スキップリストとは何ですか?
スキップ リストは確率的なデータ構造です。スキップ リストは、要素またはデータの並べ替えられたリストをリンク リストとともに保存するために使用されます。要素やデータのプロセスを効率的に表示できます。 1 つのステップでリスト全体のいくつかの要素をスキップするため、スキップ リストと呼ばれます。
スキップ リストはリンク リストの拡張版です。これにより、ユーザーは要素の検索、削除、挿入を非常に迅速に行うことができます。これは、後続の要素のリンク階層を維持する一連の要素を含む基本リストで構成されます。
スキップリスト構造
最下層と最上層の2層で構築されています。
スキップ リストの最下位層は一般的な並べ替えられたリンク リストで、スキップ リストの最上位層は要素がスキップされる「急行」のようなものです。
スキップリストの複雑さの表
| はい・いいえ | 複雑 | 平均的なケース | 最悪の場合 |
|---|---|---|---|
| 1. | アクセスの複雑さ | O(ログン) | の上) |
| 2. | 検索の複雑さ | O(ログン) | の上) |
| 3. | 複雑さの削除 | O(ログン) | の上) |
| 4. | 複雑さを挿入する | O(ログン) | の上) |
| 5. | 空間の複雑さ | - | O(nlogn) |
スキップリストの仕組み
スキップ リストの仕組みを理解するために例を見てみましょう。この例には 14 個のノードがあり、図に示すように、これらのノードは 2 つのレイヤーに分割されています。
図からわかるように、下位層はすべてのノードを接続する共通回線、最上位層は主要ノードのみを接続する急行回線です。
この例では 47 を見つけたいとします。エクスプレス ラインの最初のノードから検索を開始し、47 または 47 以上のノードが見つかるまでエクスプレス ラインの実行を続けます。
この例では、急行回線には 47 が存在しないことがわかります。そのため、47 未満のノード、つまり 40 を検索します。次に、40 を使用して通常の回線に移動し、47 を検索します。図に示すように。
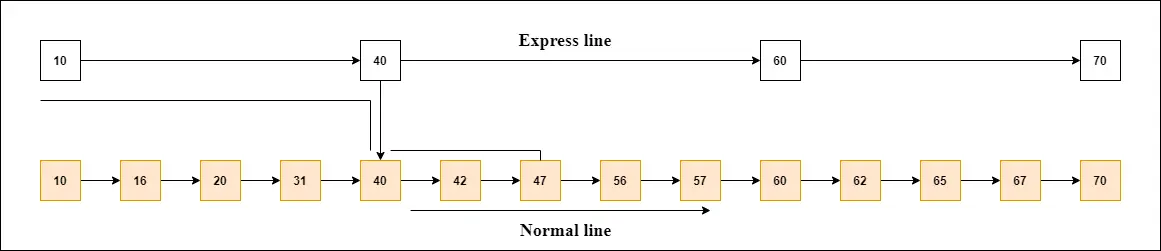
注: 「急行線」でこのようなノードを見つけたら、ポインタを使用してこのノードから「通常レーン」に移動し、通常線でノードを検索します。
スキップリストの基本操作
スキップリストの操作には以下の種類があります。
挿入操作のアルゴリズム
Insertion (L, Key) local update [0...Max_Level + 1] a = L → header for i = L → level down to 0 do. while a → forward[i] → key forward[i] update[i] = a a = a → forward[0] lvl = random_Level() if lvl > L → level then for i = L → level + 1 to lvl do update[i] = L → header L → level = lvl a = makeNode(lvl, Key, value) for i = 0 to level do a → forward[i] = update[i] → forward[i] update[i] → forward[i] = a
削除操作のアルゴリズム
Deletion (L, Key) local update [0... Max_Level + 1] a = L → header for i = L → level down to 0 do. while a → forward[i] → key forward[i] update[i] = a a = a → forward[0] if a → key = Key then for i = 0 to L → level do if update[i] → forward[i] ? a then break update[i] → forward[i] = a → forward[i] free(a) while L → level > 0 and L → header → forward[L → level] = NIL do L → level = L → level - 1
検索動作のアルゴリズム
Searching (L, SKey) a = L → header loop invariant: a → key level down to 0 do. while a → forward[i] → key forward[i] a = a → forward[0] if a → key = SKey then return a → value else return failure
例 1: スキップ リストを作成します。空のスキップ リストに次のキーを挿入します。
- レベル1で6。
- レベル1で29。
- レベル4で22。
- レベル3で9。
- レベル1で17。
- レベル2で4。
年:
ステップ1: レベル 1 で 6 を挿入

ステップ2: レベル 1 で 29 を挿入

ステップ 3: レベル 4 で 22 を挿入

ステップ 4: レベル 3 で 9 を挿入

ステップ5: レベル 1 で 17 を挿入

ステップ6: レベル 2 で 4 を挿入

例 2: キー 17 を検索するこの例を考えてみましょう。

年:

スキップリストの利点
- スキップ リストに新しいノードを挿入する場合、スキップ リストにはローテーションがないため、非常に高速にノードが挿入されます。
- スキップ リストは、ハッシュ テーブルや二分探索木に比べて実装が簡単です。
- ノードはソートされた形式で保存されるため、リスト内のノードを見つけるのは非常に簡単です。
- スキップ リスト アルゴリズムは、インデックス付け可能なスキップ リスト、ツリー、優先キューなど、より具体的な構造で非常に簡単に変更できます。
- スキップ リストは堅牢で信頼できるリストです。
スキップリストのデメリット
- バランスの取れたツリーよりも多くのメモリが必要です。
- 逆引き検索はできません。
- スキップ リストはリンク リストよりもはるかに遅くノードを検索します。
スキップリストの応用例
- これは分散アプリケーションで使用され、分散アプリケーション内のポインタとシステムを表します。
- これは、ロック競合が少ない動的で柔軟な同時キューを実装するために使用されます。
- QMap テンプレート クラスでも使用されます。
- スキップ リストのインデックス付けは、中央値問題を実行する際に使用されます。
- スキップ リストは、Lucene 検索におけるデルタ エンコーディングのポストに使用されます。