JavaScript は非同期 (ノンブロッキング) のシングルスレッド プログラミング言語であり、一度に 1 つのプロセスのみを実行できます。
プログラミング言語では、コールバック地獄とは一般に、非同期呼び出しを使用してコードを記述する非効率的な方法を指します。破滅のピラミッドとしても知られています。
JavaScript のコールバック地獄とは、ネストされたコールバック関数が過剰に実行される状況を指します。コードの可読性とメンテナンス性が低下します。コールバック 地獄の状況は通常、複数の API リクエストを作成したり、複雑な依存関係を持つイベントを処理したりするなど、非同期リクエスト操作を処理するときに発生します。
JavaScript のコールバック地獄をよりよく理解するには、まず JavaScript のコールバックとイベント ループを理解します。
JavaScript でのコールバック
JavaScript は、文字列、配列、関数など、すべてをオブジェクトとしてみなします。したがって、コールバックの概念により、関数を引数として別の関数に渡すことができます。コールバック関数が最初に実行を完了し、親関数が後で実行されます。
コールバック関数は非同期で実行されるため、非同期タスクの完了を待たずにコードの実行を継続できます。複数の非同期タスクが結合され、各タスクが前のタスクに依存する場合、コード構造は複雑になります。
コールバックの使用法と重要性を理解しましょう。例として、1 つの文字列と 2 つの数値という 3 つのパラメーターを取る関数があるとします。複数の条件を含む文字列テキストに基づいた出力が必要です。
以下の例を考えてみましょう。
function expectedResult(action, x, y){ if(action === 'add'){ return x+y }else if(action === 'subtract'){ return x-y } } console.log(expectedResult('add',20,10)) console.log(expectedResult('subtract',30,10)) 出力:
30 20
上記のコードは問題なく動作しますが、コードをスケーラブルにするためにさらにタスクを追加する必要があります。条件ステートメントの数も増え続けるため、コード構造が複雑になり、最適化して読みやすくする必要があります。
したがって、次のようにコードをより適切な方法で書き直すことができます。
function add(x,y){ return x+y } function subtract(x,y){ return x-y } function expectedResult(callBack, x, y){ return callBack(x,y) } console.log(expectedResult(add, 20, 10)) console.log(expectedResult(subtract, 30, 10)) 出力:
30 20
それでも、出力は同じになります。ただし、上記の例では、別の関数本体を定義し、その関数をコールバック関数として ExpectedResult 関数に渡しています。したがって、期待される結果の機能を拡張して、別の操作を行う別の関数本体を作成し、それをコールバック関数として使用できるようにする場合、コードが理解しやすくなり、読みやすさが向上します。
サポートされている JavaScript 機能で使用できるコールバックの別の例は他にもあります。一般的な例としては、イベント リスナーや、map、reduce、filter などの配列関数があります。
女優ルビーナ ディライク
これをよりよく理解するには、JavaScript の値渡しと参照渡しを理解する必要があります。
JavaScript は、プリミティブと非プリミティブの 2 種類のデータ型をサポートします。プリミティブ データ型は、未定義、null、string、および boolean であり、変更できません。比較的不変であると言えます。非プリミティブ データ型は、変更または変更可能な配列、関数、およびオブジェクトです。
参照渡しでは、関数を引数として取ることができるのと同様に、エンティティの参照アドレスを渡します。したがって、その関数内の値が変更されると、関数の外部で使用可能な元の値も変更されます。
比較的、値渡しの概念は元の値を変更せず、関数本体の外部で使用できます。代わりに、メモリを使用して値を 2 つの異なる場所にコピーします。 JavaScript はすべてのオブジェクトを参照によって識別しました。
JavaScript では、addEventListener はクリック、マウスオーバー、マウスアウトなどのイベントをリッスンし、イベントがトリガーされると実行される関数として 2 番目の引数を受け取ります。この関数は参照渡しの概念で使用され、かっこなしで使用して渡されます。
以下の例を考えてみましょう。この例では、greet 関数を引数として addEventListener にコールバック関数として渡しています。クリック イベントがトリガーされると呼び出されます。
テスト.html:
Javascript Callback Example <h3>Javascript Callback</h3> Click Here to Console const button = document.getElementById('btn'); const greet=()=>{ console.log('Hello, How are you?') } button.addEventListener('click', greet) 出力:
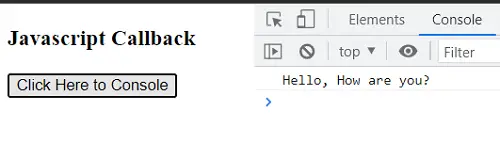
上の例では、greet 関数を引数として addEventListener にコールバック関数として渡しています。クリック イベントがトリガーされると呼び出されます。
同様に、フィルターもコールバック関数の一例です。フィルターを使用して配列を反復処理する場合、フィルターは別のコールバック関数を引数として受け取り、配列データを処理します。以下の例を考えてみましょう。この例では、greater 関数を使用して、配列内の 5 より大きい数値を出力します。 isGreater 関数をフィルター メソッドのコールバック関数として使用しています。
const arr = [3,10,6,7] const isGreater = num => num > 5 console.log(arr.filter(isGreater))
出力:
[ 10, 6, 7 ]
上記の例は、大きい関数がフィルター メソッドのコールバック関数として使用されていることを示しています。
C++で優先キュー
JavaScript のコールバックやイベント ループをより深く理解するために、同期 JavaScript と非同期 JavaScript について説明します。
同期JavaScript
同期プログラミング言語の特徴を理解しましょう。同期プログラミングには次の機能があります。
実行のブロック: 同期プログラミング言語は、ブロック実行手法をサポートしています。これは、既存のステートメントが実行される後続のステートメントの実行をブロックすることを意味します。これにより、ステートメントの予測可能かつ決定的な実行が実現します。
シーケンシャルフロー: 同期プログラミングは、実行のシーケンシャル フローをサポートします。つまり、各ステートメントが次々とシーケンシャルに実行されることを意味します。言語プログラムは、ステートメントが完了するのを待ってから、次のステートメントに進みます。
シンプルさ: 多くの場合、同期プログラミングは実行フローの順序を予測できるため、理解しやすいと考えられています。一般に、それは線形であり、予測が簡単です。小規模なアプリケーションは、重要な操作順序を処理できるため、これらの言語で開発するのが適しています。
直接的なエラー処理: 同期プログラミング言語では、エラー処理は非常に簡単です。ステートメントの実行中にエラーが発生した場合、エラーがスローされ、プログラムはそれをキャッチできます。
一言で言えば、同期プログラミングには 2 つの主要な機能があります。つまり、一度に 1 つのタスクが実行され、現在のタスクが終了した後でのみ後続の一連のタスクが処理されます。これにより、シーケンシャルなコード実行が続きます。
ステートメントの実行時のプログラミングのこの動作では、各ジョブが前のジョブが完了するまで待機する必要があるため、言語によってブロック コードの状況が作成されます。
しかし、JavaScript について話すとき、それが同期なのか非同期なのかは常に不可解な答えになります。
上で説明した例では、関数をフィルター関数のコールバックとして使用すると、同期的に実行されました。したがって、これは同期実行と呼ばれます。フィルター関数は、より大きな関数が実行を完了するまで待つ必要があります。
したがって、コールバック関数は、呼び出された親関数の実行をブロックするため、ブロッキング コールバックとも呼ばれます。
主に、JavaScript は本質的にシングルスレッドの同期およびブロックとみなされます。ただし、いくつかのアプローチを使用すると、さまざまなシナリオに基づいて非同期で動作させることができます。
ここで、非同期 JavaScript について理解しましょう。
非同期JavaScript
非同期プログラミング言語は、アプリケーションのパフォーマンスを向上させることに重点を置いています。コールバックはこのようなシナリオで使用できます。以下の例で JavaScript の非同期動作を分析できます。
function greet(){ console.log('greet after 1 second') } setTimeout(greet, 1000) 上記の例から、setTimeout 関数はコールバックとミリ秒単位の時間を引数として受け取ります。コールバックは、指定された時間 (ここでは 1 秒) の後に呼び出されます。簡単に言うと、関数は実行まで 1 秒待機します。次に、以下のコードを見てください。
Javaのデフォルトパラメータ
function greet(){ console.log('greet after 1 second') } setTimeout(greet, 1000) console.log('first') console.log('Second') 出力:
first Second greet after 1 second
上記のコードから、タイマーが経過するまで、setTimeout の後のログ メッセージが最初に実行されます。したがって、1 秒後にグリーティング メッセージが生成され、1 秒の時間間隔後にグリーティング メッセージが生成されます。
JavaScript では、setTimeout は非同期関数です。 setTimeout 関数を呼び出すたびに、指定された遅延の後に実行されるコールバック関数 (この場合は、greet) が登録されます。ただし、後続のコードの実行はブロックされません。
上記の例では、ログ メッセージはすぐに実行される同期ステートメントです。これらは setTimeout 関数には依存しません。したがって、setTimeout で指定された遅延を待たずに、それぞれのメッセージを実行してコンソールに記録します。
一方、JavaScript のイベント ループは非同期タスクを処理します。この場合、指定された遅延 (1 秒) が経過するまで待機し、その時間が経過した後、コールバック関数 (greet) を取得して実行します。
したがって、setTimeout 関数の後の他のコードは、バックグラウンドで実行中に実行されていました。この動作により、JavaScript は非同期操作が完了するのを待機している間に他のタスクを実行できるようになります。
JavaScript で非同期イベントを処理するには、コール スタックとコールバック キューを理解する必要があります。
以下の画像を考えてみましょう。

上の図から、一般的な JavaScript エンジンはヒープ メモリとコール スタックで構成されています。コール スタックは、スタックにプッシュされると、待機せずにすべてのコードを実行します。
ヒープ メモリは、実行時に必要なときにオブジェクトと関数にメモリを割り当てる役割を果たします。
現在、ブラウザ エンジンは DOM、setTimeout、コンソール、フェッチなどのいくつかの Web API で構成されており、エンジンはグローバル ウィンドウ オブジェクトを使用してこれらの API にアクセスできます。次のステップでは、一部のイベント ループがゲートキーパーの役割を果たし、コールバック キュー内の関数リクエストを選択してスタックにプッシュします。 setTimeout などのこれらの関数には、一定の待ち時間が必要です。
ここで、setTimeout 関数の例に戻りましょう。関数が検出されると、タイマーがコールバック キューに登録されます。この後、コードの残りの部分はコール スタックにプッシュされ、関数がタイマー制限に達すると期限切れになり、コールバック キューが指定されたロジックを持ち、タイムアウト関数に登録されているコールバック関数をプッシュします。 。したがって、指定された時間の後に実行されます。
コールバック地獄のシナリオ
ここまで、コールバック、同期、非同期、およびその他のコールバック地獄に関連するトピックについて説明しました。 JavaScript におけるコールバック地獄とは何かを理解しましょう。
複数のコールバックが入れ子になっている状況は、コードの形状がピラミッドのように見えるため、コールバック地獄として知られており、「破滅のピラミッド」とも呼ばれています。
コールバック地獄により、コードの理解と保守が困難になります。この状況は主に、ノード JS で作業しているときに確認できます。たとえば、次の例を考えてみましょう。
getArticlesData(20, (articles) => { console.log('article lists', articles); getUserData(article.username, (name) => { console.log(name); getAddress(name, (item) => { console.log(item); //This goes on and on... } }) 上記の例では、getUserData は記事リストに依存するユーザー名、または記事内の getArticles 応答を抽出する必要があるユーザー名を受け取ります。 getAddress にも同様の依存関係があり、getUserData の応答に依存します。この状況をコールバック地獄と呼びます。
コールバック ヘルの内部動作は、以下の例で理解できます。
タスク A を実行する必要があることを理解しましょう。タスクを実行するには、タスク B からのデータが必要です。同様に、タスク B からのデータが必要です。相互に依存し、非同期で実行されるさまざまなタスクがあります。したがって、一連のコールバック関数が作成されます。
JavaScript の Promise と、それが非同期操作を作成する方法を理解して、ネストされたコールバックの記述を回避できるようにしましょう。
JavaScript の約束
JavaScript では、Promise が ES6 で導入されました。これは構文コーティングが施されたオブジェクトです。非同期動作のため、これは非同期操作のコールバックの作成を回避するための代替方法です。現在、 fetch() などの Web API は、サーバーからデータに効率的にアクセスする方法を提供する有望な方法を使用して実装されています。また、コードの可読性も向上し、ネストされたコールバックの作成を回避する方法になります。
実生活における約束は、2 人以上の人の間の信頼と、特定のことが確実に起こるという保証を表します。 JavaScript では、Promise は、将来 (必要な場合) に単一の値を生成することを保証するオブジェクトです。 JavaScript の Promise は、非同期操作の管理と取り組みに使用されます。
Promise は、非同期操作とその出力の完了または失敗を保証し、表すオブジェクトを返します。これは、正確な出力が不明な値のプロキシです。非同期アクションで、最終的な成功値または失敗の理由を提供するのに役立ちます。したがって、非同期メソッドは同期メソッドと同様に値を返します。
一般に、Promise には次の 3 つの状態があります。
- 完了: 完了状態は、適用されたアクションが解決または正常に完了したときの状態です。
- 保留中: 保留状態は、リクエストが処理中であり、適用されたアクションが解決も拒否もされておらず、まだ初期状態にあるときです。
- 拒否されました: 拒否された状態は、適用されたアクションが拒否され、目的の操作が失敗したときの状態です。拒否の原因には、サーバーのダウンなど、さまざまな原因が考えられます。
Promise の構文は次のとおりです。
let newPromise = new Promise(function(resolve, reject) { // asynchronous call is made //Resolve or reject the data }); 以下は、Promise の記述例です。
これは約束の書き方の例です。
function getArticleData(id) { return new Promise((resolve, reject) => { setTimeout(() => { console.log('Fetching data....'); resolve({ id: id, name: 'derik' }); }, 5000); }); } getArticleData('10').then(res=> console.log(res)) 上記の例では、Promise を効率的に使用してサーバーからリクエストを行う方法がわかります。上記のコードでは、コールバックよりもコードの可読性が向上していることがわかります。 Promise には、成功または失敗の場合の操作ステータスを処理できる .then() や .catch() などのメソッドが用意されています。 Promise のさまざまな状態のケースを指定できます。
JavaScript での非同期/待機
これは、ネストされたコールバックの使用を回避するもう 1 つの方法です。 Async/Await を使用すると、Promise をより効率的に使用できるようになります。 .then() または .catch() メソッド チェーンの使用を回避できます。これらのメソッドはコールバック関数にも依存します。
Async/Await を Promise と正確に併用して、アプリケーションのパフォーマンスを向上させることができます。 Promise を内部的に解決し、結果を提供しました。また、繰り返しになりますが、() メソッドや catch() メソッドよりも読みやすいです。
通常のコールバック関数では Async/Await を使用できません。これを使用するには、関数キーワードの前に async キーワードを記述して関数を非同期にする必要があります。ただし、内部的にはチェーンも使用します。
以下は Async/Await の例です。
async function displayData() { try { const articleData = await getArticle(10); const placeData = await getPlaces(article.name); const cityData = await getCity(place) console.log(city); } catch (err) { console.log('Error: ', err.message); } } displayData(); Async/Await を使用するには、関数を async キーワードで指定し、関数内に await キーワードを記述する必要があります。 async は、Promise が解決されるか拒否されるまで実行を停止します。プロミスが処理されると再開されます。解決されると、await 式の値はそれを保持する変数に格納されます。
まとめ:
一言で言えば、Promise と async/await を使用することで、ネストされたコールバックを回避できます。これらとは別に、コメントを書くなどの他のアプローチに従うこともできますし、コードを個別のコンポーネントに分割することも役立ちます。しかし、現在、開発者は async/await の使用を好んでいます。
結論:
JavaScript のコールバック地獄とは、ネストされたコールバック関数が過剰に実行される状況を指します。コードの可読性とメンテナンス性が低下します。コールバック 地獄の状況は通常、複数の API リクエストを作成したり、複雑な依存関係を持つイベントを処理したりするなど、非同期リクエスト操作を処理するときに発生します。
ラドヤード・キプリングによる要約の場合
JavaScript のコールバック地獄をより深く理解するため。
JavaScript は、文字列、配列、関数など、すべてをオブジェクトとしてみなします。したがって、コールバックの概念により、関数を引数として別の関数に渡すことができます。コールバック関数が最初に実行を完了し、親関数が後で実行されます。
コールバック関数は非同期で実行されるため、非同期タスクの完了を待たずにコードの実行を継続できます。