人工知能の急速に進化する時代において、ディープラーニングは基礎テクノロジーとしての地位を確立し、機械が複雑なデータを理解し、学習し、対話する方法に革命をもたらします。本質的に、ディープ ラーニング AI は人間の脳の複雑なニューラル ネットワークを模倣しており、コンピューターが自律的にパターンを発見し、膨大な量の非構造化データから意思決定できるようにします。この変革的な分野は、コンピューター ビジョンや自然言語処理から医療診断や自動運転に至るまで、さまざまな領域にわたって画期的な進歩を推進してきました。
ディープラーニングの概要
この深層学習の入門的な探求に踏み込むと、その基本原理、応用、そして機械が人間のような認知能力を達成できるようにする基礎となるメカニズムが明らかになります。この記事は、ディープ ラーニングがどのように業界を再構築し、AI で可能なことの限界を押し広げ、インテリジェント システムが自律的に認識、理解、革新できる未来への道を切り開いているかを理解するための入り口として機能します。
ディープラーニングとは何ですか?
ディープラーニングの定義は、 機械学習 それは人工ニューラルネットワークアーキテクチャに基づいています。人工ニューラルネットワークや アン は、入力データを処理して学習するために連携して動作するニューロンと呼ばれる、相互接続されたノードの層を使用します。
ヒープソートアルゴリズム
完全に接続されたディープ ニューラル ネットワークには、入力層と 1 つ以上の隠れ層が次々に接続されています。各ニューロンは、前の層のニューロンまたは入力層から入力を受け取ります。 1 つのニューロンの出力は、ネットワークの次の層の他のニューロンへの入力となり、このプロセスは、最後の層がネットワークの出力を生成するまで続きます。ニューラル ネットワークの層は、一連の非線形変換を通じて入力データを変換し、ネットワークが入力データの複雑な表現を学習できるようにします。
ディープラーニングの範囲
現在、ディープ ラーニング AI は、コンピューター ビジョン、自然言語処理、強化学習などのさまざまなアプリケーションでの成功により、機械学習の中で最も人気があり注目されている分野の 1 つとなっています。
ディープラーニング AI は、教師あり、教師なし、および強化機械学習に使用できます。これらを処理するためにさまざまな方法が使用されます。
デスクトップ.iniとは何ですか
- 教師あり機械学習: 教師あり機械学習 それは 機械学習 ニューラル ネットワークがラベル付けされたデータセットに基づいて予測を行ったり、データを分類したりする方法を学習する技術。ここでは、両方の入力フィーチャとターゲット変数を入力します。ニューラル ネットワークは、予測ターゲットと実際のターゲットの差から生じるコストまたは誤差に基づいて予測を行うことを学習します。このプロセスはバックプロパゲーションとして知られています。畳み込みニューラル ネットワークやリカレント ニューラル ネットワークなどの深層学習アルゴリズムは、画像の分類と認識、感情分析、言語翻訳などの多くの教師ありタスクに使用されます。
- 教師なし機械学習: 教師なし機械学習 それは 機械学習 ニューラル ネットワークがパターンを発見したり、ラベルのないデータセットに基づいてデータセットをクラスタリングしたりする方法を学習します。ここにはターゲット変数はありません。一方、マシンはデータセット内の隠れたパターンや関係を自己決定する必要があります。オートエンコーダーや生成モデルなどの深層学習アルゴリズムは、クラスタリング、次元削減、異常検出などの教師なしタスクに使用されます。
- 強化機械学習 : 強化機械学習 それは 機械学習 エージェントが環境内で報酬シグナルを最大化する意思決定を行う方法を学習する手法。エージェントは、アクションを実行し、その結果得られる報酬を観察することによって、環境と対話します。ディープ ラーニングを使用すると、時間の経過とともに累積報酬を最大化するポリシー、つまり一連のアクションを学習できます。 Deep Q ネットワークや Deep Deterministic Policy Gradient (DDPG) などの深層強化学習アルゴリズムは、ロボット工学やゲームプレイなどのタスクを強化するために使用されます。
人工ニューラルネットワーク
人工ニューラルネットワーク 人間のニューロンの構造と動作の原理に基づいて構築されています。ニューラル ネットワークまたはニューラル ネットワークとも呼ばれます。人工ニューラル ネットワークの最初の層である入力層は、外部ソースから入力を受け取り、それを 2 番目の層である隠れ層に渡します。隠れ層の各ニューロンは、前の層のニューロンから情報を取得し、加重合計を計算して、それを次の層のニューロンに転送します。これらの接続は重み付けされます。これは、各入力に個別の重みを与えることによって、前の層からの入力の影響が多かれ少なかれ最適化されることを意味します。これらの重みはトレーニング プロセス中に調整され、モデルのパフォーマンスが向上します。
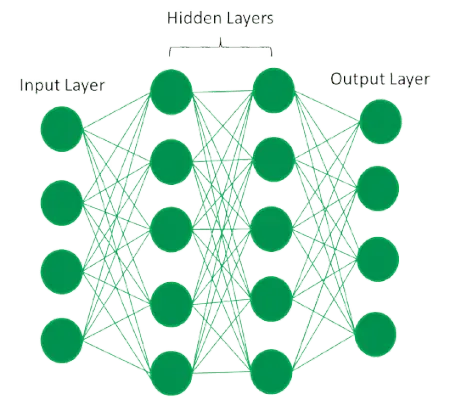
完全に接続された人工ニューラル ネットワーク
ユニットとしても知られる人工ニューロンは、人工ニューラル ネットワークに含まれています。人工ニューラル ネットワーク全体は、一連の層に配置されたこれらの人工ニューロンで構成されています。ニューラル ネットワークの複雑さは、レイヤーに数十のユニットがあるか数百万のユニットがあるかに関係なく、データセット内の基礎となるパターンの複雑さに依存します。一般に、人工ニューラル ネットワークには、入力層、出力層、および隠れ層があります。入力層は、ニューラル ネットワークが分析または学習する必要があるデータを外部から受け取ります。
完全に接続された人工ニューラル ネットワークには、入力層と 1 つ以上の隠れ層が次々に接続されています。各ニューロンは、前の層のニューロンまたは入力層から入力を受け取ります。 1 つのニューロンの出力は、ネットワークの次の層の他のニューロンへの入力となり、このプロセスは、最後の層がネットワークの出力を生成するまで続きます。次に、1 つ以上の隠れ層を通過した後、このデータは出力層にとって価値のあるデータに変換されます。最後に、出力層は、受信データに対する人工ニューラル ネットワークの応答の形式で出力を提供します。
ユニットは、ニューラル ネットワークの大部分において、ある層から別の層まで相互にリンクされています。これらの各リンクには、あるユニットが別のユニットにどの程度影響を与えるかを制御する重みがあります。ニューラル ネットワークは、あるユニットから別のユニットに移動するにつれてデータについてさらに学習し、最終的に出力層から出力を生成します。
機械学習と深層学習の違い:
機械学習 とディープラーニング AI はどちらも人工知能のサブセットですが、それらの間には多くの類似点と相違点があります。
Java コレクション
| 機械学習 | ディープラーニング |
|---|---|
| 統計アルゴリズムを適用して、データセット内の隠れたパターンと関係を学習します。 | 人工ニューラル ネットワーク アーキテクチャを使用して、データセット内の隠れたパターンと関係を学習します。 |
| より少ない量のデータセットで作業できる | 機械学習と比較して大量のデータセットが必要 |
| ラベルの低いタスクに適しています。 | 画像処理、自然言語処理などの複雑なタスクに適しています。 |
| モデルのトレーニングにかかる時間が短縮されます。 | モデルのトレーニングにはさらに時間がかかります。 |
| モデルは、画像内のオブジェクトを検出するために画像から手動で抽出された関連する特徴によって作成されます。 | 関連する特徴が画像から自動的に抽出されます。これはエンドツーエンドの学習プロセスです。 |
| 複雑さが軽減され、結果の解釈が容易になります。 | さらに複雑な場合、結果のブラックボックス解釈は簡単ではないように機能します。 |
| CPU で動作するか、ディープ ラーニングと比較して必要な計算能力が少なくなります。 | GPU を搭載した高性能コンピューターが必要です。 |
ニューラルネットワークの種類
深層学習モデルはデータから特徴を自動的に学習できるため、画像認識、音声認識、自然言語処理などのタスクに適しています。深層学習で最も広く使用されているアーキテクチャは、フィードフォワード ニューラル ネットワーク、畳み込みニューラル ネットワーク (CNN)、およびリカレント ニューラル ネットワーク (RNN) です。
- フィードフォワード ニューラル ネットワーク (FNN) 最も単純なタイプの ANN であり、ネットワークを介して情報が直線的に流れます。 FNN は、画像分類、音声認識、自然言語処理などのタスクに広く使用されています。
- 畳み込みニューラル ネットワーク (CNN) 特に画像とビデオの認識タスクに使用されます。 CNN は画像から特徴を自動的に学習できるため、画像分類、オブジェクト検出、画像セグメンテーションなどのタスクに適しています。
- リカレント ニューラル ネットワーク (RNN) は、時系列や自然言語などの連続データを処理できるニューラル ネットワークの一種です。 RNN は、以前の入力に関する情報をキャプチャする内部状態を維持できるため、音声認識、自然言語処理、言語翻訳などのタスクに適しています。
深層学習アプリケーション:
深層学習 AI の主な用途は、コンピューター ビジョン、自然言語処理 (NLP)、強化学習に分類できます。
Javaでのマージソート
1. コンピュータビジョン
最初の深層学習アプリケーションはコンピューター ビジョンです。で コンピュータビジョン , ディープラーニング AI モデルにより、機械が視覚データを識別して理解できるようになります。コンピューター ビジョンにおける深層学習の主な用途には次のようなものがあります。
- 物体の検出と認識: 深層学習モデルを使用すると、画像やビデオ内のオブジェクトを識別して位置を特定できるため、機械が自動運転車、監視、ロボット工学などのタスクを実行できるようになります。
- 画像分類: 深層学習モデルを使用すると、画像を動物、植物、建物などのカテゴリに分類できます。これは、医療画像処理、品質管理、画像検索などのアプリケーションで使用されます。
- 画像のセグメンテーション: 深層学習モデルを使用して画像をさまざまな領域にセグメンテーションし、画像内の特定の特徴を識別できるようにします。
2. 自然言語処理 (NLP) :
深層学習アプリケーションの 2 番目のアプリケーションは NLP です。 NLP 、 深層学習モデルにより、機械が人間の言語を理解して生成できるようになります。深層学習の主な用途のいくつか NLP 含む:
- 自動テキスト生成 – 深層学習モデルはテキストのコーパスを学習し、これらのトレーニング済みモデルを使用して要約やエッセイなどの新しいテキストを自動的に生成できます。
- 言語翻訳: 深層学習モデルはテキストをある言語から別の言語に翻訳できるため、異なる言語的背景を持つ人々とのコミュニケーションが可能になります。
- 感情分析: 深層学習モデルはテキストの感情を分析し、そのテキストが肯定的か否定的か中立的かを判断することができます。これは、顧客サービス、ソーシャル メディア監視、政治分析などのアプリケーションで使用されます。
- 音声認識: 深層学習モデルは、話された言葉を認識して書き起こすことができるため、音声からテキストへの変換、音声検索、音声制御デバイスなどのタスクを実行できるようになります。
3. 強化学習:
で 強化学習 , ディープラーニングは、報酬を最大化する環境で行動を起こすためのトレーニングエージェントとして機能します。強化学習における深層学習の主な用途には次のようなものがあります。
- ゲームプレイ: 深層強化学習モデルは、囲碁、チェス、Atari などのゲームで人間の専門家に勝つことができました。
- ロボット工学: 深層強化学習モデルを使用すると、オブジェクトの把握、ナビゲーション、操作などの複雑なタスクを実行するようにロボットをトレーニングできます。
- 制御システム: 深層強化学習モデルは、電力網、交通管理、サプライ チェーンの最適化などの複雑なシステムを制御するために使用できます。
ディープラーニングの課題
ディープラーニングはさまざまな分野で大きな進歩を遂げていますが、まだ解決すべき課題がいくつかあります。深層学習における主な課題のいくつかを次に示します。
- データの可用性 : 学習には大量のデータが必要です。ディープラーニングを使用する場合、トレーニング用にできるだけ多くのデータを収集することが大きな関心事です。
- 計算リソース : 深層学習モデルのトレーニングには、GPU や TPU などの特殊なハードウェアが必要なため、計算コストが高くなります。
- 時間がかかる: 逐次データを処理する場合、計算リソースによっては、数日または数か月かかる場合もあります。
- 私 解釈可能性: ディープラーニング モデルは複雑で、ブラック ボックスのように機能します。結果を解釈するのは非常に困難です。
- 過学習: モデルが何度もトレーニングされると、トレーニング データに対して特化しすぎて、新しいデータに対する過剰適合やパフォーマンスの低下につながります。
ディープラーニングの利点:
- 高い正確性: 深層学習アルゴリズムは、画像認識や自然言語処理などのさまざまなタスクで最先端のパフォーマンスを実現できます。
- 自動化された特徴量エンジニアリング: 深層学習アルゴリズムは、手動の特徴エンジニアリングを必要とせずに、データから関連する特徴を自動的に検出して学習できます。
- スケーラビリティ: 深層学習モデルは、大規模で複雑なデータセットを処理できるように拡張でき、大量のデータから学習できます。
- 柔軟性: 深層学習モデルは幅広いタスクに適用でき、画像、テキスト、音声などのさまざまな種類のデータを処理できます。
- 継続的改善: ディープ ラーニング モデルは、より多くのデータが利用可能になるにつれて、パフォーマンスを継続的に向上させることができます。
ディープラーニングのデメリット:
- 高度な計算要件: ディープラーニング AI モデルのトレーニングと最適化には、大量のデータと計算リソースが必要です。
- 大量のラベル付きデータが必要 : 深層学習モデルでは、トレーニングのために大量のラベル付きデータが必要になることが多く、取得には費用と時間がかかる場合があります。
- 解釈可能性: ディープ ラーニング モデルは解釈が難しい場合があり、モデルがどのように意思決定を行うかを理解することが困難になります。
過学習: 深層学習モデルはトレーニング データに過剰適合する場合があり、その結果、新しいデータやまだ見たことのないデータに対するパフォーマンスが低下することがあります。 - ブラックボックスの性質 :ディープラーニングモデルはブラックボックスとして扱われることが多く、モデルがどのように機能するのか、そしてどのようにして予測に到達したのかを理解することが困難になります。
結論
結論として、ディープラーニングの分野は人工知能における変革的な飛躍を表しています。深層学習 AI アルゴリズムは、人間の脳のニューラル ネットワークを模倣することで、ヘルスケアから金融、自動運転車から自然言語処理に至るまで、さまざまな業界に革命をもたらしました。計算能力とデータセット サイズの限界を押し広げ続けるにつれて、ディープ ラーニングの潜在的なアプリケーションは無限に広がります。しかし、解釈可能性や倫理的配慮などの課題は依然として大きい。しかし、進行中の研究とイノベーションにより、ディープラーニングは私たちの未来を再構築し、機械がこれまで想像できなかった規模と速度で複雑な問題を学習、適応、解決できる新時代の到来を約束します。