この記事では、データ構造における DFS アルゴリズムについて説明します。これは、ツリー データ構造またはグラフのすべての頂点を検索する再帰的アルゴリズムです。深さ優先検索 (DFS) アルゴリズムは、グラフ G の最初のノードから開始し、目標ノードまたは子のないノードが見つかるまでさらに深く進みます。
再帰的な性質のため、スタック データ構造を使用して DFS アルゴリズムを実装できます。 DFS を実装するプロセスは、BFS アルゴリズムと似ています。
DFS トラバーサルを実装するための段階的なプロセスは次のとおりです。
- まず、グラフ内の頂点の総数を含むスタックを作成します。
- ここで、トラバースの開始点として任意の頂点を選択し、その頂点をスタックにプッシュします。
- その後、訪問されていない頂点 (スタックの一番上の頂点に隣接する) をスタックの一番上にプッシュします。
- 次に、スタックの最上部の頂点から訪問する頂点がなくなるまで、ステップ 3 と 4 を繰り返します。
- 頂点が残っていない場合は、戻ってスタックから頂点をポップします。
- スタックが空になるまで手順 2、3、4 を繰り返します。
DFSアルゴリズムの応用
DFS アルゴリズムを使用するアプリケーションは次のとおりです。
C++のxor
- DFS アルゴリズムを使用して、トポロジカル ソートを実装できます。
- 2 つの頂点間のパスを見つけるために使用できます。
- グラフ内のサイクルを検出するためにも使用できます。
- DFS アルゴリズムは 1 つの解決策のパズルにも使用されます。
- DFS は、グラフが 2 部構成であるかどうかを判断するために使用されます。
アルゴリズム
ステップ1: G の各ノードの SET STATUS = 1 (準備完了状態)
ステップ2: 開始ノード A をスタックにプッシュし、STATUS = 2 (待機状態) に設定します。
ステップ 3: STACKが空になるまでステップ4と5を繰り返します。
ステップ 4: 最上位ノード N をポップします。それを処理し、STATUS = 3 (処理済み状態) に設定します。
世界で最高の車
ステップ5: 準備完了状態 (STATUS = 1) にある N のすべての隣接ノードをスタックにプッシュし、STATUS = 2 (待機状態) に設定します。
[ループの終わり]
ステップ6: 出口
疑似コード
DFS(G,v) ( v is the vertex where the search starts ) Stack S := {}; ( start with an empty stack ) for each vertex u, set visited[u] := false; push S, v; while (S is not empty) do u := pop S; if (not visited[u]) then visited[u] := true; for each unvisited neighbour w of uu push S, w; end if end while END DFS() DFSアルゴリズムの例
ここで、例を使用して DFS アルゴリズムの仕組みを理解しましょう。以下に示す例には、7 つの頂点を持つ有向グラフがあります。
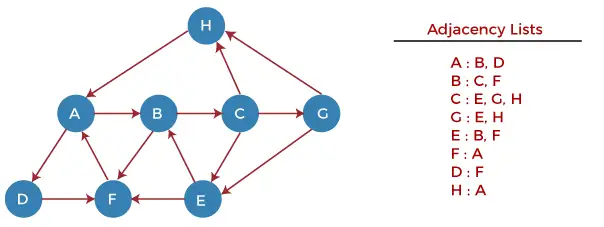
ここで、ノード H からグラフを調べてみましょう。
ステップ1 - まず、H をスタックにプッシュします。
音楽をダウンロードする方法
STACK: H
ステップ2 - スタックから最上位の要素 (H) を POP して出力します。ここで、準備完了状態にある H のすべての隣接ノードをスタックに PUSH します。
Print: H]STACK: A
ステップ3 - スタックから最上位の要素、つまり A を POP して出力します。ここで、準備完了状態にある A のすべての隣接ノードをスタックに PUSH します。
Print: A STACK: B, D
ステップ4 - スタックから最上位の要素、つまり D を POP して出力します。ここで、準備完了状態にある D のすべての隣接ノードをスタックに PUSH します。
Print: D STACK: B, F
ステップ5 - スタックから最上位の要素、つまり F を POP して出力します。ここで、準備完了状態にある F のすべての隣接ノードをスタックに PUSH します。
Print: F STACK: B
ステップ6 - スタックから最上位の要素 (B) を POP して出力します。ここで、準備完了状態にある B のすべての隣接ノードをスタックに PUSH します。
アリヤ・マナサ
Print: B STACK: C
ステップ7 - スタックから最上位の要素 (つまり C) を POP して出力します。ここで、準備完了状態にある C のすべての隣接ノードをスタックに PUSH します。
Print: C STACK: E, G
ステップ8 - スタックの最上位要素、つまり G を POP し、準備完了状態にある G のすべての隣接要素をスタックに PUSH します。
Print: G STACK: E
ステップ9 - スタックの最上位要素、つまり E を POP し、準備完了状態にある E のすべての隣接要素をスタックに PUSH します。
Print: E STACK:
これで、すべてのグラフ ノードが走査され、スタックは空になりました。
深さ優先探索アルゴリズムの複雑さ
DFS アルゴリズムの時間計算量は次のとおりです。 O(V+E) ここで、V はグラフ内の頂点の数、E はエッジの数です。
DFS アルゴリズムの空間計算量は O(V) です。
DFSアルゴリズムの実装
次に、Java での DFS アルゴリズムの実装を見てみましょう。
この例では、コードを示すために使用しているグラフは次のようになります。

/*A sample java program to implement the DFS algorithm*/ import java.util.*; class DFSTraversal { private LinkedList adj[]; /*adjacency list representation*/ private boolean visited[]; /* Creation of the graph */ DFSTraversal(int V) /*'V' is the number of vertices in the graph*/ { adj = new LinkedList[V]; visited = new boolean[V]; for (int i = 0; i <v; i++) adj[i]="new" linkedlist(); } * adding an edge to the graph void insertedge(int src, int dest) { adj[src].add(dest); dfs(int vertex) visited[vertex]="true;" *mark current node as visited* system.out.print(vertex + ' '); iterator it="adj[vertex].listIterator();" while (it.hasnext()) n="it.next();" if (!visited[n]) dfs(n); public static main(string args[]) dfstraversal dfstraversal(8); graph.insertedge(0, 1); 2); 3); graph.insertedge(1, graph.insertedge(2, 4); graph.insertedge(3, 5); 6); graph.insertedge(4, 7); graph.insertedge(5, system.out.println('depth first traversal for is:'); graph.dfs(0); < pre> <p> <strong>Output</strong> </p> <img src="//techcodeview.com/img/ds-tutorial/28/dfs-algorithm-3.webp" alt="DFS algorithm"> <h3>Conclusion</h3> <p>In this article, we have discussed the depth-first search technique, its example, complexity, and implementation in the java programming language. Along with that, we have also seen the applications of the depth-first search algorithm.</p> <p>So, that's all about the article. Hope it will be helpful and informative to you.</p> <hr></v;>