、以下に示すように、ノード 0 の隣接ノードがキューに挿入されます。

これで、ノード 1 がキューから削除されます。印刷され、訪問済みノードとしてマークされます
ノード 1 がキューから削除されると、ノード 1 に隣接するすべてのノードがキューに追加されます。ノード 1 の隣接ノードは 0、3、2、6、5 です。ただし、キューには未訪問のノードのみを挿入する必要があります。ノード 3、2、6、および 5 は訪問されていないため、したがって、これらのノードは、以下に示すようにキューに追加されます。

次のノードはキュー内の 3 です。したがって、ノード 3 はキューから削除され、以下に示すように印刷され、訪問済みとしてマークされます。

ノード 3 がキューから削除されると、訪問したノードを除くノード 3 のすべての隣接ノードがキューに追加されます。ノード 3 の隣接ノードは 0、1、2、および 4 です。ノード 0、1 はすでに訪問されており、ノード 2 はキュー内に存在するため、ノード 3 の隣接ノードは 0、1、2、および 4 です。したがって、ノード 4 のみをキューに挿入する必要があります。
Javaのdoubleを文字列に変換する

ここで、キュー内の次のノードは 2 です。したがって、2 はキューから削除されます。以下に示すように、印刷され、訪問済みとしてマークされます。

ノード 2 がキューから削除されると、訪問したノードを除くノード 2 のすべての隣接ノードがキューに追加されます。ノード 2 の隣接ノードは 1、3、5、6、および 4 です。ノード 1 と 3 はすでに訪問されており、4、5、6 はすでにキューに追加されているため、ノード 2 の隣接ノードは 1、3、5、6、および 4 になります。したがって、キューにノードを挿入する必要はありません。
次の要素は 5 です。したがって、5 はキューから削除されます。以下に示すように、印刷され、訪問済みとしてマークされます。

ノード 5 がキューから削除されると、訪問ノードを除くノード 5 のすべての隣接ノードがキューに追加されます。ノード 5 の隣接ノードは 1 と 2 です。両方のノードはすでに訪問されているため、ノード 5 の隣接ノードは 1 と 2 です。したがって、キューに挿入される頂点はありません。
次のノードは 6 です。したがって、6 はキューから削除されます。以下に示すように、印刷され、訪問済みとしてマークされます。

ノード 6 がキューから削除されると、訪問ノードを除くノード 6 のすべての隣接ノードがキューに追加されます。ノード 6 の隣接ノードは 1 と 4 です。ノード 1 はすでに訪問されており、ノード 4 はすでにキューに追加されているため、ノード 6 の隣接ノードは 1 と 4 です。したがって、キューに挿入される頂点はありません。
キュー内の次の要素は 4 です。したがって、4 はキューから削除されます。これは印刷され、訪問済みとしてマークされます。
ノード 4 がキューから削除されると、訪問ノードを除くノード 4 のすべての隣接ノードがキューに追加されます。ノード 4 の隣接ノードは 3、2、6 です。すべての隣接ノードはすでに訪問されているため、次のようになります。したがって、キューに挿入される頂点はありません。
DFSとは何ですか?
DFS 深さ優先検索の略です。 DFS トラバーサルでは、LIFO (Last In First Out) 原則に基づいて動作するスタック データ構造が使用されます。 DFS では、トラバースは任意のノードから開始できます。あるいは、問題でルート ノードが言及されない限り、任意のノードをルート ノードとみなすことができます。
BFS の場合、Queue から削除された要素、削除されたノードの隣接ノードが Queue に追加されます。対照的に、DFS では、要素がスタックから削除され、削除されたノードの隣接ノードが 1 つだけスタックに追加されます。
javaを設定する
深さ優先検索トラバーサルに関する以下のグラフを考えてみましょう。

ノード 0 をルート ノードとみなします。
まず、以下に示すように要素 0 をスタックに挿入します。

ノード 0 には 2 つの隣接ノード、つまり 1 と 3 があります。ここで、トラバースに使用できる隣接ノードは 1 つまたは 3 の 1 つだけです。ノード 1 を考慮するとします。したがって、1 がスタックに挿入され、以下のように出力されます。

ここで、ノード 1 の隣接頂点を調べます。ノード 1 の未訪問の隣接頂点は 3、2、5、および 6 です。これら 4 つの頂点のいずれかを考慮できます。以下に示すように、ノード 3 をスタックに挿入するとします。

ノード 3 の未訪問の隣接頂点を考えます。ノード 3 の未訪問の隣接頂点は 2 と 4 です。頂点 2 または 4 のいずれかを選択できます。頂点 2 を取得し、以下に示すようにスタックに挿入するとします。

ノード 2 の未訪問の隣接頂点は 5 と 4 です。頂点は 5 または 4 のいずれかを選択できます。以下に示すように頂点 4 を取得し、スタックに挿入するとします。
Javaで現在の日付を取得する

次に、ノード 4 の未訪問の隣接頂点を検討します。ノード 4 の未訪問の隣接頂点はノード 6 です。したがって、要素 6 は、以下に示すようにスタックに挿入されます。

要素 6 をスタックに挿入した後、ノード 6 の未訪問の隣接頂点を調べます。ノード 6 には未訪問の隣接頂点がないため、ノード 6 を超えて移動することはできません。この場合、次のことを実行します。 後戻りする 。最上位の要素、つまり 6 は、以下に示すようにスタックからポップアウトされます。


スタックの最上位の要素は 4 です。ノード 4 の左側には未訪問の隣接頂点がないため、次のようになります。したがって、以下に示すように、ノード 4 がスタックからポップアウトされます。


スタック内の次に最上位の要素は 2 です。次に、ノード 2 の未訪問の隣接頂点を調べます。未訪問のノードが 1 つだけ、つまり 5 だけ残っているため、ノード 5 が 2 の上のスタックにプッシュされて出力されます。以下に示すように:

ここで、まだ訪問されていないノード 5 の隣接する頂点を確認します。訪問する頂点が残っていないため、以下に示すようにスタックから要素 5 をポップします。
HTMLからJavaScript関数を呼び出す

これ以上 5 に進むことはできないため、バックトラックを実行する必要があります。バックトラッキングでは、最上位の要素がスタックからポップアウトされます。最上位の要素はスタックからポップアウトされる 5 で、以下に示すようにノード 2 に戻ります。

ここで、ノード 2 の未訪問の隣接頂点をチェックします。訪問すべき隣接頂点が残っていないため、バックトラックを実行します。バックトラックでは、以下に示すように、最上位の要素、つまり 2 がスタックからポップアウトされ、ノード 3 に戻ります。


ここで、ノード 3 の未訪問の隣接頂点をチェックします。訪問すべき隣接頂点が残っていないため、バックトラックを実行します。バックトラックでは、以下に示すように、最上位の要素、つまり 3 がスタックからポップアウトされ、ノード 1 に戻ります。


要素 3 をポップアウトした後、ノード 1 の未訪問の隣接頂点をチェックします。訪問する頂点が残っていないため、ノード 1 の未訪問の隣接頂点がチェックされます。したがって、バックトラッキングが実行されます。バックトラックでは、以下に示すように、最上位の要素、つまり 1 がスタックからポップアウトされ、ノード 0 に戻ります。


まだ訪問されていないノード 0 の隣接する頂点を確認します。訪問する隣接頂点が残っていないため、バックトラッキングを実行します。この場合、以下に示すように、1 つの要素のみ、つまりスタックに残っている 0 がスタックからポップアウトされます。

上の図からわかるように、スタックは空です。したがって、ここで DFS トラバーサルを停止する必要があります。出力される要素は DFS トラバーサルの結果です。
BFS と DFS の違い
BFS と DFS の違いは次のとおりです。
| BFS | DFS | |
|---|---|---|
| 完全形 | BFS は幅優先検索の略です。 | DFS は深さ優先検索の略です。 |
| 技術 | これは、グラフ内の最短パスを見つけるための頂点ベースの手法です。 | これは、エッジに沿った頂点が最初に開始ノードから終了ノードまで探索されるため、エッジベースの手法です。 |
| 意味 | BFS は、最初に同じレベルのすべてのノードを探索し、次に次のレベルに移動するトラバーサル手法です。 | DFS は、ルート ノードからトラバーサルを開始し、未訪問の隣接ノードがないノードに到達するまでノードを可能な限り探索するトラバーサル手法でもあります。 |
| データ構造 | キュー データ構造は BFS トラバーサルに使用されます。 | BFS トラバーサルにはスタック データ構造が使用されます。 |
| 後戻り | BFS はバックトラッキングの概念を使用しません。 | DFS はバックトラッキングを使用して、未訪問のノードをすべて走査します。 |
| エッジの数 | BFS は、ソースから宛先頂点まで横断する最小数のエッジを持つ最短パスを見つけます。 | DFS では、ソース頂点から宛先頂点までトラバースするためにより多くのエッジが必要になります。 |
| 最適性 | BFS トラバーサルは、ソース頂点に近い頂点を検索する場合に最適です。 | DFS トラバーサルは、解がソース頂点から離れているグラフに最適です。 |
| スピード | BFS は DFS よりも遅いです。 | DFS は BFS よりも高速です。 |
| デシジョンツリーへの適合性 | 最初にすべての隣接ノードを探索する必要があるため、デシジョン ツリーには適していません。 | 決定木に適しています。決定に基づいて、すべての道を探索します。ゴールが見つかると、トラバースを停止します。 |
| メモリ効率が高い | DFS よりも多くのメモリを必要とするため、メモリ効率が良くありません。 | BFS よりも必要なメモリが少ないため、メモリ効率が高くなります。 |