あ 畳み込みニューラル ネットワーク (CNN) は、コンピューター ビジョンで一般的に使用される深層学習ニューラル ネットワーク アーキテクチャの一種です。コンピューター ビジョンは、コンピューターが画像や視覚データを理解して解釈できるようにする人工知能の分野です。
機械学習に関して言えば、 人工ニューラルネットワーク 本当に上手にパフォーマンスします。ニューラル ネットワークは、画像、音声、テキストなどのさまざまなデータセットで使用されます。さまざまな種類のニューラル ネットワークがさまざまな目的に使用されます。たとえば、使用する単語の順序を予測するためです。 リカレント ニューラル ネットワーク より正確には LSTM 、同様に画像分類には畳み込みニューラル ネットワークを使用します。このブログでは、CNN の基本的な構成要素を構築します。
通常のニューラル ネットワークには 3 種類の層があります。
比較可能なリスト
- 入力レイヤー: これはモデルに入力を与える層です。この層のニューロンの数は、データ内の特徴の総数 (画像の場合はピクセル数) に等しくなります。
- 非表示レイヤー: 次に、入力層からの入力が隠れ層に供給されます。モデルとデータ サイズに応じて、多くの隠れ層が存在する可能性があります。各隠れ層には異なる数のニューロンを含めることができ、通常は特徴の数よりも多くなります。各層からの出力は、前の層の出力とその層の学習可能な重みを行列乗算し、次に学習可能なバイアスを追加し、その後ネットワークを非線形にする活性化関数によって計算されます。
- 出力層: 隠れ層からの出力は、シグモイドやソフトマックスなどのロジスティック関数に供給され、各クラスの出力が各クラスの確率スコアに変換されます。
データがモデルに入力され、各層からの出力が上記のステップから取得されます。 フィードフォワード 次に、誤差関数を使用して誤差を計算します。一般的な誤差関数には、クロスエントロピー誤差、二乗損失誤差などがあります。誤差関数は、ネットワークのパフォーマンスを測定します。その後、導関数を計算してモデルに逆伝播します。このステップは次のように呼ばれます 畳み込みニューラル ネットワーク (CNN) は、 人工ニューラル ネットワーク (ANN) これは主に、グリッド状の行列データセットから特徴を抽出するために使用されます。たとえば、データ パターンが広範な役割を果たす画像やビデオなどのビジュアル データセットです。
CNN アーキテクチャ
畳み込みニューラル ネットワークは、入力層、畳み込み層、プーリング層、全結合層などの複数の層で構成されます。

シンプルな CNN アーキテクチャ
畳み込み層は入力画像にフィルターを適用して特徴を抽出し、プーリング層は画像をダウンサンプリングして計算量を削減し、完全接続層が最終予測を行います。ネットワークは、バックプロパゲーションと勾配降下を通じて最適なフィルターを学習します。
畳み込み層の仕組み
畳み込みニューラル ネットワークまたはコブネットは、パラメーターを共有するニューラル ネットワークです。イメージがあると想像してください。これは、長さ、幅 (画像の寸法)、および高さを持つ直方体として表すことができます (つまり、画像には通常、赤、緑、青のチャネルがある)。
ここで、この画像の小さなパッチを取得し、その上でフィルターまたはカーネルと呼ばれる小さなニューラル ネットワークを実行し、たとえば K 出力を垂直方向に表現することを想像してください。次に、そのニューラル ネットワークを画像全体にスライドさせます。その結果、幅、高さ、深さが異なる別の画像が得られます。 R、G、B チャネルだけでなく、チャネル数は増えましたが、幅と高さは減少しました。この操作はと呼ばれます コンボリューション 。パッチのサイズが画像のサイズと同じであれば、通常のニューラル ネットワークになります。このパッチが小さいため、重みが少なくなります。
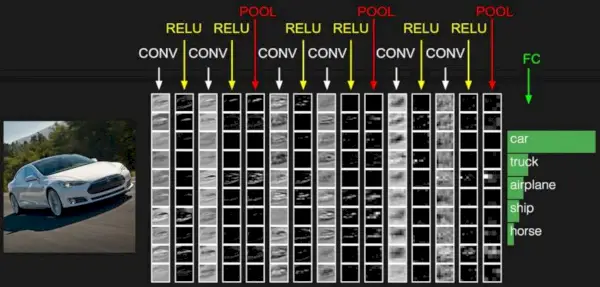
画像出典: ディープラーニング Udacity
ここで、畳み込みプロセス全体に関係するちょっとした数学について話しましょう。
- 畳み込み層は、幅と高さが小さく、入力ボリュームと同じ深さ (入力層が画像入力の場合は 3) を持つ学習可能なフィルター (またはカーネル) のセットで構成されます。
- たとえば、34x34x3 のサイズの画像に対して畳み込みを実行する必要があるとします。フィルターの可能なサイズは axax3 です。ここで、「a」は 3、5、または 7 のようなものですが、画像の寸法と比較すると小さいものになります。
- フォワードパス中、各フィルターを入力ボリューム全体で段階的にスライドさせ、各ステップが呼び出されます。 ストライド (高次元イメージの場合は 2、3、さらには 4 の値を持つことができます)、入力ボリュームからカーネルの重みとパッチの間の内積を計算します。
- フィルターをスライドさせると、各フィルターの 2 次元出力が得られ、それらを積み重ねることで、フィルターの数に等しい深さの出力ボリュームが得られます。ネットワークはすべてのフィルターを学習します。
ConvNet の構築に使用されるレイヤー
完全な畳み込みニューラル ネットワーク アーキテクチャは、コブネットとしても知られています。コブネットは一連のレイヤーであり、各レイヤーは微分可能な関数を通じて 1 つのボリュームを別のボリュームに変換します。
レイヤーの種類: データセット
寸法 32 x 32 x 3 のイメージに対してコブネットを実行する例を見てみましょう。
人工知能とインテリジェントエージェント
- 入力レイヤー: これはモデルに入力を与える層です。 CNN では、通常、入力は画像または一連の画像になります。このレイヤーは、幅 32、高さ 32、深さ 3 の画像の生の入力を保持します。
- 畳み込み層: これは、入力データセットからフィーチャを抽出するために使用されるレイヤーです。カーネルとして知られる学習可能なフィルターのセットを入力画像に適用します。フィルター/カーネルは、通常 2×2、3×3、または 5×5 の形状の小さな行列です。入力画像データ上をスライドし、カーネルの重みと対応する入力画像パッチの間のドット積を計算します。この層の出力は特徴マップと呼ばれます。このレイヤーに合計 12 個のフィルターを使用すると、32 x 32 x 12 の次元の出力ボリュームが得られます。
- アクティベーションレイヤー: 前の層の出力に活性化関数を追加することにより、活性化層はネットワークに非線形性を追加します。要素ごとの活性化関数を畳み込み層の出力に適用します。一般的なアクティベーション関数には次のようなものがあります。 再開する : 最大(0, x), 怪しい 、 リーキー RELU など。ボリュームは変更されないため、出力ボリュームの寸法は 32 x 32 x 12 になります。
- プーリング層: この層はコブネットに定期的に挿入され、その主な機能はボリュームのサイズを縮小して計算を高速化し、メモリを削減し、オーバーフィッティングを防止することです。プーリング層の一般的なタイプは次の 2 つです。 最大プーリング そして 平均プーリング 。 2 x 2 フィルターとストライド 2 を持つ最大プールを使用すると、結果として得られるボリュームの寸法は 16x16x12 になります。
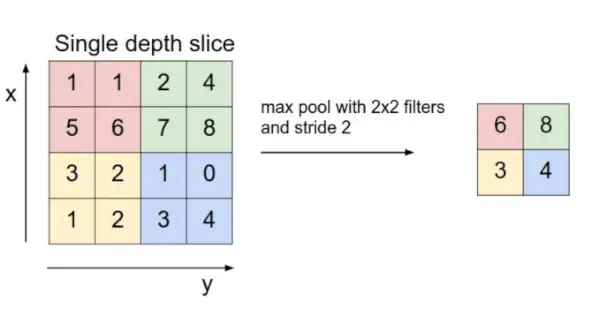
画像ソース: cs231n.stanford.edu
- 平坦化: 結果として得られる特徴マップは、畳み込み層とプーリング層の後に 1 次元ベクトルに平坦化されるため、分類または回帰のために完全にリンクされた層に渡すことができます。
- 完全に接続された層: 前の層から入力を取得し、最終的な分類または回帰タスクを計算します。
画像ソース: cs231n.stanford.edu
- 出力層: 完全に接続された層からの出力は、シグモイドやソフトマックスなどの分類タスク用のロジスティック関数に供給され、各クラスの出力が各クラスの確率スコアに変換されます。
例:
画像を考えて、畳み込み層、活性化層、プーリング層の演算を適用して内部の特徴を抽出してみましょう。
集合の代数
入力画像:
入力画像
ステップ:
- 必要なライブラリをインポートする
- パラメータを設定する
- カーネルを定義する
- 画像をロードしてプロットします。
- 画像を再フォーマットする
- 畳み込み層演算を適用し、出力イメージをプロットします。
- アクティベーション層の操作を適用し、出力イメージをプロットします。
- プーリング層の操作を適用し、出力イメージをプロットします。
Python3
# import the necessary libraries> import> numpy as np> import> tensorflow as tf> import> matplotlib.pyplot as plt> from> itertools>import> product> > # set the param> plt.rc(>'figure'>, autolayout>=>True>)> plt.rc(>'image'>, cmap>=>'magma'>)> > # define the kernel> kernel>=> tf.constant([[>->1>,>->1>,>->1>],> >[>->1>,>8>,>->1>],> >[>->1>,>->1>,>->1>],> >])> > # load the image> image>=> tf.io.read_file(>'Ganesh.webp'plain'>)>> tf.io.decode_jpeg(image, channels>=>1>)> image>=> tf.image.resize(image, size>=>[>300>,>300>])> > # plot the image> img>=> tf.squeeze(image).numpy()> plt.figure(figsize>=>(>5>,>5>))> plt.imshow(img, cmap>=>'gray'>)> plt.axis(>'off'>)> plt.title(>'Original Gray Scale image'>)> plt.show();> > > # Reformat> image>=> tf.image.convert_image_dtype(image, dtype>=>tf.float32)> image>=> tf.expand_dims(image, axis>=>0>)> kernel>=> tf.reshape(kernel, [>*>kernel.shape,>1>,>1>])> kernel>=> tf.cast(kernel, dtype>=>tf.float32)> > # convolution layer> conv_fn>=> tf.nn.conv2d> > image_filter>=> conv_fn(> >input>=>image,> >filters>=>kernel,> >strides>=>1>,># or (1, 1)> >padding>=>'SAME'>,> )> > plt.figure(figsize>=>(>15>,>5>))> > # Plot the convolved image> plt.subplot(>1>,>3>,>1>)> > plt.imshow(> >tf.squeeze(image_filter)> )> plt.axis(>'off'>)> plt.title(>'Convolution'>)> > # activation layer> relu_fn>=> tf.nn.relu> # Image detection> image_detect>=> relu_fn(image_filter)> > plt.subplot(>1>,>3>,>2>)> plt.imshow(> ># Reformat for plotting> >tf.squeeze(image_detect)> )> > plt.axis(>'off'>)> plt.title(>'Activation'>)> > # Pooling layer> pool>=> tf.nn.pool> image_condense>=> pool(>input>=>image_detect,> >window_shape>=>(>2>,>2>),> >pooling_type>=>'MAX'>,> >strides>=>(>2>,>2>),> >padding>=>'SAME'>,> >)> > plt.subplot(>1>,>3>,>3>)> plt.imshow(tf.squeeze(image_condense))> plt.axis(>'off'>)> plt.title(>'Pooling'>)> plt.show()> |
>
np.ユニーク
>
出力 :

元のグレースケール画像
出力
畳み込みニューラル ネットワーク (CNN) の利点:
- 画像、ビデオ、オーディオ信号のパターンと特徴の検出に優れています。
- 平行移動、回転、スケーリングの不変性に対して堅牢です。
- エンドツーエンドのトレーニング。手動による特徴抽出は必要ありません。
- 大量のデータを処理でき、高い精度を実現します。
畳み込みニューラル ネットワーク (CNN) の欠点:
- トレーニングには計算コストがかかり、大量のメモリが必要になります。
- 十分なデータがないか、適切な正則化が使用されていない場合、過学習が発生する傾向があります。
- 大量のラベル付きデータが必要です。
- 解釈可能性は限られており、ネットワークが何を学習したかを理解するのは困難です。
よくある質問 (FAQ)
1: 畳み込みニューラル ネットワーク (CNN) とは何ですか?
畳み込みニューラル ネットワーク (CNN) は、画像やビデオの分析に適した深層学習ニューラル ネットワークの一種です。 CNN は、一連の畳み込み層とプーリング層を使用して画像やビデオから特徴を抽出し、これらの特徴を使用してオブジェクトやシーンを分類または検出します。
2: CNN はどのように機能するのでしょうか?
CNN は、一連の畳み込み層とプーリング層を入力画像またはビデオに適用することによって機能します。畳み込み層は、画像またはビデオ上で小さなフィルターまたはカーネルをスライドさせ、フィルターと入力の間のドット積を計算することにより、入力から特徴を抽出します。次に、プーリング層は畳み込み層の出力をダウンサンプリングして、データの次元を削減し、計算効率を高めます。
Java ブール値から文字列へ
3: CNN で使用される一般的な活性化関数にはどのようなものがありますか?
CNN で使用される一般的なアクティベーション関数には次のようなものがあります。
- Rectified Linear Unit (ReLU): ReLU は、計算効率が高く、トレーニングが容易な非飽和活性化関数です。
- Leaky Rectified Linear Unit (Leaky ReLU): Leaky ReLU は、少量の負の勾配がネットワークを流れることを可能にする ReLU の変種です。これは、トレーニング中にネットワークが停止するのを防ぐのに役立ちます。
- Parametric Rectified Linear Unit (PReLU): PReLU は、負の勾配の傾きを学習できるようにする Leaky ReLU を一般化したものです。
4: CNN で複数の畳み込み層を使用する目的は何ですか?
CNN で複数の畳み込み層を使用すると、ネットワークは入力画像またはビデオからますます複雑な特徴を学習できるようになります。最初の畳み込み層は、エッジやコーナーなどの単純な特徴を学習します。より深い畳み込み層は、形状やオブジェクトなどのより複雑な特徴を学習します。
5: CNN で使用される一般的な正則化手法にはどのようなものがありますか?
正則化技術は、CNN がトレーニング データを過剰適合するのを防ぐために使用されます。 CNN で使用される一般的な正則化手法には次のようなものがあります。
- ドロップアウト: ドロップアウトは、トレーニング中にネットワークからニューロンをランダムにドロップアウトします。これにより、ネットワークは単一のニューロンに依存しない、より堅牢な機能を学習するようになります。
- L1 正則化: L1 正則化は正則化します ネットワーク内の重みの絶対値。これは重みの数を減らし、ネットワークをより効率的にするのに役立ちます。
- L2 正則化: L2 正則化は正則化します ネットワーク内の重みの二乗。これは、重みの数を減らし、ネットワークをより効率的にするのにも役立ちます。
6: 畳み込み層とプーリング層の違いは何ですか?
畳み込み層は入力画像またはビデオから特徴を抽出し、プーリング層は畳み込み層の出力をダウンサンプリングします。畳み込み層は一連のフィルターを使用して特徴を抽出しますが、プーリング層は最大プーリングや平均プーリングなどのさまざまな手法を使用してデータをダウンサンプリングします。