のgrep>Unix/Linux のコマンドは、ファイル内のテキスト パターンの検索と操作に使用される強力なツールです。その名前は、ed (エディター) コマンド g/re/p (正規表現をグローバルに検索し、一致する行を出力する) に由来しており、そのコア機能を反映しています。grep>は、テキスト データの処理における効率性と多用途性により、プログラマー、システム管理者、ユーザーなどに広く使用されています。この記事では、grep>指示。
intを文字列Javaに変換する方法
目次
- Unix/Linux の grep コマンドの構文
- grep コマンドで使用可能なオプション
- Linux での grep コマンドの具体的な例
- 1. 大文字と小文字を区別しない検索
- 2. grepを使用した一致件数の表示
- 3. grepを使用してパターンに一致するファイル名を表示する
- 4. grep を使用してファイル内の単語全体をチェックする
- 5. grepを使用して一致したパターンのみを表示する
- 6. grep -n を使用して出力を表示中に行番号を表示する
- 7. grep を使用したパターン マッチの反転
- 8. grep を使用した文字列で始まる行の一致
- 9. grep を使用した文字列で終わる行の一致
- 10.-eオプションで式を指定
- 11. -f file オプション ファイルからパターンを 1 行に 1 つずつ取得します
- 12. grep を使用してファイルから特定の n 行を印刷する
- 13. ディレクトリ内のパターンを再帰的に検索する
Unix/Linux の grep コマンドの構文
` の基本的な構文 grep`> コマンドは次のとおりです。
grep [options] pattern [files]>
ここ、
[> options> ]>: これらは、の動作を変更するコマンドライン フラグです。grep>。
[> pattern> ]>: 検索する正規表現です。
[> file> ]>: これは、検索するファイルの名前です。複数のファイルを指定して同時に検索できます。
grep コマンドで使用可能なオプション
| オプション | 説明 |
|---|---|
| -c | これは、パターンに一致する行の数のみを出力します。 |
| -h | 一致した行を表示しますが、ファイル名は表示しません。 |
| – 私 | 無視します。大文字と小文字は一致します |
| -l | ファイル名のみのリストを表示します。 |
| -n | 一致した行とその行番号を表示します。 |
| -で | これにより、パターンに一致しないすべての行が出力されます。 |
| -e exp | このオプションで式を指定します。複数回使用できます。 |
| -f ファイル | ファイルからパターンを 1 行に 1 つずつ取得します。 |
| -そして | パターンを拡張正規表現 (ERE) として扱います。 |
| -で | 単語全体と一致する |
| -O | 一致する行の一致する部分のみを、そのような各部分を別の出力行に出力します。 |
| -アン | 検索された行と結果の後の n 行を出力します。 |
| -Bn | 検索された行と結果の n 行前を出力します。 |
| -Cn | 検索された行と結果の前の n 行後を出力します。 |
サンプルコマンド
以下のファイルを入力として考慮します。
cat>geekfile.txt>>
unixは素晴らしいOSです。 unix はベル研究所で開発されました。
オペレーティングシステムを学びます。
Unix Linux どれを選択しますか。
uNix は学ぶのが簡単です。unix はマルチユーザー OS です。unix を学びましょう。unix は強力です。
Linux での grep コマンドの具体的な例
1. 大文字と小文字を区別しない検索
-i オプションを使用すると、指定されたファイル内で大文字と小文字を区別せずに文字列を検索できます。 UNIX、Unix、unix などの単語に一致します。
私のモニターはどのくらいの大きさですか
grep -i 'UNix' geekfile.txt>
出力:

大文字と小文字を区別しない検索
2. grepを使用した一致件数の表示
指定された文字列/パターンに一致する行数を見つけることができます
grep -c 'unix' geekfile.txt>
出力:

試合のカウント数を表示する
3. grepを使用してパターンに一致するファイル名を表示する
指定された文字列/パターンを含むファイルを表示するだけです。
grep -l 'unix' *>
または
grep -l 'unix' f1.txt f2.txt f3.xt f4.txt>
出力:

パターンに一致するファイル名
4. grep を使用してファイル内の単語全体をチェックする
デフォルトでは、grep は、ファイル内の部分文字列として見つかった場合でも、指定された文字列/パターンと一致します。 grep の -w オプションを使用すると、単語全体のみが一致します。
grep -w 'unix' geekfile.txt>
出力:

ファイル内の単語全体をチェックする
5. grepを使用して一致したパターンのみを表示する
デフォルトでは、grep は一致した文字列を含む行全体を表示します。 -o オプションを使用すると、一致した文字列のみを表示するように grep を作成できます。
grep -o 'unix' geekfile.txt>
出力:
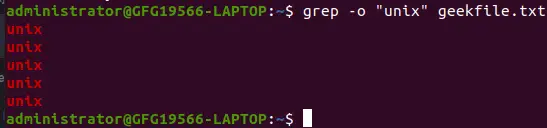
一致したパターンのみを表示する
6. grep -n を使用して出力を表示中に行番号を表示する
行が一致したファイルの行番号を表示します。
grep -n 'unix' geekfile.txt>
出力:

出力の表示中に行番号を表示する
7. grep を使用したパターン マッチの反転
-v オプションを使用すると、指定した検索文字列パターンに一致しない行を表示できます。
grep -v 'unix' geekfile.txt>
出力:

パターンマッチの反転
javascript window.open
8. grep を使用した文字列で始まる行の一致
^ 正規表現パターンは行の先頭を指定します。これを grep で使用すると、指定された文字列またはパターンで始まる行を照合できます。
grep '^unix' geekfile.txt>
出力:

文字列で始まる行のマッチング
9. grep を使用した文字列で終わる行の一致
$ 正規表現パターンは行の終わりを指定します。これを grep で使用すると、指定された文字列またはパターンで終わる行を照合できます。
grep 'os$' geekfile.txt>
10.-eオプションで式を指定
複数回使用可能:
grep –e 'Agarwal' –e 'Aggarwal' –e 'Agrawal' geekfile.txt>
11. -f file オプション ファイルからパターンを 1 行に 1 つずつ取得します
cat pattern.txt>
アガルワル
アガルワル
アグラワル
grep –f pattern.txt geekfile.txt>
12. grep を使用してファイルから特定の n 行を印刷する
-A は検索された行と結果の n 行後を出力し、-B は検索された行と結果の n 行前を出力し、-C は検索された行と結果の前後 n 行を出力します。
構文:
grep -A[NumberOfLines(n)] [search] [file] grep -B[NumberOfLines(n)] [search] [file] grep -C[NumberOfLines(n)] [search] [file]>
例:
grep -A1 learn geekfile.txt>
出力:

ファイルから特定の n 行を印刷します
13. パターンを再帰的に検索します。 D 直説法
-R 指定されたディレクトリで検索されたパターンをすべてのファイルに再帰的に出力します。
構文:
grep -R [Search] [directory]>
例 :
grep -iR geeks /home/geeks>
出力:
./geeks2.txt:Well Hello Geeks ./geeks1.txt:I am a big time geek ---------------------------------- -i to search for a string case insensitively -R to recursively check all the files in the directory.>
結論
この記事では、grep>Linux のコマンド。正規表現を使用してファイル内のパターンやテキストを検索する強力なテキスト検索ツールです。大文字と小文字の区別、一致のカウント、ファイル名のリストなど、さまざまなオプションが提供されます。再帰的な検索、正規表現フラグの使用、出力のカスタマイズ機能により、grep>は、Linux ユーザーがテキスト関連のタスクを効率的に処理するために不可欠なツールです。マスタリングgrep>Linux 環境でテキスト データを操作する能力が強化されます。