の GROUP BY ステートメント SQL は、いくつかの関数を使用して同一のデータをグループに配置するために使用されます。つまり、特定の列の異なる行に同じ値がある場合、これらの行をグループに配置します。
特徴
- GROUP BY 句は SELECT ステートメントとともに使用されます。
- クエリでは、GROUP BY 句は どこ 句。
- クエリでは、GROUP BY 句がクエリの前に配置されます。 注文 BY 句を使用する場合。
- クエリでは、Group BY 句が Have 句の前に配置されます。
- 条件をhaving句に置きます。
構文 :
SELECT 列 1、関数名(列 2)
FROM テーブル名
WHERE 条件
GROUP BY 列 1、列 2
ORDER BY 列 1、列 2;
説明:
- 関数名 : SUM() 、 AVG() など、使用される関数の名前。
- テーブル名 : テーブルの名前。
- 状態 :使用感のある状態です。
2 つのテーブルがあると仮定します。従業員と学生のサンプル テーブルは次のとおりです。2 つのテーブルを追加した後、GROUP BY について学ぶためにいくつかの特定の操作を実行します。
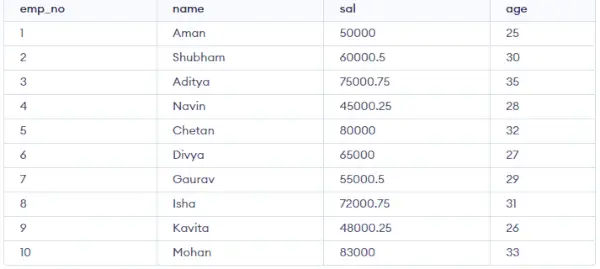
従業員テーブル:
CREATE TABLE emp ( emp_no INT PRIMARY KEY, name VARCHAR(50), sal DECIMAL(10,2), age INT );>
ランダムなデータをテーブルに挿入し、GROUP BY でいくつかの操作を実行します。
クエリ:
INSERT INTO emp (emp_no, name, sal, age) VALUES (1, 'Aarav', 50000.00, 25), (2, 'Aditi', 60000.50, 30), (3, 'Amit', 75000.75, 35), (4, 'Anjali', 45000.25, 28), (5, 'Chetan', 80000.00, 32), (6, 'Divya', 65000.00, 27), (7, 'Gaurav', 55000.50, 29), (8, 'Isha', 72000.75, 31), (9, 'Kavita', 48000.25, 26), (10, 'Mohan', 83000.00, 33);>
出力:
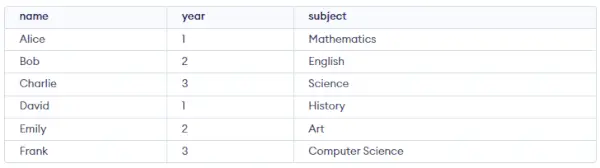
学生テーブル:
クエリ:
CREATE TABLE student ( name VARCHAR(50), year INT, subject VARCHAR(50) ); INSERT INTO student (name, year, subject) VALUES ('Alice', 1, 'Mathematics'), ('Bob', 2, 'English'), ('Charlie', 3, 'Science'), ('David', 1, 'History'), ('Emily', 2, 'Art'), ('Frank', 3, 'Computer Science');> 出力:
データ構造 Java
単一列でグループ化
単一列でグループ化とは、その特定の列のみの同じ値を持つすべての行を 1 つのグループに配置することを意味します。以下に示すようなクエリを考えてみましょう。
クエリ:
SELECT NAME, SUM(SALARY) FROM emp GROUP BY NAME;>
上記のクエリは次の出力を生成します。
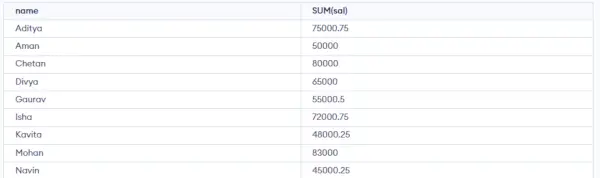
上記の出力でわかるように、重複する NAME を持つ行は同じ NAME の下にグループ化され、対応する SALARY は重複する行の SALARY の合計になります。ここでは SQL の SUM() 関数を使用して合計を計算します。
複数の列でグループ化
複数の列によるグループ化は、たとえば、 GROUP BY 列 1、列 2 。これは、すべての行を同じ列の値で配置することを意味します。 列 1 そして 列 2 1つのグループで。以下のクエリを考えてみましょう。
クエリ:
SELECT SUBJECT, YEAR, Count(*) FROM Student GROUP BY SUBJECT, YEAR;>
出力:
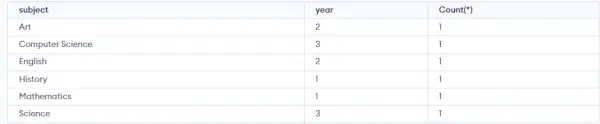
出力 : 上記の出力でわかるように、同じ主題と学年の両方を持つ学生は同じグループに配置されます。また、SUBJECT だけが同じで YEAR が同じでないものは、異なるグループに属します。そこで、ここでは 2 つの列または複数の列に従ってテーブルをグループ化しました。
GROUP BY 句の HAVING 句
WHERE 句が列に条件を設定するために使用されることはわかっていますが、グループに条件を設定したい場合はどうすればよいでしょうか?ここで HAVING 句が使用されます。 HAVING 句を使用して条件を設定し、どのグループが最終結果セットの一部になるかを決定できます。また、WHERE 句では SUM()、COUNT() などの集計関数を使用できません。したがって、条件でこれらの関数のいずれかを使用したい場合は、HAVING 句を使用する必要があります。
構文 :
SELECT 列 1、関数名(列 2)
FROM テーブル名
WHERE 条件
GROUP BY 列 1、列 2
条件を持っている
ORDER BY 列 1、列 2;
説明:
- 関数名 : SUM() 、 AVG() など、使用される関数の名前。
- テーブル名 : テーブルの名前。
- 状態 :使用感のある状態です。
例 :
SELECT NAME, SUM(sal) FROM Emp GROUP BY name HAVING SUM(sal)>3000;>>
出力 :
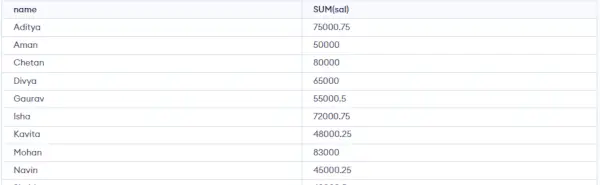
上記の出力でわかるように、SALARY の合計が 3000 を超える唯一のグループであるため、3 つのグループのうち 1 つのグループだけが結果セットに表示されます。そこで、ここでは HAVING 句を使用して、この条件を条件は列ではなくグループに配置する必要があります。