Python リストは配列の代わりになりますが、大規模な数値データのセットを計算する際に必要なパフォーマンスを提供できません。
この問題に対処するために、 NumPy ライブラリ パイソンの。 NumPy は、と呼ばれる配列オブジェクトを提供します。 ndarray 。これらは標準の Python シーケンスに似ていますが、特定の重要な要素が異なります。
NumPy配列とは何ですか?
NumPy 配列は、Python の科学計算の中核となる多次元データ構造です。
配列内のすべての値は同種です (同じデータ型です)。
自動ベクトル化とブロードキャストを提供します。
これらは効率的なメモリ管理、 ufuncs(universal function) を提供し、さまざまなデータ型をサポートし、インデックス付けとスライスに柔軟に対応します。
配列内の次元
NumPy 配列は複数の次元を持つことができるため、ユーザーはデータを多層構造に保存できます。
配列の次元:
| 名前 | 例 |
| 0D(ゼロ次元) | スカラー – 単一の要素 |
| 1D(一次元) | 写真素材 - 整数のリスト。 |
| 2D(二次元) | マトリックス - データのスプレッドシート |
| 3D(立体) | Tensor - カラー画像の保存 |
配列オブジェクトの作成
NumPy 配列のオブジェクトを使用すると、Python で配列を操作できるようになります。配列オブジェクトが呼び出されます ndarray 。
NumPy ライブラリの array() 関数は ndarray を作成します。
Python3
10億のうちゼロは何個
import> numpy as np> arr>=> np.array([>1>,>2>,>3>,>4>,>5>,>6>])> |
>
>
出力
スキップリスト
[1,2,3,4,5,6]>
List と Tuple を使用して NumPy 配列を作成することもできます。
リストから NumPy 配列を作成する
np エイリアスを使用して、 リスト array() メソッドを使用します。
li = [1,2,3,4] numpyArr = np.array(li)>
または
numpyArr = np.array([1,2,3,4])>
リストは array() メソッドに渡され、同じ要素を含む配列が返されます。
例 1: 次の例は、リストから配列を初期化する方法を示しています。
Python3
bash if 条件
import> numpy as np> > li>=> [>1>,>2>,>3>,>4>]> numpyArr>=> np.array(li)> print>(numpyArr)> |
>
>
出力:
[1 2 3 4]>
結果の配列はリストと同じように見えますが、NumPy オブジェクトです。
例 2: numpyArr が NumPy オブジェクトかどうかを確認する例を見てみましょう。この例では、array() 関数を使用してリストを NumPy 配列に変換し、それが NumPy オブジェクトかどうかを確認します。
Python3
import> numpy as np> > li>=> [>1>,>2>,>3>,>4>]> numpyArr>=> np.array(li)> > print>(>'li ='>, li,>'and type(li) ='>,>type>(li))> print>(>'numpyArr ='>, numpyArr,>'and type(numpyArr) ='>,>type>(numpyArr))> |
>
>
出力:
li = [1, 2, 3, 4] and type(li) = numpyArr = [1 2 3 4] and type(numpyArr) =>
ご覧のとおり、li はリスト オブジェクトですが、numpyArr は NumPy の配列オブジェクトです。
タプルから NumPy 配列を作成する
から ndarray を作成できます タプル 同様の構文を使用します。
tup = (1,2,3,4) numpyArr = np.array(tup)>
または
numpyArr = np.array((1,2,3,4))>
次の例は、タプルから配列を作成する方法を示しています。ここでは、array() 関数を使用してタプルを NumPy 配列に変換しています。
Python3
ジャワペア
import> numpy as np> > tup>=> (>1>,>2>,>3>,>4>)> numpyArr>=> np.array(tup)> > print>(>'tup ='>, tup,>'and type(tup) ='>,>type>(tup))> print>(>'numpyArr ='>, numpyArr,>'and type(numpyArr) ='>,>type>(numpyArr))> |
>
>
出力:
tup = (1, 2, 3, 4) and type(tup) = numpyArr = [1 2 3 4] and type(numpyArr) =>
numpyArr の値は 2 つの変換のどちらでも同じままであることに注意してください。
NumPy 配列と組み込み Python シーケンスの比較
- リストとは異なり、配列のサイズは固定されており、配列のサイズを変更すると新しい配列が作成され、元の配列は削除されます。
- 配列内のすべての要素は同じ型です。
- 配列は、標準の Python シーケンスよりも高速で効率的で、必要な構文が少なくなります。
注記: さまざまな科学的および数学的な Python ベースのパッケージは Numpy を使用します。入力を組み込みの Python シーケンスとして受け取る可能性がありますが、処理を高速化するためにデータを NumPy 配列に変換する可能性があります。これは、NumPy を理解する必要があることを説明しています。
Numpy 配列はなぜそれほど高速なのでしょうか?
Numpy 配列は主に次のように記述されます。 C言語 。 C で記述されているため、配列は連続したメモリ位置に格納されるため、アクセス可能で操作が容易になります。これは、Python プログラムを簡単に作成しながら、C コードのパフォーマンス レベルを取得できることを意味します。
- 均質なデータ: 配列は同じデータ型の要素を格納するため、リストよりもコンパクトでメモリ効率が高くなります。
- 固定データ型: 配列のデータ型は固定されており、各要素の型情報を格納する必要がなくなるため、メモリのオーバーヘッドが削減されます。
- 連続メモリ: 配列は要素を隣接するメモリ位置に格納するため、断片化が軽減され、効率的なアクセスが可能になります。
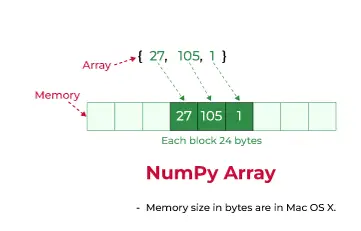
Numpy 配列のメモリ割り当て
システムに NumPy がインストールされていない場合は、次の手順に従ってインストールできます。 NumPy をインストールしたら、次のようにプログラムにインポートできます。
import numpy as np>
注記: ここで、np は NumPy の一般的に使用されるエイリアスです。
Numpy 配列でのデータ割り当て
NumPy では、データは、データ バッファー、形状、ストライドで構成される明確に定義されたレイアウトに従って、メモリ内に連続的に割り当てられます。これは、効率的なデータ アクセス、ベクトル化された操作、および次のような低レベル ライブラリとの互換性にとって不可欠です。 BLAS そして ラパック 。
Javaでメソッドを呼び出す方法
- データバッファ: NumPy のデータ バッファーは、次元に関係なく、配列の実際の要素を格納する単一のフラットなメモリ ブロックです。これにより、要素ごとの効率的な操作とデータ アクセスが可能になります。
- 形: 配列の形状は、各軸に沿った次元を表す整数のタプルです。各整数は、特定の次元に沿った配列のサイズに対応します。これは、各軸に沿った要素の数を定義し、配列の正しいインデックス付けと再形成に不可欠です。
- ストライド: ストライドは、ある要素から次の要素に移動するときに各次元でステップ実行するバイト数を定義する整数のタプルです。これらはメモリ内の要素間の間隔を決定し、各次元で 1 つの要素から別の要素に移動するのに必要なバイト数を測定します。

結論
Python の NumPy 配列は非常に便利なデータ構造であり、データに対してさまざまな科学的操作を実行できるようになります。これは非常にメモリ効率の高いデータ構造であり、他の Python シーケンスに比べてさまざまな利点があります。
このチュートリアルでは、NumPy 配列について詳しく説明しました。定義、次元数、高速な理由、配列内でのデータ割り当ての仕組みについて説明しました。このチュートリアルを完了すると、NumPy 配列に関する完全な深い知識が得られ、Python プロジェクトに実装できるようになります。