この記事では、データ構造における BFS アルゴリズムについて説明します。幅優先検索は、ルート ノードからグラフの走査を開始し、隣接するすべてのノードを探索するグラフ走査アルゴリズムです。次に、最も近いノードを選択し、未探索のノードをすべて探索します。トラバーサルに BFS を使用している間、グラフ内の任意のノードをルート ノードと見なすことができます。
グラフをトラバースする方法は数多くありますが、その中で最も一般的に使用されるアプローチは BFS です。これは、ツリーまたはグラフ データ構造のすべての頂点を検索する再帰的アルゴリズムです。 BFS は、グラフのすべての頂点を 2 つのカテゴリ (訪問済みと非訪問) に分類します。グラフ内の 1 つのノードを選択し、その後、選択したノードに隣接するすべてのノードを訪問します。
BFS アルゴリズムの応用
幅優先アルゴリズムの適用は次のようになります。
- BFS を使用すると、特定のソースの場所から隣接する場所を見つけることができます。
- ピアツーピア ネットワークでは、すべての隣接ノードを見つけるためのトラバーサル方法として BFS アルゴリズムを使用できます。 BitTorrent、uTorrent などのほとんどの torrent クライアントは、このプロセスを使用してネットワーク内の「シード」と「ピア」を見つけます。
- BFS を Web クローラーで使用して、Web ページのインデックスを作成できます。これは、Web ページのインデックス作成に使用できる主要なアルゴリズムの 1 つです。ソース ページから移動を開始し、ページに関連付けられたリンクをたどります。ここでは、すべての Web ページがグラフ内のノードと見なされます。
- BFS は、最短パスと最小スパニング ツリーを決定するために使用されます。
- BFS は、ガベージ コレクションを複製する Cheney の手法でも使用されます。
- フォード・フルカーソン法で使用して、フロー ネットワーク内の最大流量を計算できます。
アルゴリズム
グラフを探索するための BFS アルゴリズムに含まれる手順は次のとおりです。
ステップ1: G の各ノードの SET STATUS = 1 (準備完了状態)
ステップ2: 開始ノード A をキューに入れ、その STATUS = 2 (待機状態) を設定します。
ステップ 3: QUEUE が空になるまでステップ 4 と 5 を繰り返します。
ステップ 4: ノード N をデキューします。ノード N を処理し、STATUS = 3 (処理済み状態) に設定します。
ステップ5: 準備完了状態 (STATUS = 1) にある N のすべての隣接ノードをキューに入れ、設定します
彼らのステータス = 2
(待機状態)
[ループの終わり]
ステップ6: 出口
BFSアルゴリズムの例
ここで、例を使用して BFS アルゴリズムの仕組みを理解しましょう。以下に示す例には、7 つの頂点を持つ有向グラフがあります。
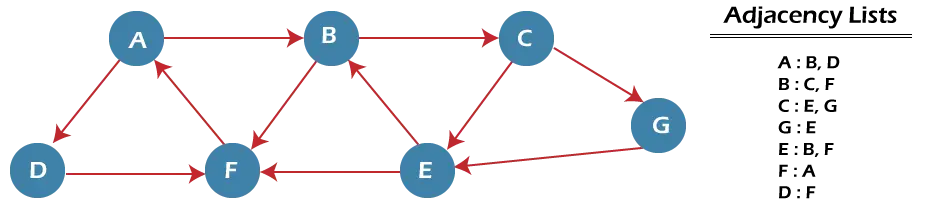
上のグラフでは、ノード A から開始してノード E で終了する BFS を使用して、最小パス「P」を見つけることができます。このアルゴリズムでは、QUEUE1 と QUEUE2 という 2 つのキューを使用します。 QUEUE1 は処理されるすべてのノードを保持し、QUEUE2 は処理され、QUEUE1 から削除されたすべてのノードを保持します。
ここで、ノード A からグラフを調べてみましょう。
ステップ1 - まず、queue1 に A を追加し、queue2 に NULL を追加します。
QUEUE1 = {A} QUEUE2 = {NULL} ステップ2 - ここで、キュー 1 からノード A を削除し、キュー 2 に追加します。ノード A のすべての隣接ノードを queue1 に挿入します。
QUEUE1 = {B, D} QUEUE2 = {A} ステップ3 - 次に、キュー 1 からノード B を削除し、キュー 2 に追加します。ノード B のすべての近隣ノードを queue1 に挿入します。
QUEUE1 = {D, C, F} QUEUE2 = {A, B} ステップ4 - ここで、キュー 1 からノード D を削除し、キュー 2 に追加します。ノード D のすべての隣接ノードを queue1 に挿入します。ノード D の唯一の隣接ノードは F です。これは既に挿入されているため、再度挿入されることはありません。
QUEUE1 = {C, F} QUEUE2 = {A, B, D} ステップ5 - ノード C を queue1 から削除し、queue2 に追加します。ノード C のすべての隣接ノードを queue1 に挿入します。
QUEUE1 = {F, E, G} QUEUE2 = {A, B, D, C} ステップ5 - ノード F を queue1 から削除し、queue2 に追加します。ノード F のすべての近隣ノードを queue1 に挿入します。ノード F の近隣ノードはすべてすでに存在しているため、それらを再度挿入することはありません。
QUEUE1 = {E, G} QUEUE2 = {A, B, D, C, F} ステップ6 - ノード E をキュー 1 から削除します。隣接するものはすべてすでに追加されているため、再度挿入しません。ここで、すべてのノードが訪問され、ターゲット ノード E が queue2 に到達します。
QUEUE1 = {G} QUEUE2 = {A, B, D, C, F, E} BFS アルゴリズムの複雑さ
BFS の時間計算量は、グラフを表すために使用されるデータ構造によって異なります。 BFS アルゴリズムの時間計算量は次のとおりです。 O(V+E) 、最悪の場合、BFS アルゴリズムはすべてのノードとエッジを探索するためです。グラフでは、頂点の数は O(V) ですが、辺の数は O(E) です。
BFS の空間複雑さは次のように表すことができます。 O(V) ここで、V は頂点の数です。
BFSアルゴリズムの実装
次に、Java での BFS アルゴリズムの実装を見てみましょう。
このコードでは、隣接リストを使用してグラフを表しています。 Java で幅優先検索アルゴリズムを実装すると、ノードがキューの先頭 (または先頭) からデキューされた後、各ノードに接続されているノードのリストを移動するだけで済むため、隣接リストの処理が非常に簡単になります。
Javaの素数プログラム
この例では、コードを示すために使用しているグラフは次のようになります。

import java.io.*; import java.util.*; public class BFSTraversal { private int vertex; /* total number number of vertices in the graph */ private LinkedList adj[]; /* adjacency list */ private Queue que; /* maintaining a queue */ BFSTraversal(int v) { vertex = v; adj = new LinkedList[vertex]; for (int i=0; i<v; i++) { adj[i]="new" linkedlist(); } que="new" void insertedge(int v,int w) adj[v].add(w); * adding an edge to the adjacency list (edges are bidirectional in this example) bfs(int n) boolean nodes[]="new" boolean[vertex]; initialize array for holding data int a="0;" nodes[n]="true;" que.add(n); root node is added top of queue while (que.size() !="0)" n="que.poll();" remove element system.out.print(n+' '); print (int i="0;" < adj[n].size(); iterate through linked and push all neighbors into if (!nodes[a]) only insert nodes they have not been explored already nodes[a]="true;" que.add(a); public static main(string args[]) bfstraversal graph="new" bfstraversal(10); graph.insertedge(0, 1); 2); 3); graph.insertedge(1, graph.insertedge(2, 4); graph.insertedge(3, 5); 6); graph.insertedge(4, 7); graph.insertedge(5, graph.insertedge(6, graph.insertedge(7, 8); system.out.println('breadth first traversal is:'); graph.bfs(2); pre> <p> <strong>Output</strong> </p> <img src="//techcodeview.com/img/ds-tutorial/64/bfs-algorithm-3.webp" alt="Breadth First Search Algorithm"> <h3>Conclusion</h3> <p>In this article, we have discussed the Breadth-first search technique along with its example, complexity, and implementation in java programming language. Here, we have also seen the real-life applications of BFS that show it the important data structure algorithm.</p> <p>So, that's all about the article. Hope, it will be helpful and informative to you.</p> <hr></v;>