IDENTITY キーワードは SQL Server のプロパティです。 テーブル列が ID プロパティで定義されている場合、その値は自動生成された増分値になります 。この値はサーバーによって自動的に作成されます。したがって、ユーザーとして ID 列に値を手動で入力することはできません。したがって、列を ID としてマークすると、SQL Server は自動インクリメント方式でその列に値を設定します。
構文
SQL Server での IDENTITY プロパティの使用を示す構文は次のとおりです。
IDENTITY[(seed, increment)]
上記の構文パラメーターについては、以下で説明します。
簡単な例を通してこの概念を理解してみましょう。
' があるとします。 学生 ' テーブル、そして私たちが望むのは 学生証 自動的に生成されます。私たちには、 の最初の学生証 10 であり、新しい ID ごとに 1 ずつ増やしたいと考えています。このシナリオでは、次の値を定義する必要があります。
シード: 10
インクリメント: 1
CREATE TABLE Student ( StudentID INT IDENTITY(10, 1) PRIMARY KEY NOT NULL, )
注: SQL Server のテーブルごとに許可される識別列は 1 つだけです。
SQL Server IDENTITY の例
テーブル内で ID プロパティを使用する方法を理解しましょう。列の ID プロパティは、新しいテーブルの作成時または作成後に設定できます。ここでは両方のケースを例を挙げて見ていきます。
新しいテーブルの IDENTITY プロパティ
次のステートメントは、指定されたデータベースに ID プロパティを持つ新しいテーブルを作成します。
CREATE TABLE person ( PersonID INT IDENTITY(10,1) PRIMARY KEY NOT NULL, Fullname VARCHAR(100) NOT NULL, Occupation VARCHAR(50), Gender VARCHAR(10) NOT NULL );
次に、このテーブルに新しい行を挿入します。 出力 自動生成された人物 ID を確認するには、次の句を使用します。
INSERT INTO person(Fullname, Occupation, Gender) OUTPUT inserted.PersonID VALUES('Sara Jackson', 'HR', 'Female');
このクエリを実行すると、次の出力が表示されます。
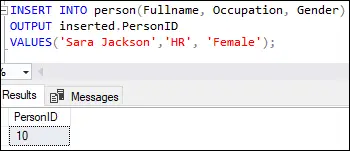
この出力は、最初の行に値 10 が挿入されたことを示しています。 個人ID テーブル定義の ID 列で指定された列。
に別の行を挿入しましょう 人物テーブル 以下のように:
INSERT INTO person(Fullname, Occupation, Gender) OUTPUT inserted.* VALUES('Mark Boucher', 'Cricketer', 'Male'), ('Josh Phillip', 'Writer', 'Male');
このクエリは次の出力を返します。

この出力は、PersonID 列に 2 行目に値 11 が挿入され、3 行目に値 12 が挿入されたことを示しています。
既存のテーブルの IDENTITY プロパティ
この概念を説明するには、まず上記のテーブルを削除し、ID プロパティなしでテーブルを作成します。以下のステートメントを実行してテーブルを削除します。
DROP TABLE person;
次に、以下のクエリを使用してテーブルを作成します。
CREATE TABLE person ( Fullname VARCHAR(100) NOT NULL, Occupation VARCHAR(50), Gender VARCHAR(10) NOT NULL );
既存のテーブルに ID プロパティを持つ新しい列を追加する場合は、ALTER コマンドを使用する必要があります。以下のクエリは、personID を person テーブルに ID 列として追加します。
ALTER TABLE person ADD PersonID INT IDENTITY(10,1) PRIMARY KEY NOT NULL;
ID 列に値を明示的に追加する
ID 列の値を明示的に指定して上記のテーブルに新しい行を追加すると、SQL Server はエラーをスローします。以下のクエリを参照してください。
INSERT INTO person(Fullname, Occupation, Gender, PersonID) VALUES('Mary Smith', 'Business Analyst', 'Female', 13);
このクエリを実行すると、次のエラーが発生します。

ID 列の値を明示的に挿入するには、まず IDENTITY_INSERT 値を ON に設定する必要があります。次に、挿入操作を実行してテーブルに新しい行を追加し、IDENTITY_INSERT 値を OFF に設定します。以下のコード スクリプトを参照してください。
SET IDENTITY_INSERT person ON /*INSERT VALUE*/ INSERT INTO person(Fullname, Occupation, Gender, PersonID) VALUES('Mary Smith', 'Business Analyst', 'Female', 14); SET IDENTITY_INSERT person OFF SELECT * FROM person;
IDENTITY_INSERT オン ユーザーは ID 列にデータを入力できますが、 IDENTITY_INSERT オフ この列に値を追加できなくなります。
コード スクリプトを実行すると、以下の出力が表示され、値 14 の PersonID が正常に挿入されたことがわかります。

IDENTITY関数
SQL Server は、テーブル内の IDENTITY 列を操作するためのいくつかの ID 関数を提供します。これらの ID 関数を以下に示します。
- @@IDENTITY 関数
- SCOPE_IDENTITY() 関数
- IDENT_CURRENT 関数
- IDENTITY関数
いくつかの例を挙げて IDENTITY 関数を見てみましょう。
@@IDENTITY 関数
@@IDENTITY はシステム定義関数です。 最後の ID 値を表示します (最大使用 ID 値) 同じセッション内の IDENTITY 列のテーブルに作成されます。この関数列は、テーブルに新しいエントリを挿入した後にステートメントによって生成された ID 値を返します。を返します ヌル IDENTITY 値を作成しないクエリを実行するときの値。これは常に現在のセッションのスコープ内で機能します。リモートからは使用できません。
例
person テーブルの現在の最大 ID 値が 13 であるとします。次に、同じセッションに ID 値を 1 ずつ増やすレコードを 1 つ追加します。次に、@@IDENTITY 関数を使用して、同じセッションで作成された最後の ID 値を取得します。
完全なコードスクリプトは次のとおりです。
SELECT MAX(PersonID) AS maxidentity FROM person; INSERT INTO person(Fullname, Occupation, Gender) VALUES('Brian Lara', 'Cricket', 'Male'); SELECT @@IDENTITY;
スクリプトを実行すると、次の出力が返され、使用される ID の最大値が 14 であることがわかります。

SCOPE_IDENTITY() 関数
SCOPE_IDENTITY() は、次のことを行うシステム定義関数です。 最新の ID 値を表示します 現在のスコープ内のテーブル内。このスコープには、モジュール、トリガー、関数、またはストアド プロシージャを指定できます。これは @@IDENTITY() 関数に似ていますが、この関数のスコープが限定されている点が異なります。 SCOPE_IDENTITY 関数は、同じスコープ内で値を生成する挿入操作の前に実行すると NULL を返します。
例
以下のコードは、同じセッションで @@IDENTITY 関数と SCOPE_IDENTITY() 関数の両方を使用します。この例では、最初に最後の ID 値を表示し、次にテーブルに 1 行を挿入します。次に、両方の ID 関数を実行します。
SELECT MAX(PersonID) AS maxid FROM person; INSERT INTO person(Fullname, Occupation, Gender) VALUES('Jennifer Winset', 'Actoress', 'Female'); SELECT SCOPE_IDENTITY(); SELECT @@IDENTITY;
コードを実行すると、現在のセッションおよび同様のスコープに同じ値が表示されます。以下の出力イメージを参照してください。

ここで、例を使用して両方の関数がどのように異なるかを見てみましょう。まず、という名前の 2 つのテーブルを作成します。 従業員データ そして 部門 以下のステートメントを使用します。
CREATE TABLE employee_data ( emp_id INT IDENTITY(1, 1) PRIMARY KEY NOT NULL, fullname VARCHAR(20) NULL ) GO CREATE TABLE department ( department_id INT IDENTITY(100, 5) PRIMARY KEY, department_name VARCHAR(20) NULL );
次に、employee_data テーブルに INSERT トリガーを作成します。このトリガーは、employee_data テーブルに行を挿入するたびに、Department テーブルに行を挿入するために呼び出されます。
以下のクエリは、デフォルト値を挿入するためのトリガーを作成します。 'それ' 部門テーブルでは、employee_data テーブルの各挿入クエリで次のようになります。
データの独立性を説明する
CREATE TRIGGER Insert_Department ON employee_data FOR INSERT AS BEGIN INSERT INTO department VALUES ('IT') END;
トリガーを作成した後、employee_data テーブルに 1 つのレコードを挿入し、@@IDENTITY 関数と SCOPE_IDENTITY() 関数の両方の出力を確認します。
INSERT INTO employee_data VALUES ('John Mathew');
クエリを実行すると、employee_data テーブルに 1 行が追加され、同じセッション内に ID 値が生成されます。挿入クエリがemployee_dataテーブルで実行されると、トリガーが自動的に呼び出され、部門テーブルに行が1行追加されます。 ID シード値は、employee_data の場合は 1、部門テーブルの場合は 100 です。
最後に、以下のステートメントを実行します。これらのステートメントは、同じスコープ内の ID 値のみを返すため、SELECT @@IDENTITY 関数の出力 100 と SCOPE_IDENTITY 関数の出力 1 を表示します。
SELECT MAX(emp_id) FROM employee_data SELECT MAX(department_id) FROM department SELECT @@IDENTITY SELECT SCOPE_IDENTITY()
結果は次のとおりです。

IDENT_CURRENT() 関数
IDENT_CURRENT はシステム定義関数です。 最新の IDENTITY 値を表示します 任意の接続の下で特定のテーブルに対して生成されます。この関数は、ID 値を作成する SQL クエリのスコープを考慮しません。この関数には、ID 値を取得するテーブル名が必要です。
例
まず 2 つの接続ウィンドウを開いてみればわかります。最初のウィンドウに 1 つのレコードを挿入し、person テーブルに ID 値 15 を生成します。次に、同じ出力が表示される別の接続ウィンドウでこの ID 値を確認できます。完全なコードは次のとおりです。
1st Connection Window INSERT INTO person(Fullname, Occupation, Gender) VALUES('John Doe', 'Engineer', 'Male'); GO SELECT MAX(PersonID) AS maxid FROM person; 2nd Connection Window SELECT MAX(PersonID) AS maxid FROM person; GO SELECT IDENT_CURRENT('person') AS identity_value;
上記のコードを 2 つの異なるウィンドウで実行すると、同じ ID 値が表示されます。

IDENTITY() 関数
IDENTITY() 関数はシステム定義関数です。 新しいテーブルに ID 列を挿入するために使用されます。 。この関数は、CREATE TABLE ステートメントおよび ALTER TABLE ステートメントで使用する IDENTITY プロパティとは異なります。この関数は、あるテーブルから別のテーブルにデータを転送するときに使用される SELECT INTO ステートメントでのみ使用できます。
次の構文は、SQL Server でのこの関数の使用法を示しています。
IDENTITY (data_type , seed , increment) AS column_name
ソーステーブルに IDENTITY 列がある場合、SELECT INTO コマンドで形成されたテーブルはデフォルトでその列を継承します。 例えば , 以前に ID 列を持つテーブル person を作成しました。 IDENTITY() 関数を含む SELECT INTO ステートメントを使用して、person テーブルを継承する新しいテーブルを作成するとします。この場合、ソーステーブルにはすでに ID 列があるため、エラーが発生します。以下のクエリを参照してください。
SELECT IDENTITY(INT, 100, 2) AS NEW_ID, PersonID, Fullname, Occupation, Gender INTO person_info FROM person;
上記のステートメントを実行すると、次のエラー メッセージが返されます。

以下のステートメントを使用して、ID プロパティを持たない新しいテーブルを作成してみましょう。
CREATE TABLE student_data ( roll_no INT PRIMARY KEY NOT NULL, fullname VARCHAR(20) NULL )
次に、次のように IDENTITY 関数を含む SELECT INTO ステートメントを使用して、このテーブルをコピーします。
SELECT IDENTITY(INT, 100, 1) AS student_id, roll_no, fullname INTO temp_data FROM student_data;
ステートメントが実行されたら、次のコマンドを使用して検証できます。 sp_ヘルプ テーブルのプロパティを表示するコマンド。

IDENTITY 列が表示されます。 誘惑しやすい 指定された条件に従ってプロパティを設定します。
この関数を SELECT ステートメントで使用すると、SQL Server は次のエラー メッセージを表示します。
メッセージ 177、レベル 15、状態 1、行 2 IDENTITY 関数は、SELECT ステートメントに INTO 句がある場合にのみ使用できます。
IDENTITY 値の再利用
SQL Server テーブルの ID 値を再利用することはできません。 ID 列テーブルから行を削除すると、ID 列にギャップが作成されます。また、ID 列に新しい行を挿入すると、SQL Server によってギャップが作成され、ステートメントが失敗するかロールバックされます。このギャップは、ID 値が失われ、IDENTITY 列に再度生成できないことを示します。
実際に理解するために、以下の例を考えてみましょう。次のデータを含む person テーブルがすでにあります。

次に、さらに 2 つのテーブルを作成します。 '位置' 、 そして ' 人物の立場 ' 次のステートメントを使用します。
CREATE TABLE POSITION ( PositionID INT IDENTITY (1, 1) PRIMARY KEY, Position_name VARCHAR (255) NOT NULL ); CREATE TABLE person_position ( PersonID INT, PositionID INT, PRIMARY KEY (PersonID, PositionID), FOREIGN KEY (PersonID) REFERENCES person (PersonID), FOREIGN KEY (PositionID) REFERENCES POSITION (PositionID) );
次に、新しいレコードを person テーブルに挿入し、person_position テーブルに新しい行を追加して位置を割り当てます。これは、次のようにトランザクション ステートメントを使用して実行します。
BEGIN TRANSACTION BEGIN TRY -- insert a new row into the person table INSERT INTO person (Fullname, Occupation, Gender) VALUES('Joan Smith', 'Manager', 'Male'); -- assign a position to a new person INSERT INTO person_position (PersonID, PositionID) VALUES(@@IDENTITY, 10); END TRY BEGIN CATCH IF @@TRANCOUNT > 0 ROLLBACK TRANSACTION; END CATCH IF @@TRANCOUNT > 0 COMMIT TRANSACTION;
上記のトランザクション コード スクリプトは、最初の挿入ステートメントを正常に実行します。しかし、位置テーブルに ID 10 の位置がなかったため、2 番目のステートメントは失敗しました。したがって、トランザクション全体がロールバックされました。
PersonID 列の最大 ID 値は 16 であるため、最初の挿入ステートメントで ID 値 17 が消費され、トランザクションはロールバックされました。したがって、Person テーブルに次の行を挿入すると、次の ID 値は 18 になります。以下のステートメントを実行します。
INSERT INTO person(Fullname, Occupation, Gender) VALUES('Peter Drucker',' Writer', 'Female');
person テーブルを再度確認すると、新しく追加されたレコードに ID 値 18 が含まれていることがわかります。

1 つのテーブル内の 2 つの IDENTITY 列
技術的には、1 つのテーブルに 2 つの ID 列を作成することはできません。これを行うと、SQL Server はエラーをスローします。次のクエリを参照してください。
CREATE TABLE TwoIdentityTable ( ID1 INT IDENTITY (10, 1) NOT NULL, ID2 INT IDENTITY (100, 1) NOT NULL )
このコードを実行すると、次のエラーが表示されます。

ただし、計算列を使用すると、1 つのテーブルに 2 つの ID 列を作成できます。次のクエリは、元の ID 列を使用して 1 ずつ減らす計算列を含むテーブルを作成します。
CREATE TABLE TwoIdentityTable ( ID1 INT IDENTITY (10, 1) NOT NULL, SecondID AS 10000-ID1, Descriptions VARCHAR(60) )
次に、以下のコマンドを使用して、このテーブルにデータを追加します。
INSERT INTO TwoIdentityTable (Descriptions) VALUES ('Javatpoint provides best educational tutorials'), ('www.javatpoint.com')
最後に、SELECT ステートメントを使用してテーブル データを確認します。次の出力が返されます。

この図では、SecondID 列が 2 番目の ID 列として機能し、開始値 9990 から 10 ずつ減少する様子がわかります。
SQL Server の IDENTITY 列の誤解
DBA ユーザーは、SQL Server の ID 列に関して多くの誤解を持っています。以下は、ID 列に関してよく見られる誤解のリストです。
IDENTITY 列は一意です: SQL Server の公式ドキュメントによると、identity プロパティは列値が一意であることを保証できません。列の一意性を強制するには、PRIMARY KEY、UNIQUE 制約、または UNIQUE インデックスを使用する必要があります。
IDENTITY 列は連続した番号を生成します。 公式ドキュメントには、ID 列に割り当てられた値はデータベース障害またはサーバーの再起動時に失われる可能性があると明確に記載されています。挿入中に ID 値にギャップが生じる可能性があります。ギャップは、テーブルから値を削除したとき、または挿入ステートメントがロールバックされたときにも作成される可能性があります。ギャップを生成する値はそれ以上使用できません。
IDENTITY 列は既存の値を自動生成できません。 DBCC CHECKIDENT コマンドを使用して ID プロパティが再シードされるまで、ID 列で既存の値を自動生成することはできません。これにより、ID プロパティのシード値 (行の開始値) を調整できます。このコマンドの実行後、SQL Server は、新しく作成された値がテーブル内にすでに存在するかどうかをチェックしません。
行を識別するには、IDENTITY 列を PRIMARY KEY として使用するだけで十分です。 他に一意の制約がないテーブル内の主キーに ID 列が含まれている場合、その列に重複した値が格納され、列の一意性が妨げられる可能性があります。ご存知のとおり、主キーには重複した値を格納できませんが、ID 列には重複した値を格納できます。同じ列で主キーと ID プロパティを使用しないことをお勧めします。
挿入後に間違ったツールを使用して ID 値を取得すると、次のようになります。 また、実行したばかりのステートメントから直接挿入された ID 値を取得するための @@IDENTITY、SCOPE_IDENTITY()、IDENT_CURRENT、および IDENTITY() 関数の違いを認識していないというよくある誤解もあります。
SEQUENCE と IDENTITY の違い
自動番号の生成には SEQUENCE と IDENTITY の両方を使用します。ただし、いくつかの違いがあり、主な違いは、ID はテーブルに依存するのに対し、シーケンスはテーブルに依存しないことです。それらの違いを表形式にまとめてみましょう。
| 身元 | 順序 |
|---|---|
| ID プロパティは特定のテーブルに使用され、他のテーブルと共有することはできません。 | DBA は、テーブルから独立しているため、複数のテーブル間で共有できるシーケンス オブジェクトを定義します。 |
| このプロパティは、テーブルに対して挿入ステートメントが実行されるたびに値を自動生成します。 | NEXT VALUE FOR 句を使用して、シーケンス オブジェクトの次の値を生成します。 |
| SQL Server は、ID プロパティの列値を初期値にリセットしません。 | SQL Server はシーケンス オブジェクトの値をリセットできます。 |
| ID プロパティの最大値を設定することはできません。 | シーケンスオブジェクトの最大値を設定できます。 |
| SQL Server 2000 で導入されました。 | SQL Server 2012 で導入されました。 |
| このプロパティは、降順で ID 値を生成できません。 | 降順で値を生成できます。 |
結論
この記事では、SQL Server の IDENTITY プロパティの完全な概要を説明します。ここでは、identity プロパティがいつどのように使用されるか、そのさまざまな機能、誤解、シーケンスとの違いについて学びました。