データ構造とは:
データ構造は、データを保存および整理するために使用されるストレージです。これは、効率的にアクセスして更新できるように、コンピュータ上でデータを配置する方法です。
データ構造は、データを整理するためだけに使用されるわけではありません。データの処理、取得、保存にも使用されます。開発されたほぼすべてのプログラムやソフトウェア システムでは、さまざまな基本タイプと高度なタイプのデータ構造が使用されています。したがって、データ構造についての十分な知識が必要です。
データ構造 は、メモリ内のデータの配置に使用されるコンピュータの不可欠な部分です。これらはデータを効率的に整理、処理、アクセス、保存するために不可欠であり、責任を負います。ただこれが全てではありません。さまざまなタイプのデータ構造には、それぞれの特性、特徴、用途、利点、欠点があります。では、特定のタスクに適したデータ構造をどのように特定すればよいでしょうか? 「データ構造」という用語は何を意味しますか?データ構造の種類は何種類あり、それらは何に使用されますか?

データ構造とは: 種類、分類、用途
ご対応させていただきます。データ構造とは何か、データ構造の種類、データ構造の分類、各データ構造の用途などについてすべてを網羅したリストを作成しました。この記事では、わずか数分で最適なものを選択できるように、各データ構造のあらゆる側面について説明します。
目次
データ構造がデータ型によってどのように異なるか:
データ構造についてはすでに学習しました。多くの場合、データ型とデータ構造の間で混乱が生じます。そこで、明確にするために、データ型とデータ構造の違いをいくつか見てみましょう。
| データ・タイプ | データ構造 |
|---|---|
| データ型は、値を割り当てることができる変数の形式です。これは、特定の変数が指定されたデータ型の値のみを割り当てることを定義します。 | データ構造は、さまざまな種類のデータの集合です。データ全体はオブジェクトを使用して表現でき、プログラム全体で使用できます。 |
| 値は保持できますが、データは保持できません。したがって、データレスです。 | 単一のオブジェクト内に複数のタイプのデータを保持できます。 |
| データ型の実装は、抽象実装として知られています。 Javaオブジェクト | データ構造の実装は具体的な実装として知られています。 |
| データ型の場合、時間の複雑さはありません。 | データ構造オブジェクトでは、時間計算量が重要な役割を果たします。 |
| データ型の場合、データの値は保存できるデータの種類を表すだけなので、データの値は保存されません。 | 一方、データ構造の場合、データとその値はコンピューターのメイン メモリ内のスペースを取得します。また、データ構造は、1 つのオブジェクト内にさまざまな種類やタイプのデータを保持できます。 |
| データ型の例は、int、float、double などです。 | データ構造の例としては、スタック、キュー、ツリーなどがあります。 |
データ構造の分類:
データ構造は日常生活でさまざまな用途に使用されます。さまざまな数学的および論理的問題を解決するために使用されるさまざまなデータ構造があります。データ構造を使用すると、比較的短期間で大量のデータを整理して処理できます。さまざまな状況で使用されるさまざまなデータ構造を見てみましょう。
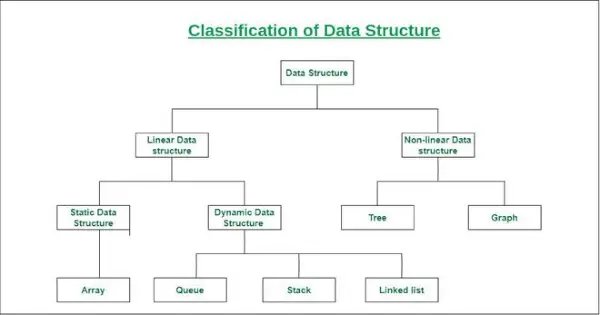
データ構造の分類
- 線形データ構造: データ要素が連続的または線形に配置され、各要素が前後の隣接する要素に関連付けられているデータ構造は、線形データ構造と呼ばれます。
線形データ構造の例には、配列、スタック、キュー、リンク リストなどがあります。- 静的データ構造: 静的データ構造のメモリ サイズは固定です。静的データ構造内の要素にアクセスする方が簡単です。
このデータ構造の例は配列です。 - 動的データ構造: 動的データ構造では、サイズは固定されません。ランタイム中にランダムに更新できるため、コードのメモリ (スペース) の複雑さに関して効率的であると考えられます。
このデータ構造の例としては、キュー、スタックなどが挙げられます。
- 静的データ構造: 静的データ構造のメモリ サイズは固定です。静的データ構造内の要素にアクセスする方が簡単です。
- 非線形データ構造: データ要素が連続的または線形に配置されていないデータ構造は、非線形データ構造と呼ばれます。非線形データ構造では、1 回の実行だけですべての要素を走査することはできません。
非線形データ構造の例としては、ツリーやグラフがあります。
データ構造の必要性:
データの構造とアルゴリズムの合成は相互に関連しています。開発者だけでなくユーザーも操作を効率的に実装できるように、データのプレゼンテーションは理解しやすくなければなりません。
データ構造は、データを整理、取得、管理、保存するための簡単な方法を提供します。
データのニーズのリストは次のとおりです。
- データ構造の変更が容易です。
- 必要な時間は短くなります。
- ストレージのメモリ容量を節約します。
- データ表現が簡単です。
- 大規模なデータベースに簡単にアクセスできます。
配列:
配列は線形データ構造であり、連続したメモリ位置に格納されている項目のコレクションです。同じ種類の複数のアイテムを 1 か所にまとめて保管するというアイデアです。比較的短期間で大量のデータを処理できます。配列の最初の要素には添字 0 が付けられます。配列では、検索、並べ替え、挿入、走査、反転、削除などのさまざまな操作が可能です。
MBからGBへ
配列
配列の特徴:
配列には次のようなさまざまな特性があります。
- 配列ではインデックスベースのデータ構造が使用されており、インデックスを使用して配列内の各要素を簡単に識別できます。
- ユーザーが同じデータ型の複数の値を保存したい場合、配列を効率的に利用できます。
- 配列は、データを 2 次元配列に格納することで、複雑なデータ構造を処理することもできます。
- 配列は、スタック、キュー、ヒープ、ハッシュ テーブルなどの他のデータ構造を実装するためにも使用されます。
- 配列内の検索処理は非常に簡単に行うことができます。
配列に対して実行される操作:
- 初期化 : 配列は、宣言時または後で代入ステートメントを使用して値で初期化できます。
- 要素へのアクセス: 配列内の要素には、0 から始まり配列のサイズから 1 を引いた値までのインデックスによってアクセスできます。
- 要素の検索 : 線形検索アルゴリズムまたは二分検索アルゴリズムを使用して、配列で特定の要素を検索できます。
- 要素の並べ替え : バブル ソート、挿入ソート、クイック ソートなどのアルゴリズムを使用して、配列内の要素を昇順または降順に並べ替えることができます。
- 要素の挿入: 配列の特定の位置に要素を挿入できますが、この操作には配列内の既存の要素を移動する必要があるため、時間がかかる可能性があります。
- 要素の削除: 要素を配列から削除するには、その後に続く要素を移動してギャップを埋めます。
- 要素の更新: 配列内の要素は、特定のインデックスに新しい値を割り当てることで更新または変更できます。
- 要素を横断する: 配列内の要素は、各要素を 1 回ずつ訪問することで、順番に走査できます。
これらは、配列に対して実行される最も一般的な操作の一部です。使用される具体的な操作とアルゴリズムは、問題の要件と使用されるプログラミング言語に応じて異なる場合があります。
アレイのアプリケーション:
配列のさまざまな用途は次のとおりです。
- 配列は行列問題を解く際に使用されます。
- データベース レコードも配列によって実装されます。
- 並べ替えアルゴリズムの実装に役立ちます。
- また、スタック、キュー、ヒープ、ハッシュ テーブルなどの他のデータ構造を実装するためにも使用されます。
- 配列は CPU のスケジューリングに使用できます。
- コンピュータのルックアップテーブルとして適用できます。
- 配列は、すべての音声信号が配列である音声処理で使用できます。
- パソコンの画面も配列で表示されます。ここでは多次元配列を使用します。
- この配列は、図書館、学生、議会などの多くの管理システムで使用されています。
- この配列はオンライン チケット予約システムで使用されます。携帯電話の連絡先はこの配列によって表示されます。
- オンライン チェスのようなゲームでは、プレイヤーは現在の手だけでなく過去の手を保存できます。位置のヒントを示します。
- Android で 360*1200 のような特定のサイズで画像を保存するには
配列の実際の応用:
- 配列は、数学的計算のデータを保存するためによく使用されます。
- 画像処理に使用されます。
- 記録管理にも使われます。
- 本のページも実際の配列の例です。
- 注文箱にも使用されます。
配列を始めてみませんか?ベスト プラクティスについては、厳選した記事とリストを試してみてください。
- 配列データ構造の概要
- 面接における配列コーディングの問題トップ 50
- techcodeview.com で配列の問題を練習する
リンクされたリスト:
リンク リストは、要素が連続したメモリ位置に格納されない線形データ構造です。リンク リスト内の要素は、次の図に示すようにポインターを使用してリンクされます。
リンクリストの種類:
- 単一リンクリスト
- 二重リンクリスト
- 循環リンクリスト
- 二重循環リンクリスト
リンクされたリスト
リンクリストの特徴:
リンク リストには次のようなさまざまな特徴があります。
- リンク リストは、リンクを保存するために余分なメモリを使用します。
- リンク リストの初期化中に、要素のサイズを知る必要はありません。
- リンク リストは、スタック、キュー、グラフなどを実装するために使用されます。
- リンクされたリストの最初のノードはヘッドと呼ばれます。
- 最後のノードの次のポインタは常に NULL を指します。
- リンクリストでは簡単に挿入・削除が可能です。
- リンクされたリストの各ノードは、次のノードのアドレスであるポインター/リンクで構成されます。
- リンクされたリストはいつでも簡単に縮小または拡大できます。
リンクされたリストに対して実行される操作:
リンク リストは、各ノードに値と次のノードへの参照が含まれる線形データ構造です。リンク リストに対して実行される一般的な操作をいくつか示します。
- 初期化: リンク リストは、最初のノードへの参照を持つヘッド ノードを作成することで初期化できます。後続の各ノードには、値と次のノードへの参照が含まれます。
- 要素の挿入: 要素は、リンクされたリストの先頭、末尾、または特定の位置に挿入できます。
- 要素の削除 : 前のノードの参照を次のノードを指すように更新することでリンク リストから要素を削除でき、リストから現在のノードを効果的に削除できます。
- 要素の検索 : リンクされたリストでは、ヘッド ノードから開始して、目的の要素が見つかるまで次のノードへの参照をたどることで、特定の要素を検索できます。
- 要素の更新 : リンクされたリスト内の要素は、特定のノードの値を変更することで更新できます。
- 要素を横断する: リンクされたリスト内の要素は、ヘッド ノードから開始して、リストの末尾に到達するまで次のノードへの参照をたどることによって走査できます。
- リンクされたリストを逆にする : リンクされたリストは、各ノードの参照を更新して、次のノードではなく前のノードを指すように逆にすることができます。
これらは、リンク リストに対して実行される最も一般的な操作の一部です。使用される具体的な操作とアルゴリズムは、問題の要件と使用されるプログラミング言語に応じて異なる場合があります。
リンクリストの用途:
リンク リストのさまざまな用途は次のとおりです。
- リンク リストは、スタック、キュー、グラフなどを実装するために使用されます。
- リンク リストは、長整数の算術演算を実行するために使用されます。
- スパース行列の表現に使用されます。
- ファイルのリンク割り当てに使用されます。
- メモリ管理に役立ちます。
- これは、各多項式項がリンク リスト内のノードを表す多項式操作の表現で使用されます。
- リンクされたリストは、イメージ コンテナーを表示するために使用されます。ユーザーは過去、現在、次の画像にアクセスできます。
- これらは、訪問したページの履歴を保存するために使用されます。
- これらは、元に戻す操作を実行するために使用されます。
- リンクは、タグの正しい構文を示すソフトウェア開発で使用されます。
- リンクされたリストは、ソーシャル メディア フィードを表示するために使用されます。
リンクされたリストの実際のアプリケーション:
- リンク リストは、マルチプレイヤー ゲームの順番を追跡するために、ラウンドロビン スケジューリングで使用されます。
- 画像ビューアで使用します。前と次の画像はリンクされているため、前ボタンと次ボタンでアクセスできます。
- 音楽プレイリストでは、曲は前後の曲にリンクされています。
リンクされたリストを始めてみませんか?ベスト プラクティスについては、厳選した記事とリストを試してみてください。
- リンク リスト データ構造の概要
- リンクされたリストのインタビューでの質問トップ 20
- techcodeview.com でリンク リスト問題を練習する
スタック:
スタックは、操作が実行される特定の順序に従う線形データ構造です。注文は LIFO(後入れ先出し) 。データの入力と取得は一方の端からのみ可能です。データの入力と取得は、スタックでのプッシュおよびポップ操作とも呼ばれます。スタックでは、再帰を使用したスタックの反転、並べ替え、スタックの中間要素の削除など、さまざまな操作が可能です。

スタック
スタックの特徴:
スタックには次のようなさまざまな特性があります。
- スタックは、ハノイ塔、ツリー トラバーサル、再帰などのさまざまなアルゴリズムで使用されます。
- スタックは配列またはリンク リストを通じて実装されます。
- これは後入れ先出し操作に従います。つまり、最初に挿入された要素が最後に挿入され、その逆も同様です。
- 挿入と削除は一方の端、つまりスタックの最上部から実行されます。
- スタックでは、スタックに割り当てられた領域がいっぱいであるにもかかわらず、さらに要素を追加しようとすると、スタック オーバーフローが発生します。
スタックの用途:
スタックのさまざまなアプリケーションは次のとおりです。
- スタック データ構造は、算術式の評価と変換に使用されます。
- 括弧のチェックに使用されます。
- 文字列を反転する際には、スタックも使用されます。
- スタックはメモリ管理に使用されます。
- 関数呼び出しの処理にも使用されます。
- スタックは、式を中置文字から後置文字に変換するために使用されます。
- スタックは、ワード プロセッサで元に戻す操作ややり直し操作を実行するために使用されます。
- スタックは JVM などの仮想マシンで使用されます。
- スタックはメディア プレーヤーで使用されます。次の曲や前の曲を再生するときに便利です。
- スタックは再帰操作で使用されます。
スタック上で実行される操作。
スタックは、後入れ先出し (LIFO) 原則を実装した線形データ構造です。スタック上で実行される一般的な操作をいくつか示します。
- 押す : 要素をスタックの一番上にプッシュして、新しい要素をスタックの一番上に追加できます。
- ポップ : 先頭の要素は、ポップ操作を実行することでスタックから削除でき、スタックにプッシュされた最後の要素を効果的に削除します。
- ピーク: 最上位の要素は、ピーク操作を使用してスタックから削除せずに検査できます。
- 空です : スタックが空かどうかを確認するためにチェックを行うことができます。
- サイズ : スタック内の要素の数は、サイズ演算を使用して決定できます。
これらは、スタック上で実行される最も一般的な操作の一部です。使用される具体的な操作とアルゴリズムは、問題の要件と使用されるプログラミング言語に応じて異なる場合があります。スタックは、式の評価、コンピュータ プログラムでの関数呼び出しスタックの実装などのアプリケーションでよく使用されます。
スタックの実際のアプリケーション:
- スタックの実際の例は、上下に並べられた食事用の皿の層です。山からプレートを取り除くと、そのプレートを山の一番上に持っていくことができます。しかし、これはまさに、最も最近に山に追加されたプレートです。プレートを山の一番下に置きたい場合は、そのプレートに到達するためにその上にあるすべてのプレートを削除する必要があります。
- ブラウザはスタック データ構造を使用して、以前にアクセスしたサイトを追跡します。
- モバイルの通話ログもスタック データ構造を使用します。
スタックを始めてみませんか?ベスト プラクティスについては、厳選した記事とリストを試してみてください。
決定論的有限オートマトン
- techcodeview.com でスタック問題を練習する
列:
キューは、操作が実行される特定の順序に従う線形データ構造です。注文は 先入れ先出し(FIFO) つまり、最初に保存されたデータ項目が最初にアクセスされます。この場合、データの入力と取得は一方の端からのみ行われるわけではありません。キューの例としては、最初に来たコンシューマが最初に処理されるリソースのコンシューマのキューが挙げられます。キューの反転 (再帰の使用の有無にかかわらず)、キューの最初の K 要素の反転など、さまざまな操作がキューに対して実行されます。キューで実行されるいくつかの基本的な操作には、エンキュー、デキュー、フロント、リアなどがあります。
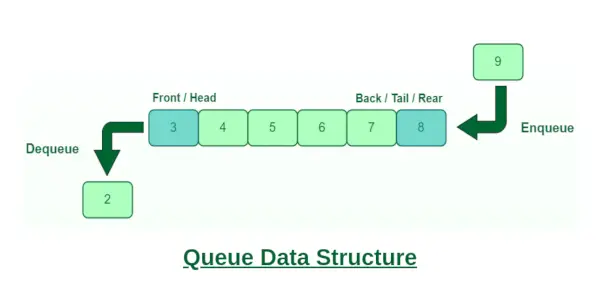
列
キューの特徴:
キューには次のようなさまざまな特性があります。
- キューは FIFO (First In First Out) 構造です。
- キューの最後の要素を削除するには、キュー内の新しい要素の前に挿入されたすべての要素を削除する必要があります。
- キューは、同様のデータ型の要素の順序付きリストです。
キューの用途:
Queue のさまざまなアプリケーションは次のとおりです。
- キューは、Web サイトのトラフィックを処理するために使用されます。
- メディア プレーヤーでプレイリストを維持するのに役立ちます。
- キューは、オペレーティング システムで割り込みを処理するために使用されます。
- これは、プリンター、CPU タスク スケジューリングなどの単一の共有リソースでリクエストを処理するのに役立ちます。
- これは、データの非同期転送に使用されます。パイプ、ファイル IO、ソケット。
- キューは、オペレーティング システムでのジョブのスケジューリングに使用されます。
- ソーシャルメディアでは、複数の写真やビデオをアップロードするためにキューが使用されます。
- 電子メールを送信するには、キュー データ構造が使用されます。
- Web サイトのトラフィックを同時に処理するには、キューが使用されます。
- Windows オペレーティング システムで、複数のアプリケーションを切り替えること。
キューに対して実行される操作:
キューは、先入れ先出し (FIFO) 原理を実装した線形データ構造です。キューに対して実行される一般的な操作をいくつか示します。
- エンキュー : 要素をキューの最後に追加して、新しい要素をキューの最後に追加できます。
- それに応じて : フロント要素は、デキュー操作を実行することでキューから削除でき、キューに追加された最初の要素が効果的に削除されます。
- ピーク : フロント要素は、ピーク操作を使用してキューから削除せずに検査できます。
- 空です : キューが空かどうかを確認するためにチェックを行うことができます。
- サイズ : キュー内の要素の数は、サイズ操作を使用して決定できます。
これらは、キューに対して実行される最も一般的な操作の一部です。使用される具体的な操作とアルゴリズムは、問題の要件と使用されるプログラミング言語に応じて異なる場合があります。キューは、タスクのスケジュール設定、プロセス間の通信の管理などのアプリケーションで一般的に使用されます。
キューの実際のアプリケーション:
- 行列の実例としては、最初に進入した車両が最初に退出する単一車線の一方通行の道路が挙げられます。
- より現実的な例は、チケット窓口の行列で見ることができます。
- 店舗のレジの列も行列の例です。
- エスカレーターに乗る人々
Queue を始めてみませんか?ベスト プラクティスについては、厳選した記事とリストを試してみてください。
- techcodeview.com の練習キューの問題
木:
ツリーは、要素がツリー状の構造に配置された非線形の階層データ構造です。ツリーでは、最上位のノードはルート ノードと呼ばれます。各ノードには何らかのデータが含まれており、データのタイプは任意です。これは、中心ノード、構造ノード、およびエッジを介して接続されるサブノードで構成されます。非線形データ構造であるため、さまざまなツリー データ構造を使用すると、データにすばやく簡単にアクセスできます。ツリーには、ノード、ルート、エッジ、ツリーの高さ、ツリーの次数など、さまざまな用語があります。
木のようなものにはさまざまな種類があります
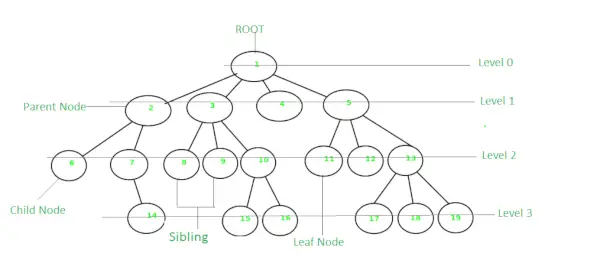
木
木の特徴:
この木には次のようなさまざまな特徴があります。
- ツリーは再帰的データ構造としても知られています。
- ツリーでは、ルートの高さはルート ノードからリーフ ノードまでの最長パスとして定義できます。
- ツリーでは、最上部から任意のノードまでの深さを計算することもできます。ルート ノードの深さは 0 です。
ツリーのアプリケーション:
Tree のさまざまな用途は次のとおりです。
- ヒープは、配列を使用して実装され、優先キューの実装に使用されるツリー データ構造です。
- B-Tree および B+ Tree は、データベースにインデックス付けを実装するために使用されます。
- 構文ツリーは、コンパイラー設計におけるスキャン、解析、コードの生成、および算術式の評価に役立ちます。
- K-D ツリーは、K 次元空間内の点を整理するために使用される空間分割ツリーです。
- スパニング ツリーは、コンピュータ ネットワークのルーターで使用されます。
ツリーに対して実行される操作:
ツリーは、エッジで接続されたノードで構成される非線形データ構造です。ツリーに対して実行される一般的な操作をいくつか示します。
- 挿入 : 新しいノードをツリーに追加して、新しい枝を作成したり、ツリーの高さを高くしたりできます。
- 削除 : 親ノードの参照を更新して現在のノードへの参照を削除することで、ツリーからノードを削除できます。
- 検索 : ルート ノードから開始して、現在のノードの値に基づいて目的のノードが見つかるまでツリーをたどることにより、ツリー内の要素を検索できます。
- トラバーサル : ツリー内の要素は、順序内、前順、後順のトラバースなど、さまざまな方法でトラバースできます。
- 身長 : ツリーの高さは、ルート ノードから最も遠いリーフ ノードまでのエッジの数を数えることによって決定できます。
- 深さ : ノードの深さは、ルート ノードから現在のノードまでのエッジの数を数えることによって決定できます。
- バランスをとる : ツリーの高さが最小限に抑えられ、ノードの分布が可能な限り均一になるように、ツリーのバランスを調整できます。
これらは、ツリーに対して実行される最も一般的な操作の一部です。使用される具体的な操作とアルゴリズムは、問題の要件と使用されるプログラミング言語に応じて異なる場合があります。ツリーは、階層データの検索、並べ替え、保存などのアプリケーションでよく使用されます。
ツリーの実生活への応用:
- 実際には、ツリー データ構造はゲーム開発に役立ちます。
- データベースのインデックス作成にも役立ちます。
- デシジョン ツリーは効率的な機械学習ツールであり、意思決定分析でよく使用されます。データの理解に役立つフローチャートのような構造になっています。
- ドメイン ネーム サーバーもツリー データ構造を使用します。
- ツリーの最も一般的な使用例は、ソーシャル ネットワーキング サイトです。
Tree を始めてみませんか?ベスト プラクティスについては、厳選した記事とリストを試してみてください。
- ツリーインタビューの質問トップ 50
- techcodeview.com の練習ツリー問題
グラフ:
グラフは、頂点 (またはノード) とエッジで構成される非線形データ構造です。これは、ノードのペアを接続する有限の頂点セットとエッジのセットで構成されます。グラフは、最も困難で複雑なプログラミング問題を解決するために使用されます。パス、次数、隣接頂点、接続コンポーネントなど、さまざまな用語があります。
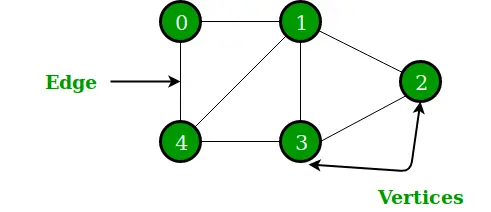
グラフ
グラフの特徴:
グラフには次のようなさまざまな特性があります。
- 頂点から他のすべての頂点までの最大距離が、その頂点の離心率とみなされます。
- 最小の離心率を持つ頂点がグラフの中心点とみなされます。
- すべての頂点からの離心率の最小値が、接続されたグラフの半径とみなされます。
グラフの応用:
グラフのさまざまな用途は次のとおりです。
- グラフは計算の流れを表すために使用されます。
- グラフのモデリングに使用されます。
- オペレーティング システムはリソース割り当てグラフを使用します。
- Web ページがノードを表す World Wide Web でも使用されます。
グラフに対して実行される操作:
グラフは、ノードとエッジで構成される非線形データ構造です。グラフに対して実行される一般的な操作をいくつか示します。
- 頂点を追加します。 新しい頂点をグラフに追加して、新しいノードを表すことができます。
- エッジを追加: 頂点間にエッジを追加して、ノード間の関係を表すことができます。
- 頂点の削除 : 隣接する頂点の参照を更新して現在の頂点への参照を削除することで、頂点をグラフから削除できます。
- エッジの削除 : エッジを削除するには、隣接する頂点の参照を更新して現在のエッジへの参照を削除します。
- 深さ優先検索 (DFS) : 深さ優先の方法で頂点を訪問することにより、深さ優先検索を使用してグラフを横断できます。
- B readth-First Search (BFS): 幅優先の方法で頂点を訪問することにより、幅優先検索を使用してグラフを横断することができます。
- 最短パス: 2 つの頂点間の最短パスは、ダイクストラ アルゴリズムや A* アルゴリズムなどのアルゴリズムを使用して決定できます。
- 接続されたコンポーネント : グラフの接続コンポーネントは、グラフ内の他の頂点には接続されていないが、互いに接続されている頂点のセットを見つけることによって決定できます。
- 周期検出 : グラフ内のサイクルは、深さ優先検索中にバックエッジをチェックすることで検出できます。
これらは、グラフに対して実行される最も一般的な操作の一部です。使用される具体的な操作とアルゴリズムは、問題の要件と使用されるプログラミング言語に応じて異なる場合があります。グラフは、コンピュータ ネットワーク、ソーシャル ネットワーク、ルーティング問題などのアプリケーションでよく使用されます。
グラフの実生活への応用:
- 実際のグラフの最も一般的な例の 1 つは Google マップです。Google マップでは都市が頂点として配置され、それらの頂点を接続するパスがグラフのエッジとして配置されます。
- ソーシャル ネットワークも現実世界のグラフの例の 1 つであり、ネットワーク上のすべての人がノードであり、ネットワーク上のすべての友人関係がグラフの端になります。
- グラフは、物理学や化学で分子を研究するためにも使用されます。
グラフを始めてみませんか?ベスト プラクティスについては、厳選した記事とリストを試してみてください。
ノートパソコンのキーボードのInsertキーはどこにありますか
- グラフデータ構造の概要
- グラフのインタビューでよくある質問トップ 50
- techcodeview.com のグラフ問題の練習
データ構造の利点:
- データの編成とストレージの効率が向上しました。
- データの取得と操作が高速化されます。
- 複雑な問題を解決するためのアルゴリズムの設計を容易にします。
- データの更新と保守のタスクが容易になります。
- データ要素間の関係をより深く理解できます。
データ構造の欠点:
- 計算とメモリのオーバーヘッドが増加します。
- 複雑なデータ構造の設計と実装が難しい。
- スケーラビリティと柔軟性が限られている。
- デバッグとテストの複雑さ。
- 既存のデータ構造を変更するのが難しい。
参照:
データ構造は、さまざまなコンピューター サイエンスの教科書やオンライン リソースで見つけることができます。人気のあるテキストには次のようなものがあります。
- アルゴリズム入門: Thomas H. Cormen、Charles E. Leiserson、Ronald L. Rivest、および Clifford Stein 著。
- Java のデータ構造とアルゴリズム分析、Mark Allen Weiss 著。
- Steven S. Skiena 著のアルゴリズム設計マニュアル。
- Coursera、Udemy、Khan Academy などのオンライン リソースでも、データ構造とアルゴリズムに関するコースが提供されています。
結論
これらは最も広く知られ使用されているデータ構造ですが、コンピューター サイエンスで使用される他の形式のデータ構造もいくつかあります。 ポリシーベースのデータ構造 しかし、どのデータ構造を選択しても、それぞれにメリットとデメリットがあり、それを知らずに間違ったタイプのデータ構造を選択すると、非常にコストがかかる可能性があります。したがって、状況の必要性を理解し、どの種類のデータ構造がその業務に最適であるかを決定することが非常に重要です。