Excel シートは非常に直感的で使いやすいため、技術に詳しくない人でも大規模なデータセットを操作するのに最適です。を使用して Excel ファイル内の内容を操作および自動化する方法を学ぶ場所を探している場合 パイソン 、 これ以上探さない。あなたは正しい場所にいます。
この記事では、その使用方法を学びます パンダ Excel スプレッドシートを操作します。この記事では、次のことについて学びます。
- 読む Excelファイル Python でパンダを使用する
- パンダのインストールとインポート
- Pandas を使用して複数の Excel シートを読み取る
- さまざまな Pandas 機能のアプリケーション
Python で Pandas を使用して Excel ファイルを読み取る
パンダのインストール
Python に Pandas をインストールするには、コマンド プロンプトで次のコマンドを使用します。
pip install pandas>
Anaconda に Pandas をインストールするには、Anaconda ターミナルで次のコマンドを使用します。
conda install pandas>
パンダのインポート
まず最初に、Pandas モジュールをインポートする必要があります。これは、次のコマンドを実行して実行できます。
Python3
アルファベットから数字へ
import> pandas as pd> |
>
>
入力ファイル: Excel ファイルが次のようになっているとします。
シート 1:

シート1
シート 2:
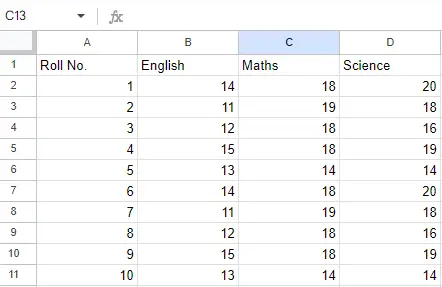
シート2
これで、Pandas の read_excel 関数を使用して Excel ファイルをインポートし、Python の Pandas を使用して Excel ファイルを読み取ることができます。 2 番目のステートメントは、Excel からデータを読み取り、変数 newData で表される pandas データ フレームに保存します。
Python3
df>=> pd.read_excel(>'Example.xlsx'>)> print>(df)> |
>
>
出力:
Roll No. English Maths Science 0 1 19 13 17 1 2 14 20 18 2 3 15 18 19 3 4 13 14 14 4 5 17 16 20 5 6 19 13 17 6 7 14 20 18 7 8 15 18 19 8 9 13 14 14 9 10 17 16 20>
Concat() メソッドを使用して複数のシートをロードする
Excel ワークブックに複数のシートがある場合、コマンドは最初のシートからデータをインポートします。ワークブック内のすべてのシートを含むデータ フレームを作成する最も簡単な方法は、異なるデータ フレームを個別に作成し、それらを連結することです。 read_excel メソッドは引数sheet_nameとindex_colを取り、以下に示すように、フレームを構成するシートを指定でき、index_colはタイトル列を指定します。
例:
3 番目のステートメントは両方のシートを連結します。データ フレーム全体を確認するには、次のコマンドを実行するだけです。
Python3
file> => 'Example.xlsx'> sheet1>=> pd.read_excel(>file>,> >sheet_name>=> 0>,> >index_col>=> 0>)> sheet2>=> pd.read_excel(>file>,> >sheet_name>=> 1>,> >index_col>=> 0>)> # concatinating both the sheets> newData>=> pd.concat([sheet1, sheet2])> print>(newData)> |
>
>
出力:
Roll No. English Maths Science 1 19 13 17 2 14 20 18 3 15 18 19 4 13 14 14 5 17 16 20 6 19 13 17 7 14 20 18 8 15 18 19 9 13 14 14 10 17 16 20 1 14 18 20 2 11 19 18 3 12 18 16 4 15 18 19 5 13 14 14 6 14 18 20 7 11 19 18 8 12 18 16 9 15 18 19 10 13 14 14>
Pandas の Head() メソッドと Tail() メソッド
データ フレームの上部と下部から 5 つの列を表示するには、次のコマンドを実行します。これ 頭() そして しっぽ() このメソッドは、表示する列の数を表す数値として引数も受け取ります。
Python3
print>(newData.head())> print>(newData.tail())> |
>
>
出力:
English Maths Science Roll No. 1 19 13 17 2 14 20 18 3 15 18 19 4 13 14 14 5 17 16 20 English Maths Science Roll No. 6 14 18 20 7 11 19 18 8 12 18 16 9 15 18 19 10 13 14 14>
Shape() メソッド
の シェイプ()メソッド 次のように、データ フレーム内の行と列の数を表示するために使用できます。
Python3
newData.shape> |
>
>
出力:
(20, 3)>
Pandas の Sort_values() メソッド
いずれかの列に数値データが含まれている場合は、 並べ替え値() パンダのメソッドは次のようになります。
Python3
CSSの中央ボタン
sorted_column>=> newData.sort_values([>'English'>], ascending>=> False>)> |
>
>
ここで、ソートされた列の上位 5 つの値が必要だと仮定します。ここで head() メソッドを使用できます。
Python3
配列Javaを返す
sorted_column.head(>5>)> |
>
>
出力:
English Maths Science Roll No. 1 19 13 17 6 19 13 17 5 17 16 20 10 17 16 20 3 15 18 19>
以下に示すように、データ フレームの任意の数値列でこれを行うことができます。
Python3
newData[>'Maths'>].head()> |
>
>
出力:
Roll No. 1 13 2 20 3 18 4 14 5 16 Name: Maths, dtype: int64>
パンダの Describe() メソッド
ここで、データの大部分が数値であると仮定します。を使用して、データ フレームに関する平均、最大、最小などの統計情報を取得できます。 説明する() 以下に示すような方法:
Python3
newData.describe()> |
>
>
出力:
English Maths Science count 20.00000 20.000000 20.000000 mean 14.30000 16.800000 17.500000 std 2.29645 2.330575 2.164304 min 11.00000 13.000000 14.000000 25% 13.00000 14.000000 16.000000 50% 14.00000 18.000000 18.000000 75% 15.00000 18.000000 19.000000 max 19.00000 20.000000 20.000000>
これは、次のコマンドを使用して、すべての数値列に対して個別に実行することもできます。
Python3
newData[>'English'>].mean()> |
>
>
出力:
14.3>
その他の統計情報もそれぞれの方法で計算できます。 Excel と同様に、数式を適用することもでき、次のように計算列を作成できます。
Python3
newData[>'Total Marks'>]>=> >newData[>'English'>]>+> newData[>'Maths'>]>+> newData[>'Science'>]> newData[>'Total Marks'>].head()> |
>
>
出力:
Roll No. 1 49 2 52 3 52 4 41 5 53 Name: Total Marks, dtype: int64>
データ フレーム内のデータを操作した後、メソッド to_excel を使用してデータを Excel ファイルにエクスポートして戻すことができます。このためには、以下に示すように、変換されたデータが書き込まれる出力 Excel ファイルを指定する必要があります。
Python3
Wordのクイックアクセスツールバー
newData.to_excel(>'Output File.xlsx'>)> |
>
>
出力:
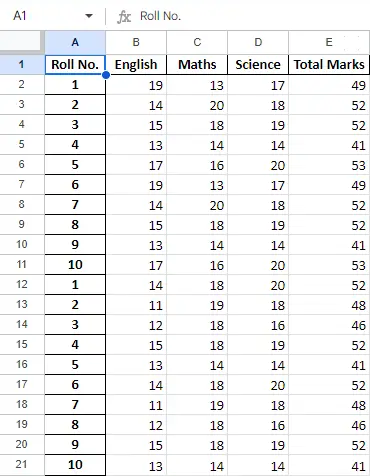
最終シート