すべての要素が順番に配置された配列、リンク リスト、スタック、キューなどの線形データ構造を読み取ります。異なる種類のデータには異なるデータ構造が使用されます。
データ構造を選択する際には、いくつかの要素が考慮されます。
木 階層データを表すデータ構造の 1 つでもあります。従業員とその役職を階層形式で表示したいとすると、次のように表すことができます。
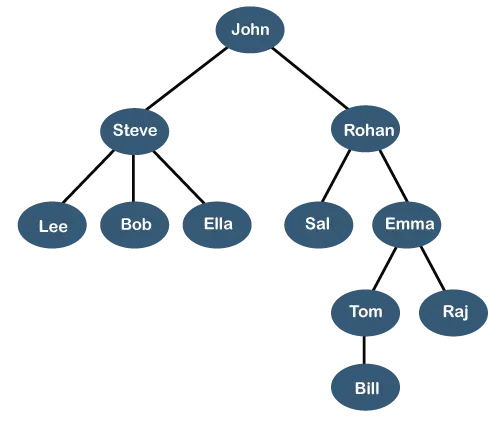
上のツリーは、 組織階層 どこかの会社の。上記の構造では、 ジョン それは 最高経営責任者(CEO) ジョンには会社の直属の部下が 2 人います。 スティーブ そして ロハン 。 Steve には 3 人の直属の部下がいます。 リー、ボブ、エラ どこ スティーブ マネージャーです。 Bob には 2 人の直属の部下がいます。 するものとする そして エマ 。 エマ という名前の直属の部下が 2 人います トム そして ラージ 。トムには という名前の直属の部下が 1 人います 請求書 。この特定の論理構造は、 木 。その構造が本物の木に似ているので、 木 。この構造では、 根 が頂上にあり、その枝は下方向に動いています。したがって、Tree データ構造はデータを階層的に保存する効率的な方法であると言えます。
SQLデータ型
Tree データ構造の重要なポイントをいくつか理解しましょう。
- ツリー データ構造は、階層を表現またはシミュレートするために相互にリンクされるノードと呼ばれるオブジェクトまたはエンティティのコレクションとして定義されます。
- ツリー データ構造は、順次に格納されないため、非線形データ構造です。ツリー内の要素が複数のレベルに配置されているため、これは階層構造です。
- Tree データ構造では、最上位のノードはルート ノードとして知られています。各ノードには何らかのデータが含まれており、データのタイプは任意です。上記のツリー構造では、ノードに従業員の名前が含まれているため、データのタイプは文字列になります。
- 各ノードには、いくつかのデータと、子と呼ばれる他のノードのリンクまたは参照が含まれています。
Tree データ構造で使用されるいくつかの基本用語。
以下に示すツリー構造を考えてみましょう。

上記の構造では、各ノードには何らかの番号が付けられています。上図に示されている各矢印は、 リンク 2 つのノード間。
Tree データ構造のプロパティ

Tree データ構造のプロパティに基づいて、ツリーはさまざまなカテゴリに分類されます。
ツリーの実装
ツリー データ構造は、ポインタを使用してノードを動的に作成することによって作成できます。メモリ内のツリーは次のように表すことができます。

上の図は、メモリ内のツリー データ構造の表現を示しています。上記の構造では、ノードに 3 つのフィールドが含まれています。 2 番目のフィールドにはデータが保存されます。最初のフィールドには左の子のアドレスが格納され、3 番目のフィールドには右の子のアドレスが格納されます。
プログラミングでは、ノードの構造は次のように定義できます。
struct node { int data; struct node *left; struct node *right; } バイナリ ツリーは最大 2 つの子を持つことができ、汎用ツリーは 3 つ以上の子を持つことができるため、上記の構造はバイナリ ツリーに対してのみ定義できます。一般的なツリーのノードの構造は、バイナリ ツリーと比較すると異なります。
SQLの主キーと複合キー
樹木の応用
ツリーの用途は次のとおりです。
Treeデータ構造の種類
ツリー データ構造のタイプは次のとおりです。

あり得る n 一般的なツリー内のサブツリーの数。一般的なツリーでは、サブツリー内のノードに順序を付けることができないため、サブツリーには順序がありません。
空ではないすべてのツリーには下向きのエッジがあり、これらのエッジは、 子ノード 。ルート ノードにはレベル 0 のラベルが付けられます。同じ親を持つノードは、 兄弟 。

バイナリ ツリーの詳細については、以下のリンクをクリックしてください。
https://www.javatpoint.com/binary-tree
左側のサブツリーの各ノードにはルート ノードの値より小さい値が含まれている必要があり、右側のサブツリーの各ノードの値はルート ノードの値より大きくなければなりません。
ノードは、ユーザー定義のデータ型を使用して作成できます。 構造体、 以下に示すように:
struct node { int data; struct node *left; struct node *right; } 上記は 3 つのフィールドを持つノード構造です: データ フィールド、2 番目のフィールドはノード タイプの左ポインタ、3 番目のフィールドはノード タイプの右ポインタです。
二分探索ツリーの詳細については、以下のリンクをクリックしてください。
https://www.javatpoint.com/binary-search-tree
二分木の一種、あるいは二分探索木の変形とも言えます。 AVL ツリーは次の特性を満たします。 二分木 同様に 二分探索木 。これは、によって発明された自己平衡二分探索木です。 アデルソン・ヴェルスキー・リンダス 。ここで、自己平衡化とは、左の部分木の高さと右の部分木の高さのバランスをとることを意味します。このバランスは次の観点から測定されます。 バランス係数 。
ツリーが二分探索ツリーおよびバランシング係数に従う場合、そのツリーを AVL ツリーとみなすことができます。バランス係数は次のように定義できます。 左のサブツリーの高さと右のサブツリーの高さの差 。バランス係数の値は 0、-1、または 1 のいずれかでなければなりません。したがって、AVL ツリー内の各ノードには、バランス係数の値が 0、-1、または 1 のいずれかである必要があります。
AVL ツリーの詳細については、以下のリンクをクリックしてください。
https://www.javatpoint.com/avl-tree
赤黒の木 二分探索木です。赤黒ツリーの前提条件は、二分探索ツリーについて知っている必要があることです。二分探索ツリーでは、左側のサブツリーの値はそのノードの値より小さく、右側のサブツリーの値はそのノードの値より大きくなければなりません。ご存知のとおり、平均的な場合の二分探索の時間計算量は対数です。2n の場合、最良のケースは O(1)、最悪のケースは O(n) です。
ツリー上で何らかの操作を実行するときは、検索、挿入、削除などのすべての操作にかかる時間が短縮されるようにツリーのバランスをとります。また、これらすべての操作の時間計算量は次のとおりです。 ログ2n.
赤黒の木 自己平衡二分探索木です。 AVL ツリーは高さバランシング二分探索ツリーでもあります。 なぜ赤黒木が必要なのか 。 AVL ツリーでは、ツリーのバランスをとるために何回回転する必要があるかわかりませんが、赤黒ツリーでは、ツリーのバランスをとるために最大 2 回転が必要です。これには、ツリーのバランスを確保するために、ノードの赤または黒のいずれかを表す追加ビットが 1 つ含まれています。
スプレイ ツリー データ構造も二分探索ツリーであり、最近アクセスされた要素がいくつかの回転操作を実行することによってツリーのルート位置に配置されます。ここ、 広がる 最近アクセスされたノードを意味します。それは 自己バランスをとる のような明示的なバランス条件を持たない二分探索木 AVL 木。
スプレイ ツリーの高さのバランスが取れていない可能性があります。つまり、左右のサブツリーの高さが異なる可能性がありますが、スプレイ ツリーの操作は次の順序で行われます。 落ち着いた 時間どこ n はノードの数です。
スプレイ ツリーはバランスの取れたツリーですが、各操作後に回転が実行されてバランスの取れたツリーになるため、高さのバランスのとれたツリーとは見なされません。
Treap データ構造は、Tree および Heap データ構造から派生したものです。したがって、これはツリーとヒープの両方のデータ構造のプロパティで構成されます。二分探索ツリーでは、左側のサブツリーの各ノードはルート ノードの値以下でなければならず、右側のサブツリーの各ノードはルート ノードの値以上である必要があります。ヒープ データ構造では、左右のサブツリーの両方にルートより大きなキーが含まれています。したがって、ルート ノードには最低値が含まれていると言えます。
treap データ構造では、各ノードは両方を持ちます。 鍵 そして 優先度 ここで、キーは二分探索ツリーから派生し、優先度はヒープ データ構造から派生します。
の トレプ データ構造は、以下に示す 2 つのプロパティに従います。
マイクリケットライブ
- ノードの右の子>=現在のノード、およびノードの左の子<=current node (binary tree)< li>
- サブツリーの子はノード (ヒープ) より大きくなければなりません
B ツリーはバランスが取れています エムウェイ 木どこ メートル ツリーの順序を定義します。これまで、ノードにはキーが 1 つしか含まれていないと説明しましたが、B ツリーには複数のキーと 2 つ以上の子を持つことができます。ソートされたデータは常に維持されます。バイナリ ツリーでは、リーフ ノードが異なるレベルにある可能性がありますが、B ツリーでは、すべてのリーフ ノードが同じレベルにある必要があります。
order が m の場合、ノードには次のプロパティがあります。
- B ツリー内の各ノードには最大値を含めることができます。 メートル 子供たち
- 最小の子の場合、リーフ ノードには 0 個の子があり、ルート ノードには最小 2 つの子があり、内部ノードには m/2 の最小上限があります。たとえば、m の値は 5 です。これは、ノードに 5 つの子を含めることができ、内部ノードには最大 3 つの子を含めることができることを意味します。
- 各ノードには最大 (m-1) 個のキーがあります。
ルート ノードには少なくとも 1 つのキーが含まれている必要があり、他のすべてのノードには少なくとも 1 つのキーが含まれている必要があります。 m/2マイナス1の天井 キー。