機械学習は次の分野です。 人工知能 これは、すべてのタスクについて明示的にプログラムすることなく、コンピューターがデータから学習し、以前の経験から改善できるモデルとアルゴリズムの開発に焦点を当てています。 簡単に言うと、ML はデータから学習することで、システムに人間と同じように考え、理解するよう教えます。
この記事では、さまざまな問題について説明します。 の種類 機械学習アルゴリズム これらは将来の要件にとって重要です。 機械学習 一般に、過去の経験から学び、時間の経過とともにパフォーマンスを向上させるためのトレーニング システムです。 機械学習 大量のデータの予測に役立ちます。迅速かつ正確な結果を提供して、収益性の高い機会を得るのに役立ちます。
機械学習の種類
機械学習にはいくつかの種類があり、それぞれに特別な特徴と用途があります。機械学習アルゴリズムの主なタイプのいくつかは次のとおりです。
- 教師あり機械学習
- 教師なし機械学習
- 半教師あり機械学習
- 強化学習
機械学習の種類
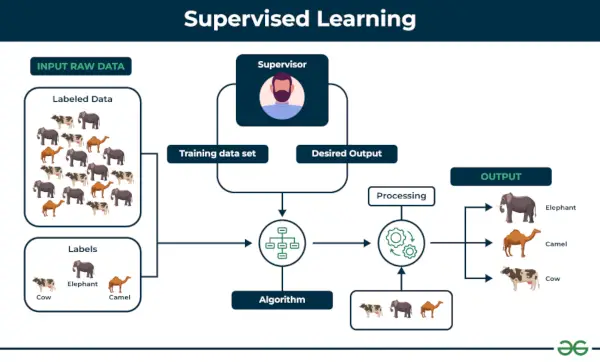
1.教師あり機械学習
教師あり学習 モデルがトレーニングされるときとして定義されます。 ラベル付きデータセット 。ラベル付きデータセットには、入力パラメーターと出力パラメーターの両方があります。で 教師あり学習 アルゴリズムは、入力間のポイントをマッピングして出力を修正する方法を学習します。トレーニング データセットと検証データセットの両方がラベル付けされています。
教師あり学習
例を使って理解してみましょう。
例: 猫と犬を区別するために画像分類器を構築する必要があるシナリオを考えてみましょう。犬と猫のラベル付き画像のデータセットをアルゴリズムにフィードすると、マシンはこれらのラベル付き画像から犬と猫を分類することを学習します。これまで見たことのない新しい犬や猫の画像を入力すると、学習したアルゴリズムを使用して、それが犬であるか猫であるかを予測します。こうやって 教師あり学習 これは特に画像分類です。
教師あり学習には、以下に示す 2 つの主要なカテゴリがあります。
- 分類
- 回帰
分類
分類 予測を扱う カテゴリー的な ターゲット変数。離散クラスまたはラベルを表します。たとえば、電子メールをスパムかスパムではないかを分類したり、患者が心臓病のリスクが高いかどうかを予測したりすることができます。分類アルゴリズムは、入力特徴を事前定義されたクラスの 1 つにマッピングすることを学習します。
いくつかの分類アルゴリズムを次に示します。
回帰
回帰 一方、予測を扱います。 継続的な 数値を表すターゲット変数。たとえば、サイズ、場所、設備に基づいて家の価格を予測したり、製品の売上を予測したりすることができます。回帰アルゴリズムは、入力特徴を連続数値にマッピングすることを学習します。
いくつかの回帰アルゴリズムを次に示します。
教師あり機械学習の利点
- 教師あり学習 モデルはトレーニングされているため、高い精度を得ることができます。 ラベル付きデータ 。
- 教師あり学習モデルにおける意思決定のプロセスは、多くの場合解釈可能です。
- 多くの場合、事前トレーニングされたモデルで使用できるため、新しいモデルを最初から開発する場合に時間とリソースを節約できます。
教師あり機械学習の欠点
- パターンを知ることには限界があり、トレーニング データに存在しない、目に見えないパターンや予期しないパターンに苦戦する可能性があります。
- に依存するため、時間とコストがかかる可能性があります。 ラベルが貼られた データのみ。
- 新しいデータに基づいた一般化が不十分になる可能性があります。
教師あり学習の応用
教師あり学習は、次のようなさまざまなアプリケーションで使用されます。
- 画像分類 : 画像内のオブジェクト、顔、その他の特徴を識別します。
- 自然言語処理: 感情、エンティティ、関係などの情報をテキストから抽出します。
- 音声認識 :話し言葉をテキストに変換します。
- レコメンドシステム : ユーザーにパーソナライズされた推奨事項を作成します。
- 予測分析 : 売上、顧客離れ、株価などの結果を予測します。
- 医学的診断 : 病気やその他の病状を検出します。
- 不正行為の検出 : 不正な取引を特定します。
- 自動運転車 : 環境内のオブジェクトを認識して反応します。
- 電子メールのスパム検出 : メールをスパムか非スパムに分類します。
- 製造における品質管理 :製品に欠陥がないか検査します。
- 信用スコアリング : 借り手がローンを滞納するリスクを評価します。
- ゲーム :キャラクターを認識し、プレイヤーの行動を分析し、NPCを作成します。
- 顧客サポート : カスタマー サポート タスクを自動化します。
- 天気予報 : 気温、降水量、その他の気象パラメータを予測します。
- スポーツ分析 : プレーヤーのパフォーマンスを分析し、ゲームを予測し、戦略を最適化します。
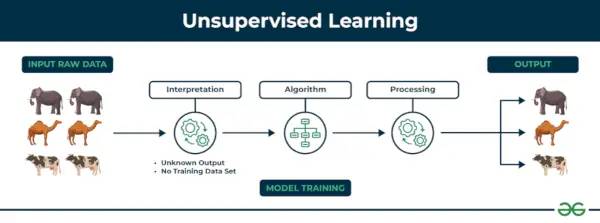
2.教師なし機械学習
教師なし学習 教師なし学習は、ラベルのないデータを使用してアルゴリズムがパターンと関係を発見する機械学習手法の一種です。教師あり学習とは異なり、教師なし学習では、ラベル付きのターゲット出力をアルゴリズムに提供する必要がありません。教師なし学習の主な目的は、多くの場合、データ内の隠れたパターン、類似性、またはクラスターを発見することであり、これらはデータ探索、視覚化、次元削減などのさまざまな目的に使用できます。
教師なし学習
例を使って理解してみましょう。
例: ショップでの購入に関する情報を含むデータセットがあると考えてください。クラスタリングを通じて、アルゴリズムはあなたと他の顧客の間で同じ購入行動をグループ化することができ、事前定義されたラベルのない潜在的な顧客を明らかにします。この種の情報は、企業が対象顧客を獲得したり、外れ値を特定したりするのに役立ちます。
教師なし学習には、以下に示す 2 つの主要なカテゴリがあります。
- クラスタリング
- 協会
クラスタリング
クラスタリング データ ポイントをその類似性に基づいてクラスターにグループ化するプロセスです。この手法は、ラベル付きの例を必要とせずに、データ内のパターンと関係を識別するのに役立ちます。
いくつかのクラスタリング アルゴリズムを次に示します。
- K-Means クラスタリング アルゴリズム
- 平均値シフトアルゴリズム
- DBSCAN アルゴリズム
- 主成分分析
- 独立成分分析
協会
アソシエーションルールを学習する ing は、データセット内のアイテム間の関係を発見するための手法です。これは、あるアイテムの存在が特定の確率で別のアイテムの存在を暗示することを示すルールを識別します。
いくつかの相関ルール学習アルゴリズムを次に示します。
- アプリオリアルゴリズム
- グロー
- FP成長アルゴリズム
教師なし機械学習の利点
- これは、隠れたパターンやデータ間のさまざまな関係を発見するのに役立ちます。
- などのタスクに使用されます。 顧客のセグメンテーション、異常検出、 そして データ探索 。
- ラベル付きデータは必要ないため、データのラベル付けの労力が軽減されます。
教師なし機械学習の欠点
- ラベルを使用しないと、モデルの出力の品質を予測することが困難になる場合があります。
- クラスターの解釈可能性は明確ではない可能性があり、意味のある解釈ができない可能性があります。
- などのテクニックがあります オートエンコーダ そして 次元削減 生データから意味のある特徴を抽出するために使用できます。
教師なし学習の応用
教師なし学習の一般的な応用例をいくつか示します。
- クラスタリング : 類似したデータ ポイントをクラスターにグループ化します。
- 異常検知 : データ内の外れ値または異常を特定します。
- 次元削減 : 重要な情報を維持しながら、データの次元を削減します。
- レコメンドシステム : ユーザーの過去の行動や好みに基づいて、製品、映画、またはコンテンツをユーザーに提案します。
- トピックモデリング : ドキュメントのコレクション内の潜在的なトピックを発見します。
- 密度推定 : データの確率密度関数を推定します。
- 画像とビデオの圧縮 : マルチメディア コンテンツに必要なストレージの量を削減します。
- データの前処理 : データ クリーニング、欠損値の代入、データ スケーリングなどのデータ前処理タスクを支援します。
- マーケットバスケット分析 : 製品間の関連性を発見します。
- ゲノムデータ解析 : パターンを特定したり、類似した発現プロファイルを持つ遺伝子をグループ化します。
- 画像のセグメンテーション : 画像を意味のある領域に分割します。
- ソーシャルネットワークでのコミュニティ検出 : 同様の興味やつながりを持つコミュニティまたは個人のグループを特定します。
- 顧客行動分析 : パターンと洞察を明らかにして、より良いマーケティングと製品の推奨を実現します。
- コンテンツの推奨 : コンテンツを分類してタグ付けすると、類似したアイテムをユーザーに推奨しやすくなります。
- 探索的データ分析 (EDA) : 特定のタスクを定義する前に、データを探索して洞察を得ることができます。
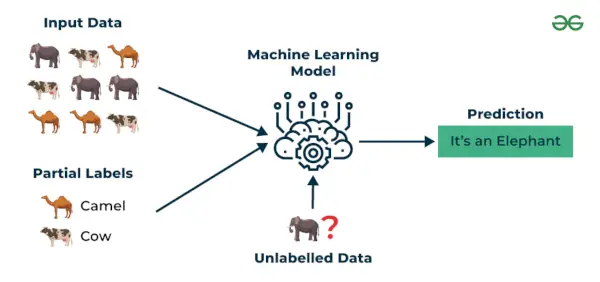
3. 半教師あり学習
半教師あり学習 の間で動作する機械学習アルゴリズムです。 監視されたものと監視されていないもの 両方を使用するように学習しています ラベル付きとラベルなし データ。これは、ラベル付きデータの取得にコスト、時間がかかる、またはリソースを大量に消費する場合に特に役立ちます。このアプローチは、データセットが高価で時間がかかる場合に役立ちます。半教師あり学習は、ラベル付きデータをトレーニングまたは学習するためにスキルと関連リソースが必要な場合に選択されます。
これらの手法は、少しラベルが付けられ、残りの大部分がラベルのないデータを扱う場合に使用します。教師なし手法を使用してラベルを予測し、これらのラベルを教師あり手法にフィードすることができます。この手法は、通常すべての画像にラベルが付けられていない画像データ セットの場合に主に適用できます。
意味不明
半教師あり学習
例を使って理解してみましょう。
例 : 言語翻訳モデルを構築していることを考えてください。すべての文ペアのラベル付き翻訳はリソースを大量に消費する可能性があります。これにより、モデルはラベル付き文とラベルなし文のペアから学習できるようになり、モデルの精度が向上します。この技術により、機械翻訳サービスの品質が大幅に向上しました。
半教師あり学習法の種類
半教師あり学習方法にはさまざまな方法があり、それぞれに独自の特徴があります。最も一般的なものには次のようなものがあります。
- グラフベースの半教師あり学習: このアプローチでは、グラフを使用してデータ ポイント間の関係を表します。次に、グラフを使用して、ラベル付きデータ ポイントからラベルなしデータ ポイントにラベルを伝播します。
- ラベルの伝播: このアプローチでは、データ ポイント間の類似性に基づいて、ラベル付きデータ ポイントからラベルなしデータ ポイントにラベルを繰り返し伝播します。
- 共同トレーニング: このアプローチでは、ラベルなしデータの異なるサブセットに対して 2 つの異なる機械学習モデルをトレーニングします。次に、2 つのモデルを使用して、互いの予測にラベルを付けます。
- セルフトレーニング: このアプローチでは、ラベル付きデータで機械学習モデルをトレーニングし、そのモデルを使用してラベルなしデータのラベルを予測します。次に、ラベル付きデータとラベルなしデータの予測ラベルでモデルが再トレーニングされます。
- 敵対的生成ネットワーク (GAN) : GAN は、合成データの生成に使用できる深層学習アルゴリズムの一種です。 GAN を使用すると、ジェネレーターとディスクリミネーターという 2 つのニューラル ネットワークをトレーニングすることにより、半教師あり学習用のラベルなしデータを生成できます。
半教師あり機械学習の利点
- と比較して、より良い一般化につながります。 教師あり学習、 ラベル付きデータとラベルなしデータの両方を受け取るためです。
- 幅広いデータに適用できます。
半教師あり機械学習の欠点
- 半監視付き これらのメソッドは、他のアプローチに比べて実装が複雑になる可能性があります。
- まだある程度必要です ラベル付きデータ いつでも入手できるとは限らず、簡単に入手できるとは限りません。
- ラベルのないデータは、それに応じてモデルのパフォーマンスに影響を与える可能性があります。
半教師あり学習の応用
半教師あり学習の一般的な応用例をいくつか示します。
- 画像分類と物体認識 : ラベル付き画像の少数のセットとラベルなし画像のより大きなセットを組み合わせることにより、モデルの精度が向上します。
- 自然言語処理 (NLP) : 少数のラベル付きテキスト データ セットと膨大な量のラベルなしテキストを組み合わせることにより、言語モデルと分類子のパフォーマンスを向上させます。
- 音声認識: 限られた量の文字起こしされた音声データと、より広範なラベルのない音声セットを活用することで、音声認識の精度を向上させます。
- レコメンデーションシステム : ユーザーとアイテムのインタラクションのまばらなセット (ラベル付きデータ) を、豊富なラベルなしのユーザー行動データで補完することで、パーソナライズされた推奨事項の精度を向上させます。
- ヘルスケアと医用画像処理 : 少数のラベル付き医療画像セットと、大規模なラベルなし画像セットを利用することで、医療画像分析を強化します。
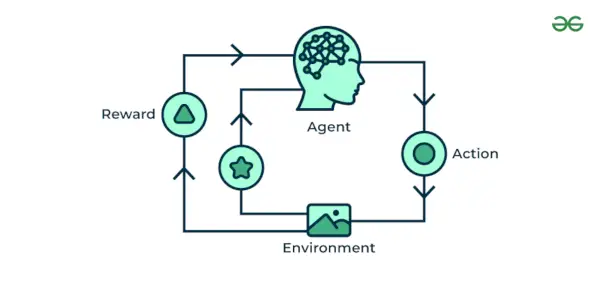
4. 強化機械学習
強化機械学習 アルゴリズムは、アクションを生成し、エラーを発見することによって環境と対話する学習方法です。 試行錯誤と遅れ これらは強化学習の最も重要な特性です。この手法では、モデルは報酬フィードバックを使用して動作やパターンを学習し、パフォーマンスを向上させ続けます。これらのアルゴリズムは特定の問題に特化しています。 Google の自動運転車、AlphaGo では、ボットが人間と、さらには自分自身と競争して、囲碁ゲームでより優れたパフォーマンスを獲得します。私たちがデータを入力するたびに、彼らは学習し、そのデータをトレーニング データである知識に追加します。したがって、学べば学ぶほど訓練され、経験が積まれます。
最も一般的な強化学習アルゴリズムの一部を次に示します。
- Qラーニング: Q 学習は、状態をアクションにマッピングする Q 関数を学習するモデルフリー RL アルゴリズムです。 Q 関数は、特定の状態で特定のアクションを取ることで期待される報酬を推定します。
- SARSA (状態-行動-報酬-状態-行動): SARSA は、Q 関数を学習する別のモデルフリー RL アルゴリズムです。ただし、Q 学習とは異なり、SARSA は最適なアクションではなく、実際に行われたアクションの Q 関数を更新します。
- ディープ Q ラーニング : ディープ Q ラーニングは、Q ラーニングとディープ ラーニングを組み合わせたものです。ディープ Q ラーニングでは、ニューラル ネットワークを使用して Q 関数を表現し、状態とアクションの間の複雑な関係を学習できます。
強化機械学習
例を使って理解しましょう。
例: あなたがトレーニングしていると考えてください。 AI チェスのようなゲームをプレイするエージェント。エージェントはさまざまな手を検討し、その結果に基づいて肯定的または否定的なフィードバックを受け取ります。強化学習は、周囲と対話することでタスクの実行方法を学習する用途にも使用されます。
強化機械学習の種類
強化学習には主に 2 つのタイプがあります。
正の強化
- 望ましいアクションをとったエージェントに報酬を与えます。
- エージェントにその行動を繰り返すよう促します。
- 例: 座っている犬におやつを与える、ゲームで正解にポイントを与える。
負の強化
- 望ましくない刺激を取り除き、望ましい行動を促します。
- エージェントが同じ動作を繰り返さないようにします。
- 例: レバーが押されたときに大音量のブザーを止める、タスクを完了することでペナルティを回避する。
強化機械学習の利点
- タスクに適した自律的な意思決定を備えており、ロボット工学やゲームプレイなど、一連の意思決定を行う方法を学習できます。
- この手法は、達成することが非常に難しい長期的な結果を達成するために推奨されます。
- 従来の技術では解決できない複雑な問題を解決するために使用されます。
強化機械学習の欠点
- 強化学習エージェントのトレーニングは、計算コストと時間がかかる場合があります。
- 強化学習は、単純な問題を解決することよりも好ましくありません。
- 大量のデータと大量の計算が必要となるため、非現実的でコストがかかります。
強化機械学習の応用
強化学習の応用例をいくつか示します。
- ゲームのプレイ : RL は、複雑なゲームであっても、エージェントにゲームのプレイ方法を教えることができます。
- ロボット工学 : RL はロボットに自律的にタスクを実行するよう教えることができます。
- 自動運転車 : RL は、自動運転車のナビゲーションと意思決定を支援します。
- レコメンデーションシステム : RL は、ユーザーの好みを学習することで推奨アルゴリズムを強化できます。
- 健康管理 : RL は、治療計画と創薬を最適化するために使用できます。
- 自然言語処理 (NLP) : RL は対話システムやチャットボットで使用できます。
- 金融と貿易 : RL はアルゴリズム取引に使用できます。
- サプライチェーンと在庫管理 : RL を使用すると、サプライ チェーンの運用を最適化できます。
- エネルギー管理 : RL を使用してエネルギー消費を最適化できます。
- AIゲーム : RL を使用すると、ビデオ ゲームでよりインテリジェントで適応性のある NPC を作成できます。
- アダプティブパーソナルアシスタント : RL はパーソナル アシスタントを改善するために使用できます。
- 仮想現実 (VR) と拡張現実 (AR): RL を使用すると、没入型でインタラクティブなエクスペリエンスを作成できます。
- 産業用制御 : RL を使用して産業プロセスを最適化できます。
- 教育 : RL を使用して適応学習システムを作成できます。
- 農業 : RL は農業作業を最適化するために使用できます。
に関する詳細記事を必ずご確認ください。 : 機械学習アルゴリズム
結論
結論として、各タイプの機械学習は独自の目的を果たし、強化されたデータ予測機能の開発における全体的な役割に貢献し、次のようなさまざまな業界を変える可能性があります。 データサイエンス 。大量のデータの生成とデータセットの管理に対処するのに役立ちます。
機械学習の種類 – FAQ
1. 教師あり学習で直面する課題は何ですか?
教師あり学習で直面する課題には、主に、クラスの不均衡への対処、高品質のラベル付きデータ、リアルタイム データに対するモデルのパフォーマンスが低下する過剰適合の回避などが含まれます。
2. 教師あり学習をどこに適用できますか?
教師あり学習は、スパムメールの分析、画像認識、感情分析などのタスクによく使用されます。
3. 機械学習の将来の見通しはどのようなものですか?
将来の展望としての機械学習は、天気や気候の分析、医療システム、自律モデリングなどの分野で機能する可能性があります。
4. 機械学習にはどのような種類がありますか?
機械学習には主に 3 つのタイプがあります。
- 教師あり学習
- 教師なし学習
- 強化学習
5. 最も一般的な機械学習アルゴリズムは何ですか?
最も一般的な機械学習アルゴリズムには次のようなものがあります。
- 線形回帰
- ロジスティック回帰
- サポート ベクター マシン (SVM)
- K 最近傍 (KNN)
- ディシジョンツリー
- ランダムフォレスト
- 人工ニューラルネットワーク