BERT、頭字語 トランスフォーマーからの双方向エンコーダー表現用 、オープンソースとしての立場 機械学習フレームワーク ~の領域向けに設計された 自然言語処理 (NLP) 。 2018 年に誕生したこのフレームワークは、Google AI Language の研究者によって作成されました。この記事の目的は、 BERT のアーキテクチャ、動作、およびアプリケーション 。
バートとは何ですか?
BERT (トランスフォーマーからの双方向エンコーダー表現) トランスフォーマーベースのニューラルネットワークを活用して、人間のような言語を理解して生成します。 BERT はエンコーダのみのアーキテクチャを採用しています。原作では 変圧器のアーキテクチャ 、エンコーダ モジュールとデコーダ モジュールの両方があります。 BERT でエンコーダのみのアーキテクチャを使用するという決定は、出力シーケンスを生成することよりも入力シーケンスを理解することに主な重点を置くことを示唆しています。
BERT の双方向アプローチ
従来の言語モデルは、テキストを左から右、または右から左に順番に処理します。この方法では、モデルの認識がターゲット単語の直前のコンテキストに限定されます。 BERT は、テキストを順番に分析するのではなく、文内の単語の左と右の両方のコンテキストを考慮する双方向のアプローチを使用し、文内のすべての単語を同時に調べます。
例: 銀行は川の_______沿いにあります。
一方向モデルでは、空白の理解は先行する単語に大きく依存し、モデルは銀行が金融機関を指すのか、それとも川の側を指すのかを識別するのに苦労する可能性があります。
BERT は双方向であるため、左のコンテキスト (川の堤防が位置している) と右のコンテキスト (川) の両方を同時に考慮し、より微妙な理解を可能にします。それは、欠落している単語が銀行の地理的位置に関連している可能性が高いことを理解しており、双方向のアプローチがもたらす文脈の豊かさを示しています。
事前トレーニングと微調整
BERT モデルは 2 段階のプロセスを経ます。
- 文脈に応じた埋め込みを学習するために、大量のラベルのないテキストを事前トレーニングします。
- 特定のラベル付きデータを微調整する NLP タスク。
大規模データの事前トレーニング
- BERT は、大量のラベルなしテキスト データに対して事前トレーニングされています。モデルは、文内の周囲のコンテキストを考慮した単語の表現であるコンテキスト埋め込みを学習します。
- BERT は、さまざまな教師なし事前トレーニング タスクに取り組みます。たとえば、文内の欠落している単語を予測したり (マスク言語モデルまたは MLM タスク)、2 つの文間の関係を理解したり、ペアの次の文を予測したりすることを学習する場合があります。
ラベル付きデータの微調整
- 事前トレーニング段階の後、コンテキスト埋め込みを備えた BERT モデルは、特定の自然言語処理 (NLP) タスクに合わせて微調整されます。このステップでは、一般的な言語理解を特定のタスクのニュアンスに適応させることで、モデルをよりターゲットを絞ったアプリケーションに合わせて調整します。
- BERT は、対象の下流タスクに固有のラベル付きデータを使用して微調整されます。これらのタスクには、感情分析、質問への回答、 固有表現認識 、またはその他の NLP アプリケーション。モデルのパラメーターは、当面のタスクの特定の要件に合わせてパフォーマンスを最適化するように調整されます。
BERT の統合アーキテクチャにより、最小限の変更でさまざまなダウンストリーム タスクに適応できるため、多用途で非常に効果的なツールになります。 自然言語理解 そして加工。
BERT はどのように機能するのでしょうか?
BERT は言語モデルを生成するように設計されているため、エンコーダー メカニズムのみが使用されます。トークンのシーケンスが Transformer エンコーダーに供給されます。これらのトークンはまずベクトルに埋め込まれ、次にニューラル ネットワークで処理されます。出力はベクトルのシーケンスであり、それぞれが入力トークンに対応し、コンテキスト化された表現を提供します。
言語モデルをトレーニングする場合、予測目標を定義するのは困難です。多くのモデルはシーケンス内の次の単語を予測しますが、これは方向性のあるアプローチであり、コンテキスト学習が制限される可能性があります。 BERT は、次の 2 つの革新的なトレーニング戦略でこの課題に対処します。
- マスクされた言語モデル (MLM)
- 次の文の予測 (NSP)
1. マスクされた言語モデル (MLM)
BERT の事前トレーニング プロセスでは、各入力シーケンス内の単語の一部がマスクされ、周囲の単語によって提供されるコンテキストに基づいてこれらのマスクされた単語の元の値を予測するようにモデルがトレーニングされます。
簡単な言葉で、
- マスキング単語: BERT が文から学習する前に、一部の単語 (約 15%) が隠され、[MASK] などの特殊な記号に置き換えられます。
- 隠された単語を推測する: BERT の仕事は、周囲の単語を調べて、これらの隠された単語が何であるかを理解することです。これは、いくつかの単語が欠けている場所を推測するゲームのようなもので、BERT が空白を埋めようとします。
- BERT が学習する方法:
- BERT は、これらの推測を行うために、学習システムの上に特別なレイヤーを追加します。次に、その推測が実際の隠された単語にどの程度近いかをチェックします。
- これは、推測を確率に変換することによって行われ、「私はこの単語は X だと思う、そして私はそれについてこれくらい確信している」と言います。
- 隠された単語への特別な注意
- BERT のトレーニング中の主な焦点は、これらの隠された単語を正しく理解することです。隠されていない単語を予測することにはあまり関心がありません。
- これは、本当の課題は欠落している部分を見つけ出すことであり、この戦略は BERT が単語の意味と文脈を理解するのに非常に優れているためです。
技術的な用語で言えば、
- BERT は、エンコーダーからの出力の上に分類レイヤーを追加します。このレイヤーは、マスクされた単語を予測するために重要です。
- 分類層からの出力ベクトルは埋め込み行列で乗算され、語彙次元に変換されます。このステップは、予測された表現を語彙空間に合わせるのに役立ちます。
- 語彙内の各単語の確率は、次の式を使用して計算されます。 SoftMax アクティベーション関数 。このステップでは、マスクされた位置ごとに語彙全体にわたる確率分布を生成します。
- トレーニング中に使用される損失関数は、マスクされた値の予測のみを考慮します。モデルは、その予測とマスクされた単語の実際の値との間の偏差に対してペナルティを受けます。
- モデルは方向性モデルよりも収束が遅くなります。これは、トレーニング中に BERT がマスクされた値の予測のみに関心を持ち、マスクされていない単語の予測を無視するためです。この戦略によって達成されるコンテキスト認識の向上により、収束の遅さが補われます。
2. 次の文の予測 (NSP)
BERT は、2 番目の文が最初の文に接続されているかどうかを予測します。これは、分類層を使用して [CLS] トークンの出力を 2×1 形状のベクトルに変換し、SoftMax を使用して 2 番目の文が最初の文に続くかどうかの確率を計算することによって行われます。
- トレーニング プロセスでは、BERT は文のペア間の関係を理解し、元の文書の最初の文の後に 2 番目の文が続くかどうかを予測します。
- 入力ペアの 50% には、元の文書の後続の文として 2 番目の文が含まれ、残りの 50% にはランダムに選択された文が含まれます。
- モデルが接続された文のペアと切断された文のペアを区別できるようにします。入力はモデルに入力される前に処理されます。
- 最初の文の先頭に [CLS] トークンが挿入され、各文の末尾に [SEP] トークンが追加されます。
- 各トークンには、文Aまたは文Bを示す文埋め込みが付加される。
- 位置埋め込みは、シーケンス内の各トークンの位置を示します。
- BERT は、2 番目の文が最初の文に接続されているかどうかを予測します。これは、分類層を使用して [CLS] トークンの出力を 2×1 形状のベクトルに変換し、SoftMax を使用して 2 番目の文が最初の文に続くかどうかの確率を計算することによって行われます。
BERT モデルのトレーニング中に、マスクされた LM と次の文の予測が一緒にトレーニングされます。このモデルは、マスクされた LM と次文予測の結合損失関数を最小限に抑え、文内のコンテキストや文間の関係を理解する機能が強化された堅牢な言語モデルを実現することを目的としています。
Masked LM と次文予測を一緒にトレーニングする理由は何ですか?
Masked LM は、BERT が文内のコンテキストを理解し、 次の文の予測 BERT が文のペア間の接続や関係を把握するのに役立ちます。したがって、両方の戦略を一緒にトレーニングすることで、BERT は言語を幅広く包括的に理解し、文内の詳細と文の間の流れの両方を確実に把握できるようになります。
BERT アーキテクチャ
BERT のアーキテクチャは、トランス モデルによく似た多層双方向トランス エンコーダです。トランスフォーマー アーキテクチャは、以下を使用するエンコーダー/デコーダー ネットワークです。 自意識 エンコーダ側では注意が必要で、デコーダ側では注意が必要です。
- バートベース1つあります エンコーダースタックの 2 つのレイヤー BERTの間大きいもっている エンコーダースタックの 24 レイヤー 。これらは、元の論文で説明されている Transformer アーキテクチャを超えています ( 6つのエンコーダーレイヤー )。
- BERT アーキテクチャ (BASE および LARGE) には、より大きなフィードフォワード ネットワーク (それぞれ 768 および 1024 の隠れユニット) もあります。 より多くの注目のヘッド (それぞれ 12 と 16) 元の論文で提案されている Transformer アーキテクチャよりも優れています。を含む 512 個の隠しユニットと 8 個の注目ヘッド 。
- バートベースBERT には 1 億 1000 万のパラメータが含まれています大きい3億4000万のパラメータがあります。

BERT BASE および BERT LARGE アーキテクチャ。
このモデルは、 CLS 最初にトークンを入力として入力し、その後に一連の単語を入力として入力します。ここで CLS は分類トークンです。次に、入力を上の層に渡します。各レイヤーが適用されます 自意識 そして結果をフィードフォワード ネットワークに渡し、その後次のエンコーダに渡します。モデルは隠れたサイズのベクトルを出力します ( 768 BERT BASE用)。このモデルから分類子を出力したい場合は、CLS トークンに対応する出力を取得できます。
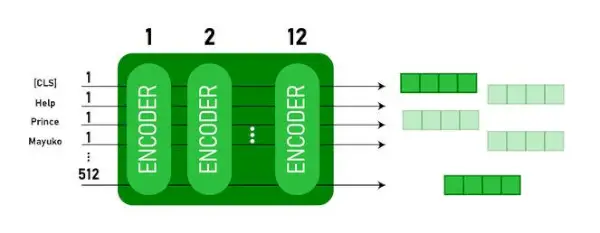
埋め込みとしての BERT 出力
このトレーニングされたベクトルを使用して、分類、翻訳などの多くのタスクを実行できます。たとえば、論文は単一のレイヤーを使用するだけで優れた結果を達成します。 ニューラルネットワーク 分類タスクの BERT モデルについて。
NLP で BERT モデルを使用するにはどうすればよいですか?
BERT は、次のようなさまざまな自然言語処理 (NLP) タスクに使用できます。
1. 分類タスク
- BERT は次のような分類タスクに使用できます。 感情分析 の目標は、テキストをさまざまなカテゴリ (ポジティブ/ネガティブ/ニュートラル) に分類することです。BERT は、[CLS] トークンの Transformer 出力の上部に分類レイヤーを追加することで使用できます。
- [CLS] トークンは、入力シーケンス全体からの集約された情報を表します。このプールされた表現は、特定のタスクの予測を行うための分類レイヤーの入力として使用できます。
2. 質疑応答
- 質問応答タスクでは、モデルが特定のテキスト シーケンス内で回答を見つけてマークする必要があるため、BERT をこの目的のためにトレーニングできます。
- BERT は、応答の始まりと終わりを示す 2 つの追加ベクトルを学習することによって、質問応答用にトレーニングされます。トレーニング中、モデルには質問と対応するパッセージが提供され、パッセージ内の回答の開始位置と終了位置を予測する方法を学習します。
3. 固有表現認識 (NER)
- BERT は NER に利用できます。NER の目的は、テキスト シーケンス内のエンティティ (人、組織、日付など) を識別して分類することです。
- BERT ベースの NER モデルは、Transformer から各トークンの出力ベクトルを取得し、それを分類層に供給することによってトレーニングされます。この層は、各トークンの名前付きエンティティ ラベルを予測し、それが表すエンティティの種類を示します。
BERT を使用してテキストをトークン化し、エンコードする方法は?
BERT を使用してテキストをトークン化してエンコードするには、Python の「transformer」ライブラリを使用します。
変圧器をインストールするコマンド:
!pip install transformers>
- 次を使用して、事前トレーニングされた BERT トークン化を大文字と小文字の語彙でロードします。 BertTokenizer.from_pretrained(bert-base-cased) 。
- tokenizer.encode(テキスト) 入力テキストをトークン化し、一連のトークン ID に変換します。
- print(トークンID:,エンコーディング) エンコード後に取得したトークン ID を出力します。
- tokenizer.convert_ids_to_tokens(エンコーディング) トークン ID を対応するトークンに変換します。
- print(トークン:, トークン) トークンIDを変換した後に取得したトークンを出力します。
Python3
from> transformers>import> BertTokenizer> # Load pre-trained BERT tokenizer> tokenizer>=> BertTokenizer.from_pretrained(>'bert-base-cased'>)> # Input text> text>=> 'ChatGPT is a language model developed by OpenAI, based on the GPT (Generative Pre-trained Transformer) architecture. '> # Tokenize and encode the text> encoding>=> tokenizer.encode(text)> # Print the token IDs> print>(>'Token IDs:'>, encoding)> # Convert token IDs back to tokens> tokens>=> tokenizer.convert_ids_to_tokens(encoding)> # Print the corresponding tokens> print>(>'Tokens:'>, tokens)> |
>
>
出力:
Token IDs: [101, 24705, 1204, 17095, 1942, 1110, 170, 1846, 2235, 1872, 1118, 3353, 1592, 2240, 117, 1359, 1113, 1103, 15175, 1942, 113, 9066, 15306, 11689, 118, 3972, 13809, 23763, 114, 4220, 119, 102] Tokens: ['[CLS]', 'Cha', '##t', '##GP', '##T', 'is', 'a', 'language', 'model', 'developed', 'by', 'Open', '##A', '##I', ',', 'based', 'on', 'the', 'GP', '##T', '(', 'Gene', '##rative', 'Pre', '-', 'trained', 'Trans', '##former', ')', 'architecture', '.', '[SEP]']> の トークナイザー.エンコード メソッドは特別なものを追加します [CLS] – 分類 そして [SEP] – セパレータ エンコードされたシーケンスの最初と最後にあるトークン。
BERTの応用
BERT は次の目的で使用されます。
- テキスト表現: BERT は、文内の単語の埋め込みまたは表現を生成するために使用されます。
- 固有表現認識 (NER) : BERT は、特定のテキスト内の人名、組織名、場所などのエンティティを識別することを目的とする固有表現認識タスク向けに微調整できます。
- テキスト分類: BERT は、感情分析、スパム検出、トピック分類などのテキスト分類タスクに広く使用されています。テキストデータのコンテキストを理解して分類する際に優れたパフォーマンスを発揮します。
- 質問応答システム: BERT は質問応答システムに適用されており、質問のコンテキストを理解して関連する回答を提供するようにモデルがトレーニングされています。これは、読解などのタスクに特に役立ちます。
- 機械翻訳: BERT のコンテキスト埋め込みは、機械翻訳システムの改善に活用できます。このモデルは、正確な翻訳に重要な言語のニュアンスを捉えます。
- テキストの要約: BERT は、抽象的なテキストの要約に使用できます。このモデルでは、コンテキストとセマンティクスを理解することで、長いテキストの簡潔で意味のある要約が生成されます。
- 会話型 AI: BERT は、チャットボット、仮想アシスタント、対話システムなどの会話型 AI システムの構築に採用されています。コンテキストを把握する能力により、自然言語応答を理解して生成するのに効果的です。
- 意味上の類似性: BERT 埋め込みを使用して、文またはドキュメント間の意味上の類似性を測定できます。これは、重複の検出、言い換えの識別、情報の検索などのタスクで役立ちます。
BERT vs GPT
BERT と GPT の違いは次のとおりです。
| バート | GPT | |
|---|---|---|
| 建築 | BERT は双方向表現学習用に設計されています。マスクされた言語モデル目標を使用し、左右のコンテキストに基づいて文内の欠落単語を予測します。 | 一方、GPT は生成言語モデリング用に設計されています。一方向自己回帰アプローチを利用して、前のコンテキストを考慮して文内の次の単語を予測します。 |
| トレーニング前の目標 | BERT は、マスクされた言語モデルの目標と次の文の予測を使用して事前トレーニングされます。双方向のコンテキストをキャプチャし、文内の単語間の関係を理解することに重点を置いています。 | GPT は、文内の次の単語を予測するように事前トレーニングされており、これにより、モデルが言語の一貫した表現を学習し、文脈に関連したシーケンスを生成することが促進されます。 |
| コンテキストの理解 | BERT は、テキスト分類、固有表現認識、質問応答など、文内のコンテキストや関係性を深く理解する必要があるタスクに効果的です。 | GPT は、一貫した文脈に関連したテキストの生成に優れています。クリエイティブなタスク、対話システム、自然言語シーケンスの生成が必要なタスクでよく使用されます。 |
| タスクの種類とユースケース
| テキスト分類、固有表現認識、感情分析、質問応答などのタスクでよく使用されます。 | テキスト生成、対話システム、要約、クリエイティブライティングなどのタスクに適用されます。 |
| 微調整と少数回の学習 | BERT は多くの場合、ラベル付きデータを使用して特定の下流タスクで微調整され、事前トレーニングされた表現を当面のタスクに適合させます。 | GPT は、少数ショット学習を実行するように設計されており、最小限のタスク固有のトレーニング データで新しいタスクに一般化できます。 |
以下もチェックしてください:
- BERT を使用した感情分類
- BERT を使用して Word 埋め込みを生成するにはどうすればよいですか?
- NLP でのテキスト自動補完用の BART モデル
- BERT を使用した有害なコメントの分類
- BERT を使用した次の文の予測
よくある質問 (FAQ)
Q. BERT は何に使用されますか?
BERT は、テキスト表現、固有表現認識、テキスト分類、Q&A システム、機械翻訳、テキスト要約などの NLP タスクを実行するために使用されます。
Q. BERT モデルの利点は何ですか?
BERT 言語モデルは、複数の言語で広範な事前トレーニングが行われていることで際立っており、他のモデルと比較して幅広い言語をカバーします。このため、BERT は、さまざまな言語にわたって堅牢な文脈表現と意味理解を提供し、多言語アプリケーションでの汎用性を高めるため、非英語ベースのプロジェクトにとって特に有利です。
Q. BERT は感情分析にどのように機能しますか?
BERT は、双方向表現学習を活用して、特定のテキスト内の文脈上のニュアンス、意味論的な意味、構文構造を捕捉することにより、感情分析に優れています。これにより、BERT は単語間の関係を考慮して文内で表現された感情を理解できるようになり、非常に効果的な感情分析結果が得られます。
アメリカの都市は何ですか
Q. Google は BERT をベースにしていますか?
バート そして ランクブレイン は、クエリと Web ページのコンテンツを処理して理解を深め、検索結果を改善するための Google の検索アルゴリズムのコンポーネントです。